

作者: 胡佳佳 彭炜明 柯永红 ;转自:公众号 DH数字人文
基础设施

胡佳佳 / 北京师范大学民俗典籍文字研究中心
彭炜明 / 北京师范大学人工智能学院
柯永红 / 北京师范大学中国文字整理与规范研究中心
———————————–
摘要: 历代碑刻数字化研究平台的目的是提供一个集历代碑刻资源的搜集、整理、加工、保存、检索为一体的计算机网络支持环境,并在此基础上针对碑刻的各项研究开发相关的应用功能,其首项任务就是辅助历代碑刻实用字形的采集与整理研究。
关键词: 碑刻 数字化 实用汉字整理 字位
————————————
一、研究背景
历代碑刻数字化研究平台是应北京师范大学民俗典籍文字研究中心和中国文字整理与规范研究中心系列重大项目“近世碑刻数字化典藏及属性描述”的研究需求构建起来的。其目的是要提供一个能够统一搜集、整理、加工、保存、检索碑刻资源的计算机网络支持环境,并在此基础上针对历代碑刻的各项研究开发相关的应用功能,首项任务是辅助碑刻实用字形的采集与整理研究。
传统的碑刻研究主要存在以下困难:(1)目前我国的碑刻实体分散保存在全国各地的文物保护单位中,使用上并不很方便。(2)碑刻拓片资料的出版没有统一协调的管理,处于比较散乱的状态,研究者往往要花费大量的时间来搜集整理。(3)缺乏对碑刻属性与释文的整理,造成查检上的麻烦。随着计算机数据处理和存储能力的不断增强,网络环境不断完善,采用数字化手段进行碑刻典藏,可以有效地实现碑刻资源的共享与传播,方便研究者进行碑刻及其释文的检索与应用。
国内较为知名的大型碑刻数字化系统主要有两家:一是中国国家图书馆的特色资源“碑帖菁华”中文拓片资源库(http://read.nlc.cn/allSearch/searchList?searchType=34&showType=1&pageNo=1),以馆藏的历代甲骨、青铜器、石刻等类拓片23万余件为基础建设,现有元数据2.5万余条,影像3.1万余幅。以刻立石年月排序,提供拓片的“题名”“责任者”“年代”“出土地点”“主题词”和“索书号”检索以及上述条件限定组合的高级检索;使用者可通过计算机网络查询浏览所需拓片的扫描件与元数据(拓片以上属性的描述)。二是北京书同文数字化技术有限公司的《中国历代石刻史料汇编》全文检索版(分单机版和网络版:https://www.unihan.com.cn/books/jinshi/ldsk),辑录一万五千余篇石刻文献,并附有历代金石学家撰写的考释文字,总计约1,150万字。可以进行碑刻的三级纲目浏览(书—年代—碑名)与释文的全文检索。
尽管目前的碑刻数字化系统都基本实现了拓片的典藏与检索功能,但还存在一些缺憾:(1)没有对碑刻进行详细的属性描述,碑刻属性的设置越详细,描述越清楚,越便于研究者从不同的方面更快更准确地搜集到所需要的资源;(2)欠缺扩展性与开放性,用户很难对其底层资源库进行扩充,因而无法实现真正的资源共享;(3)仅仅提供了检索工具,没有针对碑刻研究的不同方面提供与之相适应的平台。
有鉴于此,历代碑刻数字化典藏与应用平台拟将初步实现以下四个功能:(1)碑刻拓片的数字化典藏与管理:提供接口与规范,让各系列项目组可以将自己需要收藏的碑刻拓片扫描件置于平台的统一管理之下,实现真正的资源共享。(2)碑刻属性的详细描述与基于属性的碑刻检索:提供对碑刻多元属性(如自然属性、文物属性、文献属性、文字属性、文化属性)的界定,从而可以根据不同的研究目标进行快速准确的碑刻检索。(3)碑刻释文的录入与基于释文的全文检索:提供接口与规范,让各系列项目组可以进行碑刻拓片对应释文的录入,并据此实现碑刻内容的全文检索。(4)碑刻实用字形的搜集整理与检索统计:基于碑刻字形研究需求所特别开发的功能,可以进行碑刻字形的切分,字样、字位和字种的归纳,从而实现对碑刻实用字形的检索与统计。
二、平台的功能设计
历代碑刻数字化研究平台的功能实际包含两个方面:碑刻资源的数字化典藏以及基于这些数字化资源的检索研究。碑刻资源的数字化典藏指的是提供录入界面,将碑刻拓片、释文文本、字形图片以及碑刻与字形的各项属性纳入数据库的统一管理之下。图1是碑刻资源数字化存储的逻辑数据结构。其中,扫描的拓片、录入的释文与切分出的字形图片以三级目录的形式存放:第一层为碑刻的朝代,第二层为选取碑刻拓片的著录书,第三层为碑刻拓片在著录书中的分册。在三级目录下,以碑刻拓片为单位,存放其扫描件、释文文本与切分出的字形图片文件夹,一律采用拓片所在著录书中的页码作为文件(夹)名(如果一页中有多个拓片,则在页码后加“_序号”)。拓片一律采用灰度扫描,分辨率设为300DPI,角度正中,边缘整齐,存储为JPG格式;释文一律存储为UTF-8编码的TXT文本格式,一列释文为一行,不计空格,单个模糊的字采用符号#代替,大段连续模糊的字则忽略;切分出的字形图片以其所在拓片中的“列_行”来命名,统一存放在与扫描件同名的子文件夹下。同时通过多元的属性结构从不同层面对碑刻进行描述,如图2所示。
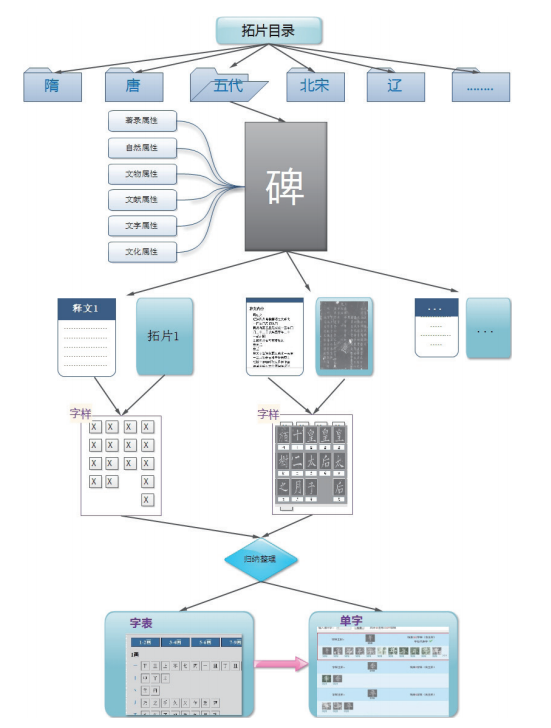
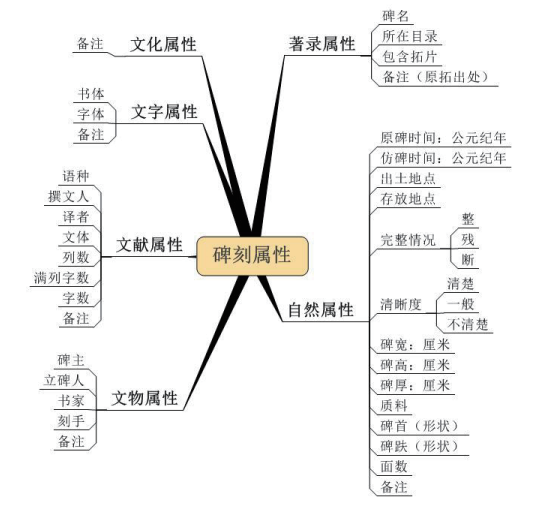
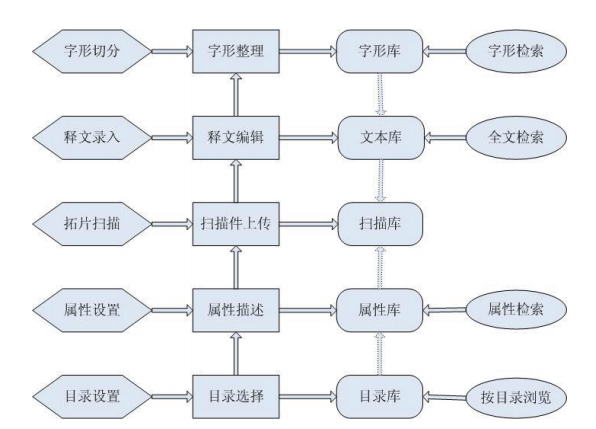
图3是碑刻资源数字化典藏的工作流程,主要包括5个环节:(1)设置碑刻资源的存储与访问的途径;(2)碑刻拓片的扫描与存放;(3)碑刻释文的录入与编辑;(4)碑刻属性的设置与描述;(5)碑刻字形的切分与整理。其中,碑刻字形的切分与整理又需要完成以下4个任务:①碑刻拓片中单个字形图片的切分与存取;②建立字形图片与所属碑刻的联系,以便利用碑刻各项属性(如年代、字体、书体、文化层次……)进行字形的分类研究,如汉字断代描写、汉字书体学、汉字文化学……;③建立字形图片与拓片释文的一一对应关系,以便通过计算机的文本检索找到某字(包括同一字种下的异写字与异构字)在碑刻中出现的所有字形;④以字种为单位(即根据记词职能)对字形图片进行字位和字样的归纳。
三、碑刻资源数字化典藏功能的实现
历代碑刻数字化研究平台中的典藏功能必须以注册的用户名和密码登录,才能访问。
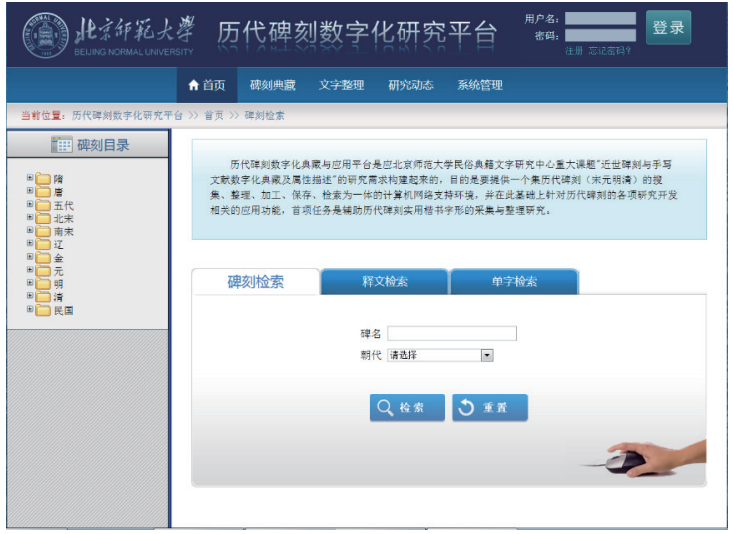
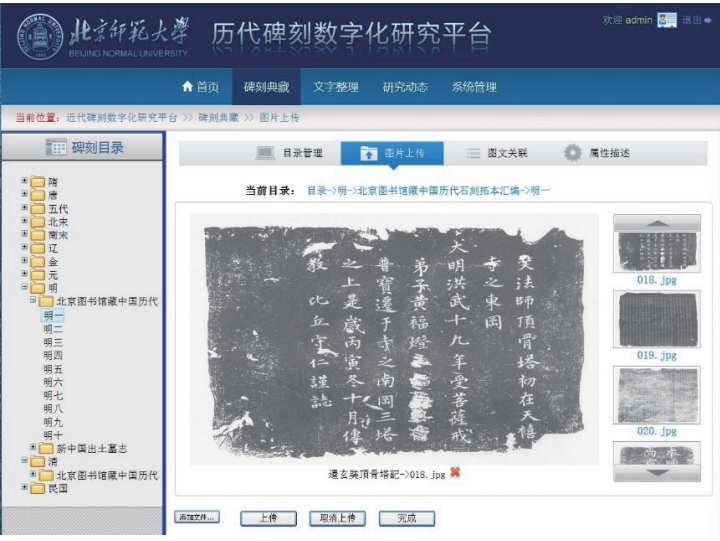
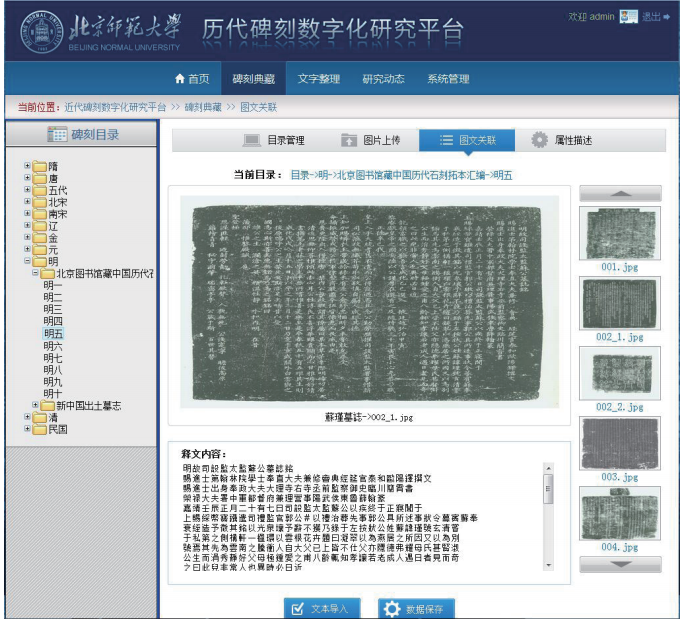
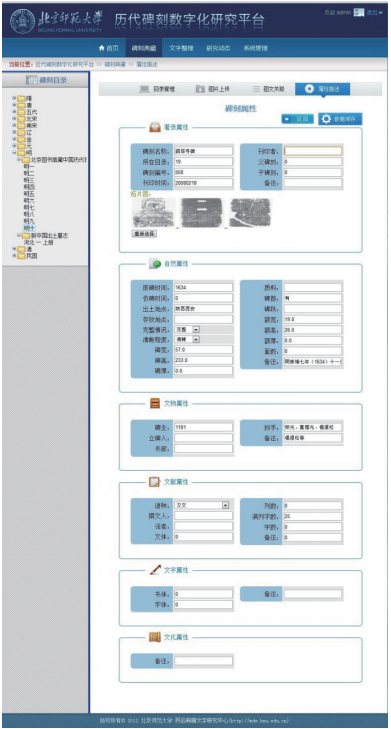
碑刻资源的数字化典藏工作是从目录管理开始的。所有的碑刻拓片、释文与切分出来的字形图片都是按照时代及著录书存放在相应的目录下,如图4所示,从中还可以看出每个目录下已有的碑刻拓片与释文数。有了目录后,就可以把碑刻拓片的扫描图上传到平台上,如图5所示。第三步就是录入每个拓片的释文,做到图文关联,如图6所示。最后还要对每块碑刻进行相关的属性描述,如图7所示。
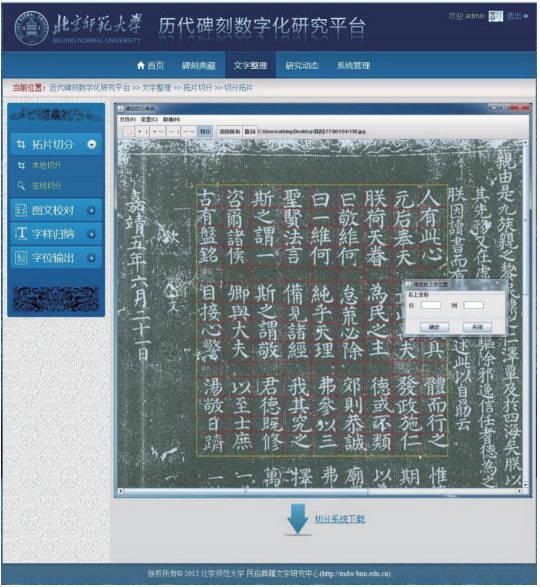
历代碑刻数字化研究平台中的字形搜集与整理工作,首先要从碑刻拓片中切分出单个的字形图片。如图8所示,为了提高图片切分与命名的工作效率所开发的碑刻拓片字形切分工具。首先选定切分区域(黄色框),用横线和竖线将字形划开,选择切分按钮,填入右上角第一个字的行列坐标,然后确定,程序就会自动命名切分出的字形图片,并保存在与拓片同名的文件夹中。
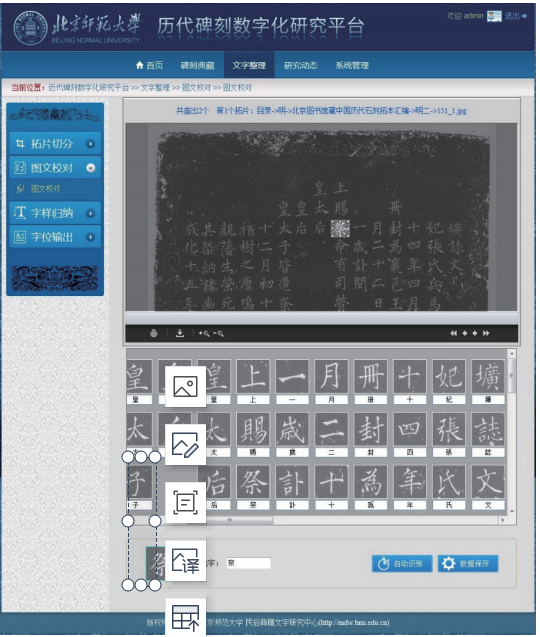
字形图片与碑刻拓片的隶属关系以及与拓片释文的一一对应关系是通过字形图片的存放路径与命名建立起来的。从同一碑刻拓片中切分出的字形图片被存放在以该拓片编号命名的文件夹中,并与该拓片扫描件和释文文本置于相同的访问路径下,从而建立了字形图片与拓片的隶属关系。切分出的字形图片统一以其在该拓片中的“列数_行数”命名,从而与拓片释文中相同位置的字符建立了一一对应关系。如图9所示,页面上部是碑刻拓片的扫描图,下部是切好的字图,按照原文中的顺序排列。每个字图下面还有对应的释文文字。点击其中一个图片,会在底部显示图片在原图中的位置,同时在上部的拓片图中定位这个字,以方便图片与文字的校对。
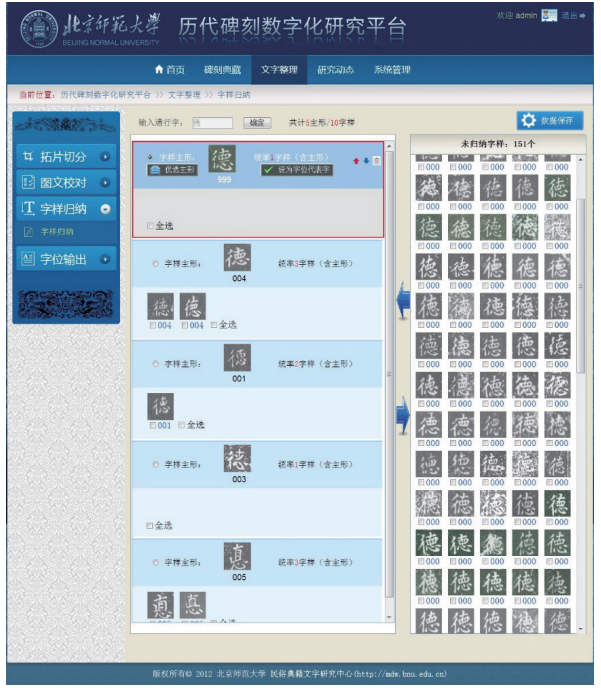
图文校对完成后就可以进入字样归纳工作。从实用文本中收集字形,最重要的工作就是认同别异。字形是指文字在文本中的自然存在状态。严格说来,手写文本中不存在两个完全一样的字形。把没有区别意义的字形归纳在一起,叫做汉字的认同。对共时汉字的认同,有三个层次[2]:(1)字样的认同:在同一种形制下,记录同一个词,构形、构意相同,写法也相同的字,称作一个字样。字样不计风格、不计小、不计运笔和结体的特点,都可以加以认同,归纳到一起。(2)字位的认同:在同一体制下,记录同一个词,构形、构意相同,仅仅是写法不同的字样,称作异写字,异写字认同后,归纳到一起,称为一个字位。(3)字种的认同:形体结构不同而音义都相同、记录同一个词、在任何环境下都可以互相置换的字,称作异构字。异构字聚合在一起,称为一个字种。
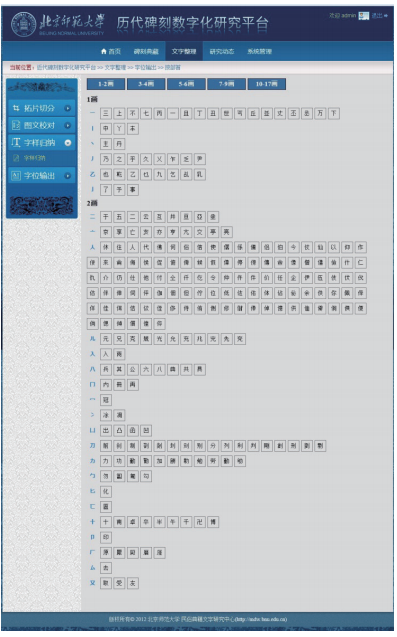
图10是历代碑刻数字化研究平台存储的碑刻释文中所出现的实用字(字种)表,按部首笔画排列。点击其中任意一个,就进入该字的字样归纳界面,如图11所示。页面右侧是未归纳的字样;左侧是已经归纳的字样。用户可以选择其中一个形体作为字样的主形,从而将其他字样与其认同。通过字样主形的比较,可以区分出异写字与异构字。
四、碑刻资源数字化检索功能的实现
历代碑刻数字化研究平台首页,如图12所示,提供用户四种访问碑刻数字化资源的方式:(1)按朝代和著录书目录逐个浏览典藏的碑刻属性、拓片和释文;(2)基于属性描述的碑刻检索(原则上平台里任何关于碑刻的属性描述都可以作为检索项,但考虑到平台设计的简洁性与易用性,仅在首页上提供关于碑刻名称与时代的属性检索);(3)基于碑刻内容的释文检索;(4)基于碑刻字形三重归纳整理的单字检索。
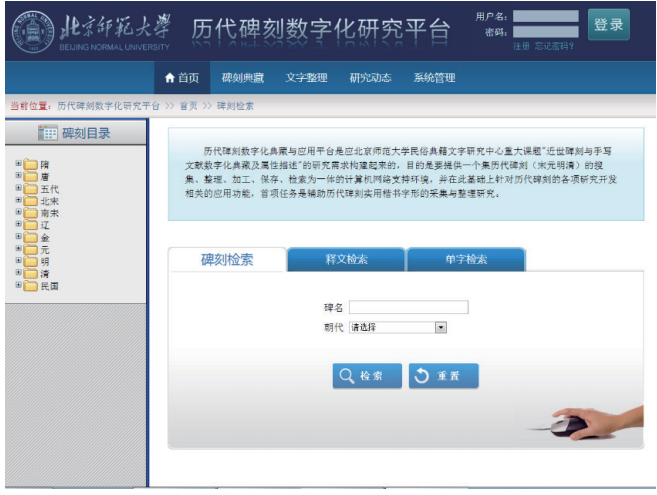
在碑刻检索中,可以检索题名里含有指定字符串的碑刻。检索结果是如图13所示的符合条件的碑刻列表。点击碑刻名称,可以看到关于原碑的各种属性;点击查看,可以看到相应碑刻拓片的扫描图及释文。
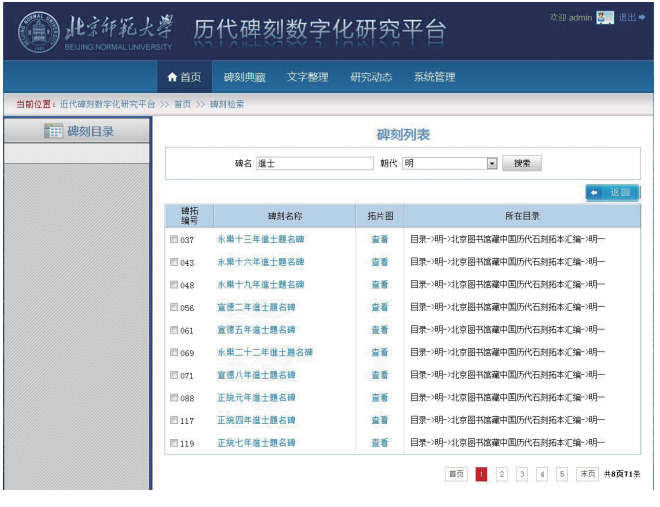
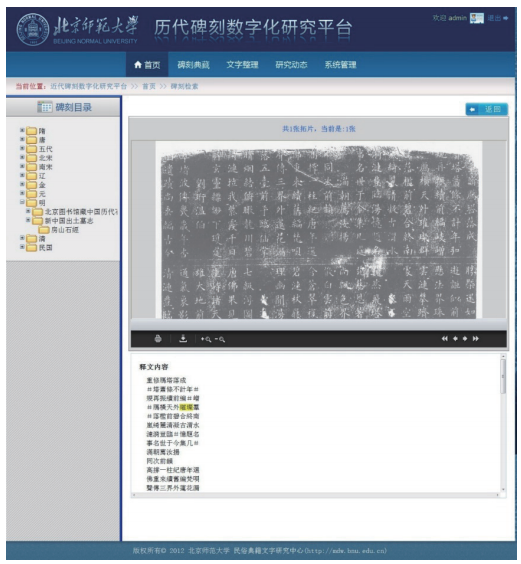
在释文检索中,可以检索拓片释文里含有指定字符串的碑刻。检索结果是如图13所示的符合条件的碑刻列表。点击碑刻名称,可以看到关于原碑的各种属性;点击查看,可以看到相应碑刻拓片的扫描图片以及拓片的释文,同时在释文里用高亮显示出了要检索的字符串,如图14。
在单字检索中,可以检索碑刻拓片里出现的同一个字中的不同字样。如检索“明”字,检索结果如图15所示,列出平台中所有切分出来的“明”字图片,可以看到共有142个字样,可以归纳为3个字位:“明、眀、朙”,每个字位有一个字样主形作为代表。

结 语
历代碑刻数字化研究平台的整体框架分为用户服务、后台、信息层三层,如图16所示。用户服务层提供了研究和应用的各种功能;后台是管理和维护的功能;信息层则是系统各类数据的集合。
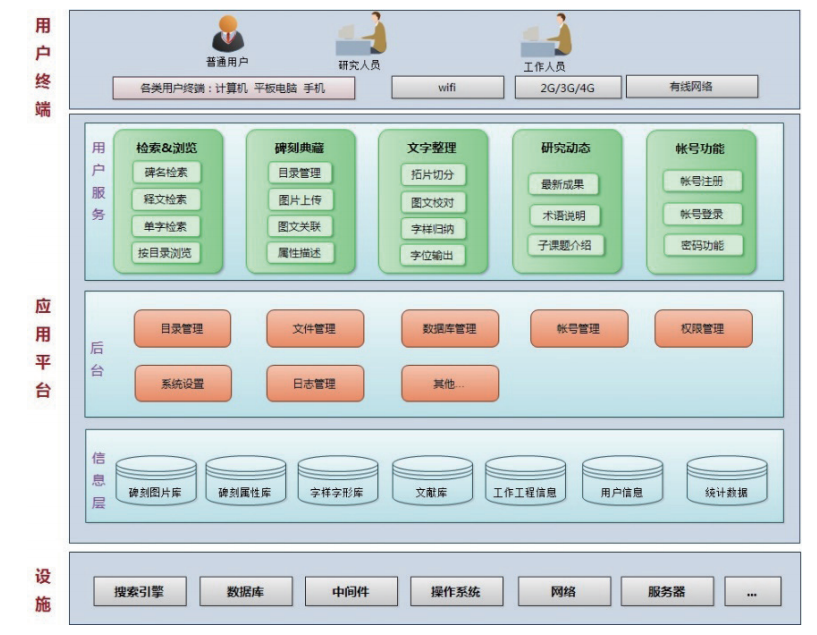
信息层主要包括五类碑刻数据:目录库、属性库、拓片库、文本库与字形库。此外,考虑到该平台作为网络环境下的多用户系统,需要采用基于角色的访问控制方法,通过将访问权限与角色关联、角色与用户关联,实现用户与访问权限的逻辑分离,从而进行复杂灵活的用户权限管理。
历代碑刻数字化研究平台的建设是一项艰巨、复杂、细致的工作,需要循序渐进,不断完善。为了满足项目的研究需求,我们于2007年开始组织开发了第一版的“历代碑刻数字化研究平台”。随着研究工作的深入和信息技术的不断进步,于2012年开始了第二版平台的设计与开发,也就是本文所介绍的平台,目前平台包括碑刻拓片6,600张,字形图22.5万张。现在正在进行第三版平台的改版设计与开发,准备将平台中的实用字形与已有的汉字全息资源应用系统(https://qxk.bnu.edu.cn/#/)对接。也欢迎有意愿开发碑刻资源及应用的相关研究单位与我们开展合作。
———————————————————————————————————————————————————————————————————
Research Platform of Digitized Ancient Chinese Stele Inscriptions
Hu Jiajia, Peng Weiming, Ke Yonghong
Abstract: Research Platform of Digitized Ancient Chinese Stele Inscriptions is built to meet the need of the study on “Digital Archives of Stele Inscriptions from the Sui Dynasty to the Republic of China,” which is an important research project of the Research Center for Folklore, Classics and Chinese Characters of Beijing Normal University in China. The aim is to provide a computer network environment to support ancient inscriptions collection, sorting, processing, storage and retrieval. More than that is to develop relevant functions for various studies on stele inscriptions. The first task is to aid the study on the form style of Chinese characters that are used in stele inscriptions.
Keywords: Ancient Chinese Stele Inscriptions; Digitization; Collection and Research of Chinese Characters; Grapheme;
———————————————————————————————————————————————————————————————————
编 辑 | 许可
注释:
[1]王宁:《数字化时代的碑刻与碑刻学研究》,《陕西师范大学学报》(哲学社会科学版)2017年第2期。
[2]王宁:《汉字构形学导论》,北京:商务印书馆,2015年,第150—159页。
原刊《数字人文》2021年第3期,转载请联系授权。