

作者:永崎研宣;转自:公众号 DH数字人文
概念与实践

永崎研宣 / 日本人文情报学研究所
刘凯(译) / 四川大学外国语学院
————————————
摘要:数字人文深受IT(信息技术)的牵引,并且近期越发吸引到更多人文学科的研究者参与进来。基于人文科学与计算机研究会(Special Interest Group for Computers and Humanities,简称SIG-CH)[1]对991篇技术报告的分析可知,数字人文已经在语言学和文学领域展现出明显优势,同时它在历史学领域的研究成果正在快速增加,而在其他人文学科中它还只占很小的比重。虽然日语文本在数字环境中面临着很多困难,但这些困难也驱使人们尝试着去改善数字人文的研究条件。近年来IT技术的进步已经解决了一部分问题,日本推动开放科学与开放数据的举措将会使数字人文未来在日本更具成效。
关键词:数字人文 语言学 文学 人文科学与计算机研究会 日语文本
————————————
引言
鉴于数字人文目前在日本广泛且迅猛的发展,我们很难从每一个视角和对每一个项目进行介绍。本文将勾勒日本数字人文发展的几条脉络。人文科学与计算机研究会(SIG-CH)过去三十余年在日本扮演着重要角色,而与之相应,日本数字人文学会(Japanese Association for Digital Humanities,简称JADH)[2]自2011年成立以来就致力于为国际数字人文研究活动提供服务。此外值得一提的是数字存储领域发起的一项运动,即让数字存储更能适应日语环境,这得到了图书馆、博物馆等文化机构以及工业界的广泛欢迎。这项运动串联起了各类关注数字文化遗产的活动,并且作用更加广泛。因为它与数字人文有着互补关系,下文还将提及这些活动。
一、简史
同其他国家一样,日本人文学界或信息技术领域的专家学者早在几十年前就开始在人文学科中尝试数字化研究。1957年日本数理语言学会(The Mathematical Linguistic Society of Japan)[3]成立之后,研究者们开始推进为人文学科提供数字技术的各项活动。根据杉田繁治的调查(1982)[4],在大型计算机时代,一些研究机构,如国立国语研究所(National Institute of Language and Linguistics)[5]、国立民族学博物馆(National Museum of Ethnology)[6]以及国文学研究资料馆(National Institute of Japanese Literature)[7]就通过添置计算机将馆藏资料进行数据化,同时也将已有的数据进行优化。
继早期尝试之后,到1980年代末期IBM个人电脑涌现并促成了几个研究团体的建立。其中之一,SIG-CH就是在日本最大的计算机科学协会信息处理学会(Information Processing Society of Japan)[8]的资助之下成立的(下文将会讨论SIG-CH)。此外还有信息知识学会(Japan Society of Information and Knowledge)[9]和艺术文献学会(Japan Art Documentation Society)[10]。
因为SIG-CH是由计算机科学的学术性团体资助成立,所以它的导向不可避免地会更接近计算机技术而非人文,尽管参与者们自始至终都展现出了对文化遗产的强烈关注。这意味着SIG-CH的活动主要是从计算机科学的角度受到评估的。另一方面,计算机科学及相关领域有着长期固定的评价学术成果的方法并且迥异于人文学科,这为想要介入这些领域的人文学科的研究者带来了根本性的困难。因此,如果一个人文学者完成了一项以IT为核心的学术成果,那么它在人文学术圈内不会得到恰当的评价。尽管面临诸种限制,但是想要介入计算机科学和IT团体的人文学者的人数已经在稳步增长,并促使他们成立了JADH。
除SIG-CH以及其他学会进行的具有数字人文特征的研究之外,传统人文学科中的少量学术团体,例如佛教研究界自1980年代起就设法利用数字技术改善他们的人文研究。其后又有一些学术团体成立,它们主要得益于互联网的效应。特别值得一提的是,1990年代考古学、英语语料库[11]、亚洲文学等领域都设立了数字化的研究学会。
大量且频繁的政府拨款已经刺激和推动了数字人文领域,其中甚至有几项拨款的额度非同寻常。文部科学省批准了一项为期5年总计约100万美元的课题,该课题名为“计算机与人文科学:推进以计算机为辅助的人文科学研究”[12],课题组由SIG-CH的核心成员及相关具有影响力的学者组成。这项堪称大手笔的拨款为数字人文领域资助了众多学术会议的召开和系列教材的出版。文部科学省还设立了卓越中心(Center Of Excellence,简称COE)计划来进行拨款。这些拨款支持几个研究中心去实施具有数字人文特征的研究,如京都大学、东京外国语大学和立命馆大学。最值得一提的是,立命馆大学艺术研究中心[13]不仅将自身所藏的日本文化文献,如浮世绘,进行了数据化,并为这些数据开发出了多种类型的实用工具,而且还与其他藏有日语文献的研究中心和部门进行合作。他们也参与到了由赤间亮(Akama Ryo)教授[14]领携的国际数字人文研究团队。京都大学人文科学研究所设立了东亚人文情报学研究中心(Center for Informatics in East Asian Studies)[15],该中心作为数字人文的领军机构,为研究界开发出了多种实用的数字人文工具以及提供资源,并且开始挑战几个具有重大学术意义的课题,如古典汉文文本的词法分析。东京大学史料编纂所(Historiographical Institute The University of Tokyo)[16]也始终在为日本历史编纂工作提供巨量的数据。他们针对数据库的研究活动始于1980年代,并且在进展过程中受到了卓越中心的拨款资助。
除上述活动外,来自机构和其他形式的资助也在组织实施各种类型的项目。人间文化研究机构(National Institute for Humanities)的分支机构已经为人文学科开发出了多种多样的数据库和一个一体化的检索系统,该系统名为nihuINT (National Institute for Humanities Integrated Retrieval System)[17]。根据缪勒(Albert Charles Muller)[18]等人的介绍(2018),下田正弘(Shimoda Masahiro)教授领导的大藏经文本数据库研究会[19](SAT项目[20])自1994年起就由一个佛教研究者学会进行管理,该学会的资助方不仅有政府,而且还有佛教组织和寺庙,这样一来,需要使用佛教文献的研究者就可以很方便地通过数字媒介进行研究。
在2012年之后,也即在JADH成立并获准成为国际数字人文组织联盟(Alliance of Digital Humanities Organization,简称ADHO)成员之后,日本数字人文研究界开始稳步扩展自身与国际数字人文团体的合作。下文将介绍其近期动态。
二、数字人文研究趋势
我们可以通过SIG-CH迄今的报告来管窥日本数字人文研究在过去的总体趋势。这份数据之所以可用,是因为该研究会每个季度(近期改为每年3次)会举办工作坊并要求提交技术报告,而且工作坊向各种不同的研究领域开放,尽管如前所述,它是以IT为核心的领域。图1显示,语言学领域的报告数量最多且贯穿整个时期。在2009至2013年期间,其所占比重增长到了20%。造成这一增长的原因或许是Unicode技术的普及使得日语文献的文本分析变得更加简单以及大量日语语料库的开放。某些领域发表报告的次数会较为频繁,而很多领域的发表次数就很少,如区域研究、宗教研究、地理学、档案学、认知科学、实验室信息管理系统(LIS)、民俗学、音乐学、民族学。
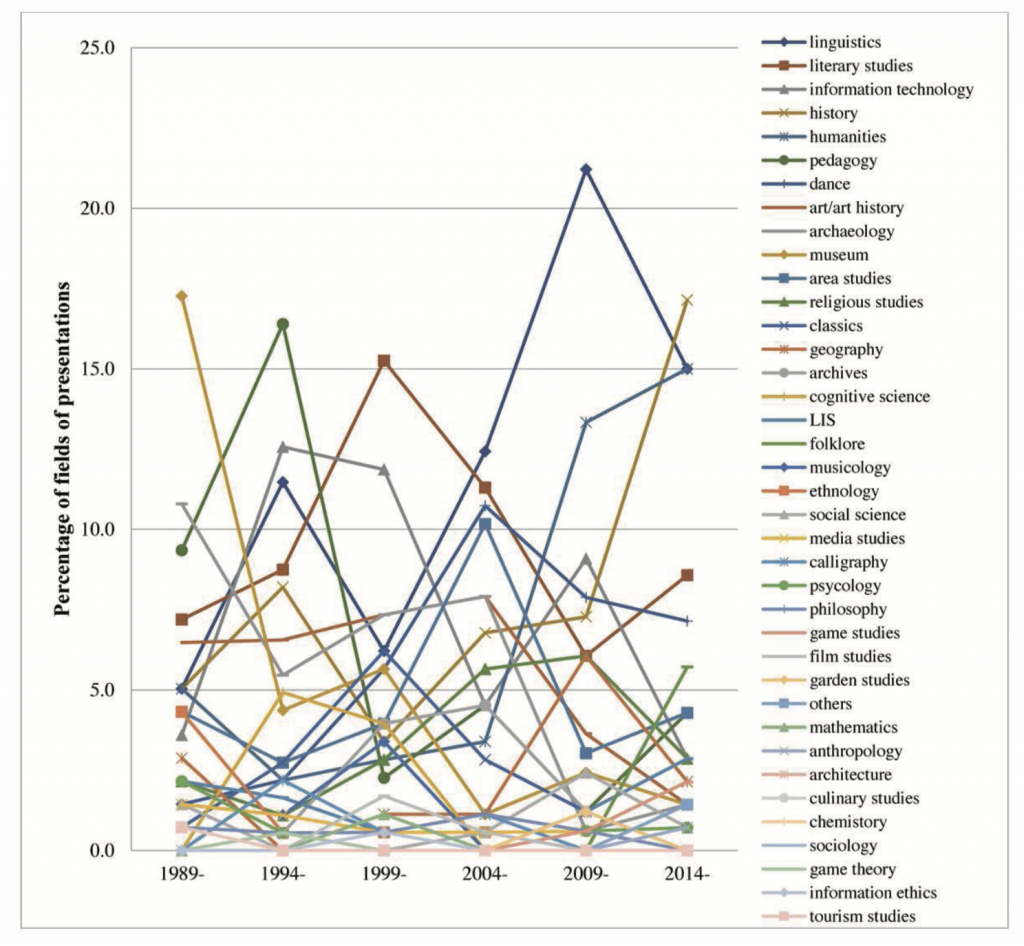
我们将报告数量排前十位的学科放到图2中进行总结分析。历史学近来增加了活跃度,这归功于几位富有活力的青年学者在该领域付出的努力。文学研究近年已经减少。博物馆学与早期相比也已经减少,在其早期阶段,博物馆学的研究者和从业人员聚集到一起研究更高效的展览筹办方法。舞蹈研究也有所增长,这归功于两个活跃的研究团队。随着数字文化资源建设在近年来的逐步推进,所有人文学科的报告数量都出现了增长。
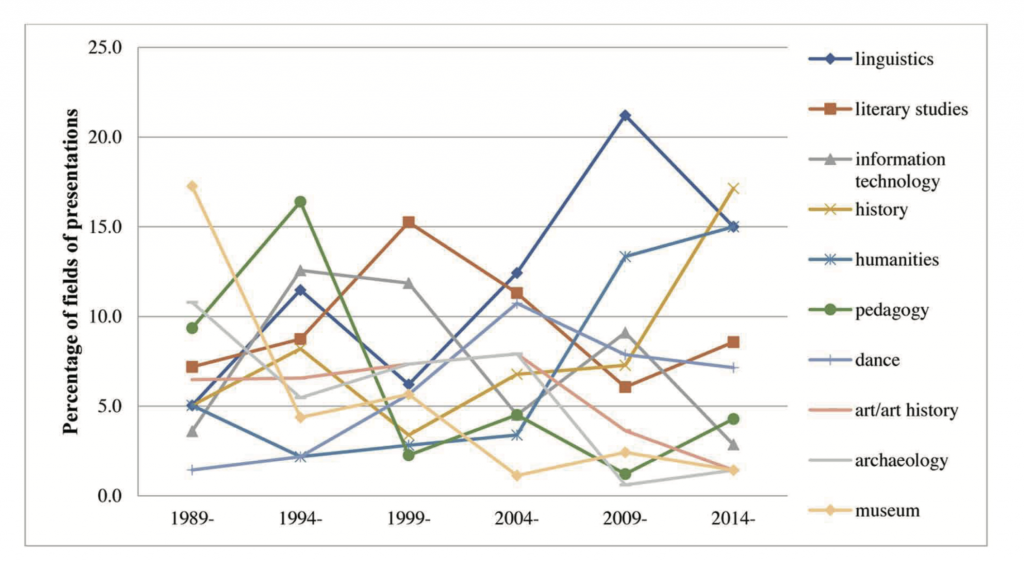
图3显示的是研究报告中采用的方法。数字化文献分析自1994年起就占据首要地位,但是近期有轻微回落。另一方面,软件开发一直在逐步增加。软件开发和数字化的所占比率之和超过了分析方法。随着近年来技术层面的发展,上述趋势或许已经发生了轻微改变,如代际更迭和人文科学研究条件的改变。为进一步研究,我们有必要去翻阅JADH的在线杂志、研讨会纪要和书籍,调查SIG-CH的技术报告和年会记录中的相关论文。
三、数字人文教育
因为日本的大学已经在实施以跨学科为导向的教育,所以在过去十余年间有不少大学已经在教授如何为人文学科提供数字技术,如东京大学、东京工业大学、立命馆大学、同志社大学、筑波大学等。举一个例子,东京大学早在2000年就联合交叉信息研究院共同组建了跨院系的信息研究组织[21]。此外作为对自身学科特色的补充,该研究院自2012年起联合人文与社会研究科、信息科学与技术研究科、新领域创制研究科共同开设了跨院系的数字人文辅修课程。该课程教授基本的数字人文技术,如文本分析、文本编码倡议(TEI)[22]、国际图像互操作框架(IIIF)[23]、元数据(metadata)以及包括注册许可在内的一些背景属性(background)。因为该课程面向所有研究生开放,所以人文学科中不同领域的学生,如语言学、西洋史、东洋史、佛教研究、宗教研究以及不同语种的文学研究,他们都可以参与其中。当中甚至还会有来自自然科学与技术领域的学生。
同志社大学文化信息学部和文化信息研究院也提供具有数字人文特征的教学,该机构成立于2005年,其中有日本文学文本分析的开拓者村上征胜(Murakami Masakatsu)[24]教授。他们长期教授如何利用统计分析的方法研究文化文献,如经典文本数据分析。立命馆大学在文学研究科开设了数字人文艺术与文化课程。该课程有多种多样的研究主题,这得益于该校艺术研究中心几个巨额拨款项目的研究成果和海量的数字化日语文化文献。
除正式课程外,研究者们还经常举办各种数字人文研讨会和工作坊,以此扩大讨论如何研究数字人文,如何利用和研发数字人文技术,例如TEI、IIIF、Omeka、Zotero、Python等等。其中近期的几场活动已经由研究生主办。
四、日语文本的无空格书写体系及其困难


大多数近代和前近代西方书写体系都通过空格或停顿在一个句子中体现词与词之间的间隔,这一点也让我们能够很方便地基于每个字词及其意义去使用电脑进行文本分析。但是,除此之外仍然有几个近代或前近代的书写体系在其文本中并没有显示出明确的间隔,即一个句子中的每个字词都连贯在一起。其中的典型代表出现在东亚的语言系统中。而且有一种在前近代日本较为常见的书写体系,名为KUZUSHI-JI(连笔草书体)[27],它常常是以无间隔的形式出现,即便到了19世纪末期的一些排版中仍然如此(见图4和图5)。两幅图都是这种连笔书写的案例。上图的案例为木刻排版,其版型就被制作成了连笔书写的样式。不过这种排版很快就在日本被淘汰。在那之后,木版印刷流行了大约200年。木版印刷所造成的一些难点,下文将进一步解释。
间隔的缺失不仅会造成意思不明,而且也会带来多元化的诠释,但也为日本文化创造了丰富性的一面。不过尽管如此,从结果来看,日语文本存在固有的显示困难:不管在文本解析还是在手工誊写和数字转录中。本文将会讨论这些书写体系中存在的问题以及当前研究者们通过数字人文方法如何尝试解决这些问题。
(一)转录困难

新近的日语文本在光学字符识别(OCR)中并不会出现较大问题,这不仅得益于每个字符的分隔,而且还受惠于印刷的精确度和清晰度。不过,有两个原因使我们很难对一百年以前的图书进行光学字符识别:第一,大部分文本都使用了相对复杂的字符导致难以识别;第二,这些文本被嵌入了并排书写的小号字符(在HTML5中被称为ruby)[30],这些小号字符用来给单词注音,并且其与相应单词的物理距离对光学字符识别而言过于接近(见图6),尽管它们是由金属排版印刷的。三百年前,日本在江户时代与其他国家脱离并采取锁国自封政策直至1868年。在那期间,大部分日语出版物都采用木版印刷,因为方便印刷公司反复印刷。在这种印刷方式中,字符往往都是连贯的,而且这种书写方式的相当一部分是草书体(见图7)。
近来,部分学者和实践者正在尝试开发各种工具来自动识别KUZUSHI-JI,这项尝试不仅仅以单个字符的字形来操作,而且还包括字符的连贯书写体。虽然他们还没有完全实现对所有字符的精确转录,这受制于技术和文本本身等层面的原因,但是他们的技术可以为我们在阅读这些文本时提供候选字符。图8展示的是一个自动识别草书体字符的尝试,它是首先利用网站IIIF image API[31]从文本图片上截取一个字符,然后再在Heroku[32]上进行机器学习后获得的。[33]图9展示的是一项图片搜索系统上的检索结果,这是一个协同转录软件,名为“Smart-GS”。[34]图片展示的内容是在一个文本中检索到的一系列相似的连笔书写字符。该软件由京都大学林晋教授[35]开发,他采用的图像搜索算法由函馆大学寺泽宪吾教授[36]开发。此外,人文学科开放数据共同利用中心(Center for Open Data in the Humanities,简称CODH)[37]也在利用由国文学研究资料馆开发的数据集并通过深度学习来对KUZUSHI-JI进行光学字符识别。CODH还为研发KUZUSHI-JI的光学字符识别举办了工作坊和竞赛。


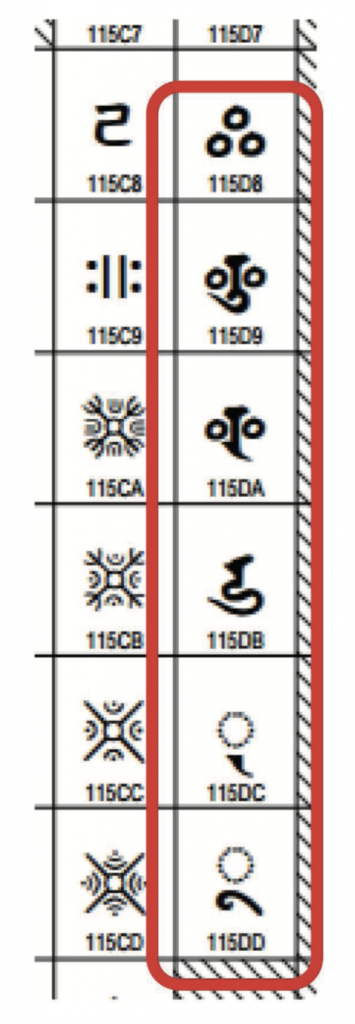
但是,实际情况中仍然会出现一些特殊的困难,尤其是当我们需要的某个字符尚无Unicode编码时。这似乎与中世纪字体Unicode协议(Medieval Unicode Font Initiative,简称MUFI)的情况类似[38],不过在包括日本在内的东亚文化中尚未编码的字符数量应当更多。特别是由于日本文化早已经与外国文化发生了复杂的关联并且在自身的体系中将其改造,所以它的文化文献中保留了几种不同的书写体系,包括汉字、平假名、片假名、变体假名以及梵语字母。
现在中日韩统一表意文字(CJK unified ideographs)及其在Unicode中有编码的字符已经超过了80,000个,这个数量将来还会增长。变体假名(包括200个以上的象形文字)也终于在Unicode 10.0中完成了注册。梵语字母及其变体也在Unicode 8.0中完成了编码(图10),这归功于字母编码协议(Script Encoding Initiative,简称SEI)[39]、国际学者以及SAT项目的努力。因为梵语字母是在印度被创制的,所以原则上它们只具有语音值。不过,这些字母的用法在日本发生了转变,这可能是受汉字的影响。其结果是,某些有着相同语音值但是字形不同的字符被指定为具有不同意义。这意味着在日本使用印度语系的字母时必须要对其进行转换。虽然这个转换需要花费三年以上的时间,但是通过这项活动,文化多样性得以在数字技术中实现。
为了给日语文本,尤其是给经典文本制作出便于利用的数字化的学术版,上述项目流程还将继续。
我们在转录中的种种尝试,同样还得益于日本国内使用高分辨率数字图像数据库将文本材料电子化这一措施的发展与普及。特别是日本国立国会图书馆一直在设法处理已经电子化了的超过300,000册馆藏出版物——自几十年前开始,并且近期他们再次重申,其中的大部分出版物都将会向公众开放。而另外一些机构,例如京都府立综合资料馆[40]和东京大学图书馆正在发布已经获得公开许可的电子馆藏。立命馆大学艺术研究中心和国文学研究资料馆已经公开了很多获得学术授权的电子文献。后续的研究机构也都计划在2018年将获得公开许可的馆藏资源转移到一个综合性的数字化项目中。毋庸赘言,这些都将有利于提高人文学科研究工作的便利性。特别是在日本,许多人文学科的研究者表示,随着数字化图像利用率的提高,检索结果的有效性为研究工作带来了更多的便利。
众包转录[41]也已经开始在日本崭露头角。转录日本项目[42]已作为一个研究会被编入JADH。它开发出了一个带Omeka和Scripto插件的用于转录的Web服务器(见图11)。
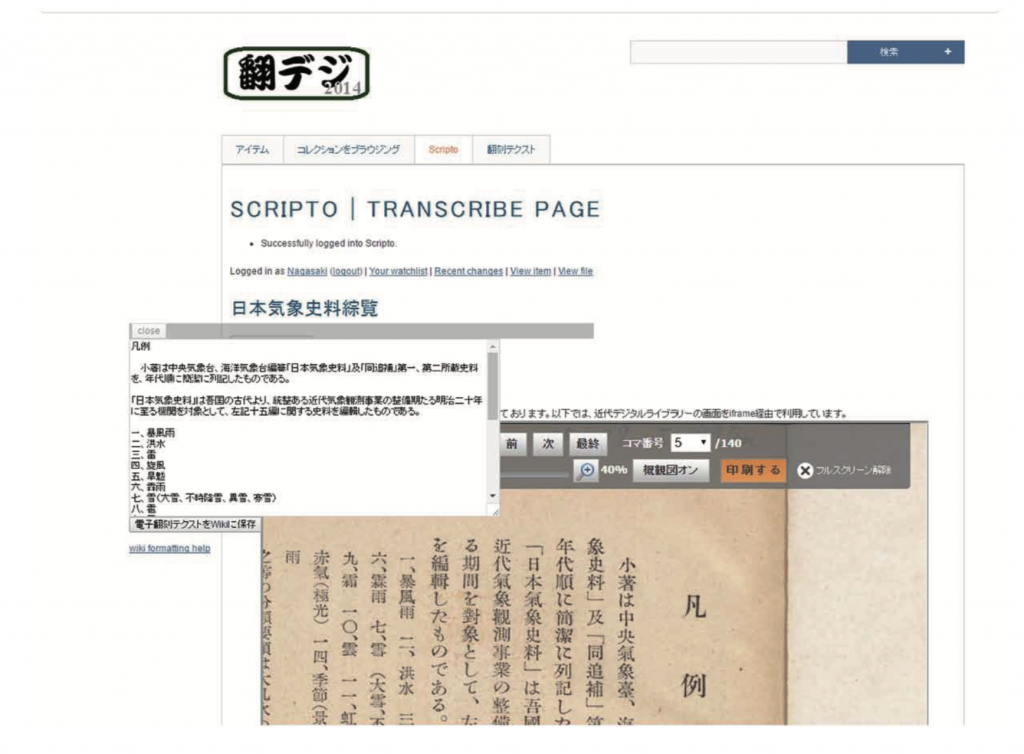
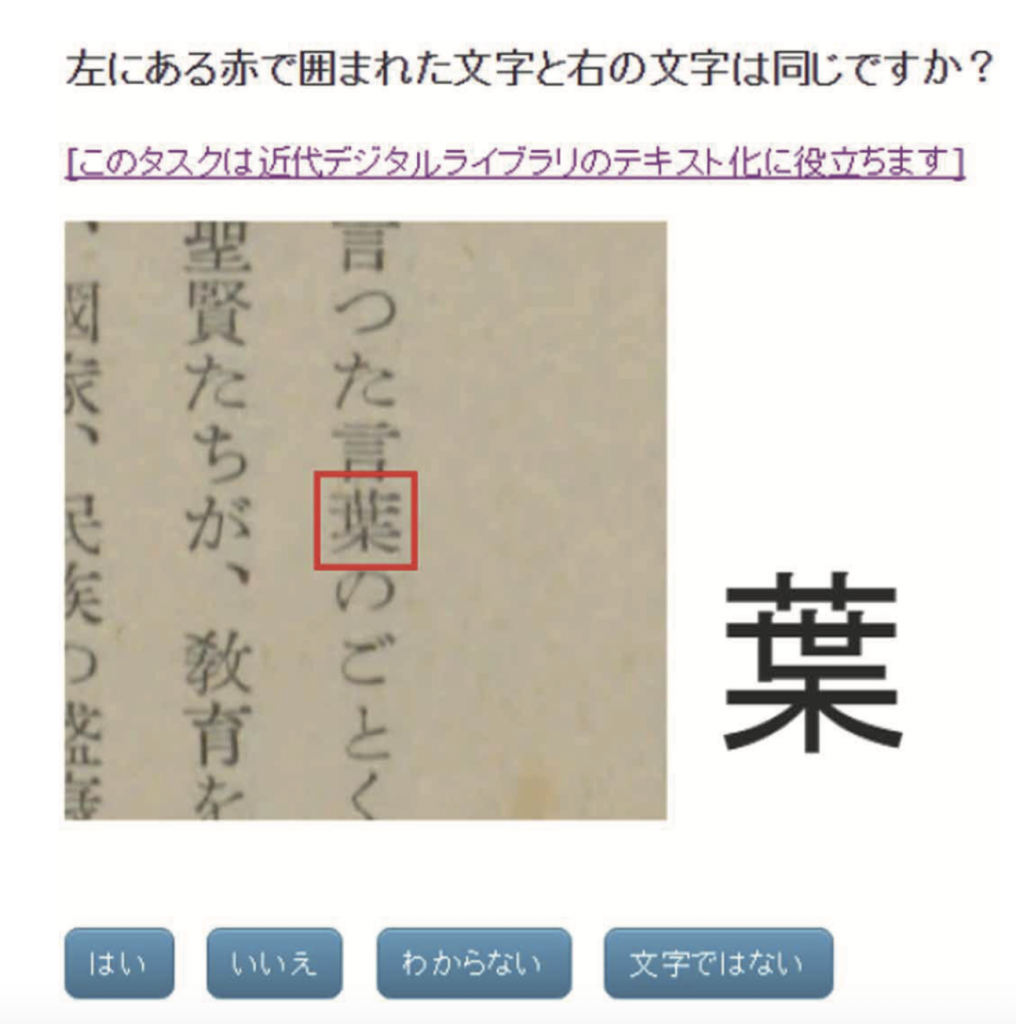
它最开始是在2015年10月作为一个微任务众包项目启动的,并且与Crowd4U项目[43]合作进行。参与者通过一张图片来对比候选字符,并且只需要一次点击就可以判断该字符是否已被精确地进行光学字符识别(见图12)。第一次试验被安排在2015年12月至2016年4月期间,研究者选定了一本来自日本国立国会图书馆电子书库并已经面向公众开放的图书。到目前为止,已经有10,630项任务在个人电脑和智能手机上得到执行。一个结果是,这本书的第一部分已经被转录。不过这项任务似乎还需要更多努力。项目组为此也正在筹备一种更高效的操作方法。
前近代日语文本的转录问题近期也被一个历史地震研究团队成功地解决了。一般而言,让公众去解读这些文本中的KUZUSHI-JI往往是很困难的。不过根据桥本雄太[44](2017)的介绍可知,该项目组通过与一个用来学习KUZUSHI-JI的移动应用程序进行合作,已经成功地集结了一批能够转录这些字符的人员。网络协作系统Minna De Honkoku[45](大家一起来转录)设计了一种类似于排名系统的游戏化应用以吸引参与者们。到目前为止,这个项目已经转录了超过500万个字符。
(二)字符分隔困难
虽然在转录过程中面临各种困难,但是现在我们已经有了很多数字化的日语文本。比如青空文库就是一个向公众开放的日语知识库,它类似于古腾堡计划,在其网站和GitHub上提供超过10,000个文本。日本国立国语研究所(NINJAL)在网站[46]发布了一些带有词性标注(Part of Speech,简称PoS)且被编码过的具有历史意义的日语文本,同时还发布了多个现代日语文本分析Web服务器,其中包含1亿个词且每个词都带有词性标注,原始版式为书面日语均衡语料库(Balanced Corpus of Contemporary Written Japanese,简称BCCWJ)。[47]SAT[48]项目也在其网上提供佛教经文的电子文本,并且还有包括100万个以汉语、日语字符为主的文献集和各种实用工具。
日本国立国语研究所的文本是由词性标注过的分隔词组成,但是其他大部分文本并没有采用这种方式。用于文本分析的其他方法在日本较为普遍:一个例子就是n-gram分析,一个字符在其中就会被标注为“n”。另一种方法是开发自动化的字词分隔工具,有时候是利用POS标注器进行开发,例如Mecab、Chasen和Kuromoji。这些工具实现了很高的精确度,但有时也会产生差错。在这种情况下,如果需要共享经过高精度加工的文本,就必须对这些工具的标注结果进行人工校对。另外,即便一个分隔在语法上没有错误,但是在某些情况下它也会造成不同解释。这种情况也会发生在字词分隔语料库中,例如“北大通り”既可以理解为“北海道大学大街(北大—通り,Hokkaido University Street)”,也可以理解为“北大街(北—大通り,North Large Street)”。这种书写体系本身就含有这种状况。
(三)文本渲染
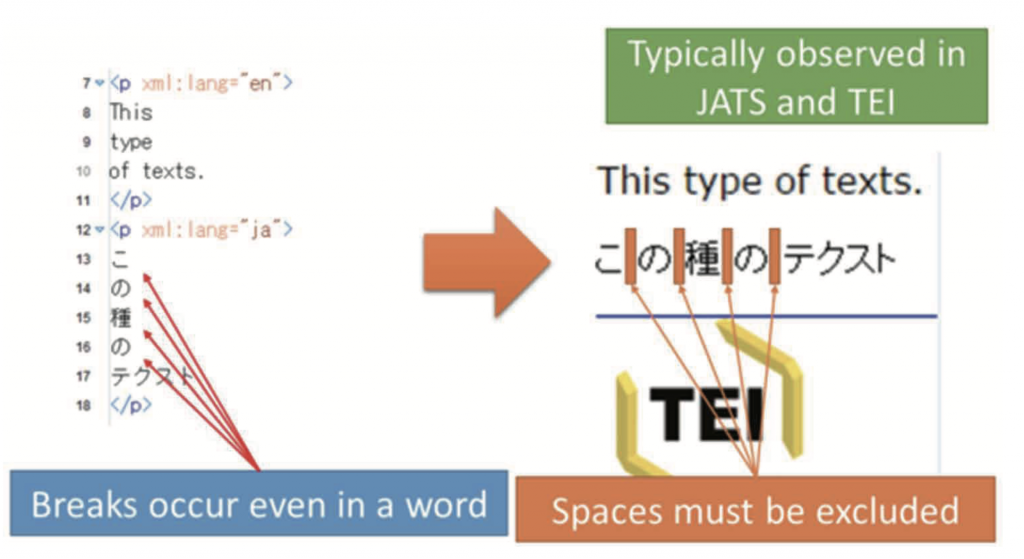
在XML格式的文本中,例如那些保留在TEI、JATS(Journal Article Tag Suite)[49]等中的,XML源文件中的一些break[50]表现似乎在常见的样式表(stylesheet)中会被认定为单词间的一个空格或一个分隔。但是在无分隔的文本中,会出现诸如分隔不精确等问题。图13中经过XSLT处理的日语文本必须清除掉字符之间的空格,不论XML源文件中是否有断行(图13中右侧)。相反,作为一个半官方、开放式的日语期刊访问系统,J-stage采用了JATS,因为即便在英语文本中JATS也会忽略断行,而在J-stage的系统中字词是连贯的。根据目标语言的不同,使用CSS[51]解决方案在ePub中似乎也可以识别此问题。而与此同时,这些问题在数字人文领域本应当早已得到讨论,因为无空格文本已经出现在了各种不同的时间和地点,我们不仅要在文本的表现形式上,而且还要在文本分析过程中谨慎地处理XML源文件中出现的各种不同的断行识别结果。这些问题都将由东亚/日语文本研究会[52]进行解决,该研究会在2016年由TEI财团成立。
在当下数字人文的背景之下,巨量的人文资源仍然处在休眠状态。为了唤醒这些资源和这个研究领域,我们应当同时从现实和抽象两个层面去逐步揭示、解决前述问题。在全球化的交流中对它们进行认真解决,如此数字人文将会更加硕果累累。
五、最新动态
除前文提及的数字人文在日本的动向之外,IIIF和关联开放数据项目(LOD)也受到了研究者和实践者的集中关注。IIIF似乎也正在数字文化遗产和网络技术中崭露头角。因为是基于通用的网络技术而建设的,例如JSON-LD[53],它已经在全世界快速传播,并且在日本也逐渐扩张。东京大学、庆应义塾大学、京都大学较早就使用它来处理日本和东亚经典书籍的电子馆藏及其他文献;国文学研究资料馆则利用它来处理馆藏的日语经典文本。另外,因为国立国会图书馆也为其超过30万册已经公开的电子馆藏图书实施了IIIF,所以用来高效地处理高分辨率网络图像的条件已经就位,这同样也适用于日本和东亚的文献。由于IIIF允许高分辨率网络图像及其他数字化内容通过一些API(视自身规格而定)去翻越组织之间、网站之间的界限,所以一些数字人文研究者近来开始通过开发各种软件和系统来利用它。CODH也发布了一个专业IIIF查看器[54],名为“IIIF Curation Viewer”,它使跨网站的对网络图像的“curation”(内容管理)成为可能。东京大学数字人文枢纽[55]也参与了一个IIIF查看器的开发项目,并且研发了一个使用IIIF的协同系统,它是一个用于佛教图像研究的平台[56],此外还开发了一个为世界各地网站公布的佛教文本进行校准的协作平台[57]。
一些研究机构,例如国立历史民俗博物馆的Khirin(Knowledgebase of Historical Resources in Institutes)项目组[58]和东京大学档案馆[59]一直在设法实现既可以用IIIF也可以用LOD来使用他们的数字馆藏。而此类工作在整合时间、空间信息时会展现出更为重要的价值,例如关野树[60](2017)针对历法文献的研究以及人文学科GIS研究会[61]经不懈努力于近期开发出的历史地名数据库。[62]
结论
正如我们所看到的,数字人文在日本与其在其他国家一样,正以各种各样的方式发展着。伴随着信息技术的革命,数字人文也得以发展进步。特别是网络技术的革新近年来一直在推动着数字人文。由于人文学科近来在日本面临的危机,如吉见俊哉(2016)所讨论的[63],数字人文不仅对人文学科的变革而且对公众参与都将更加重要。另外,数字人文近来也受到了开放科学运动的助推,这项运动由以日本内阁府为代表的政府机构资助,是为了让更广泛的人员参与到人文科学的研究之中。其结果是,可重复利用的共享数据和各种研究条件在未来会更加丰富,并且将改变人文学科。
—————————————————————————————————————————————————————————————
Contexts of Digital Humanities in Japan
Nagasaki Kiyonori
Abstraction:
This paper describes the brief history and recent trends in digital humanities in Japan, which had been led within the context of IT (information technology) and recently has strongly involved humanities researchers. According to the analysis of 991 technical reports by the Special Interest Group for Computers and Humanities (SIG-CH), the fields of linguistics and literary studies have been dominant while recently the history field has been increasing its number of the presentations, and many other fields in the humanities have been treated in a small percentage. Although Japanese texts have many difficulties in the digital environments, some attempts to improve the DH research environment have been activated. The rencent developments in IT partially solve the problems, and the policy of Japanese government to promote open science and open data will make DH in Japan more fruitful in the future.
Keywords: Digital Humanities; Linguistics; Literary Studies; Special Interest Group for Computers and Humanities; Japanese Texts
—————————————————————————————————————————————————————————————
编 辑 | 姜文涛
作者简介
永崎研宣(ながさき きよのり/Nagasaki Kiyonori,1971—),日本关西大学博士,现为日本人文情报学研究所首席研究员,兼任东京大学讲师、筑波大学讲师、日本国立国会图书馆研究员、日本印度学佛教学会常务委员会委员、日本数字人文学会理事会会员、日本数字人文学会会刊编辑委员、SAT大藏经文本数据库研究会委员等职。专注于计算机技术在人文学科中的开发与利用,常年致力于使用数字人文技术整理、研究日本佛教文献,是当下日本数字人文研究领域最为活跃的学者之一。
个人主页:https://www.dhii.jp/nagasaki/。
原文信息如下:Nagasaki Kiyonori,“Contexts of Digital Humanities in Japan,”Digital Humanities and Scholarly Research Trends in the Asia-Pacific, eds. Shun-han Rebekah Wong, Haipeng L., and Min Chou, Pennsylvania: Information Science Reference, 2019. pp.71-90。
感谢作者授予中文翻译及发表的版权。
注释:
[1]人文科学とコンピュータ研究会,http://www.jinmoncom.jp。
[2]Japanese Association for Digital Humanities, https://www.jadh.org/.
[3]http://www.math-ling.org/e-index.html.
[4]杉田繁治(すぎた しげはる /Sugita Shigeharu,1939—),京都大学工学博士,国立民族学博物馆名誉教授。研究领域为计算机民族学、比较文明论。本文作者引用的杉田教授的论文:《研究博物館と情報処理:国立民族学博物館での経験》,《情報処理》第23卷第3号,1982年3月15日,第194—200ページ。论文电子版:https://ci.nii.ac.jp/naid/110002719732。
[5]国立国語研究所,https://www.ninjal.ac.jp/english/。
[6]国立民族学博物館,https://www.minpaku.ac.jp/。
[7]国文学研究資料館,https://www.nijl.ac.jp/index.html。
[8]情報処理学会,http://www.ipsj.or.jp/。
[9]情報知識学会,http://www.jsik.jp/。
[10]Japan Art Documentation Society, http://www.jads.org/.
[11]English corpora, https://www.english-corpora.org/corpora.asp.
[12]该课题负责人为综合研究大学院大学教育研究信息中心教授及川昭文(おいかわ あきふみ/Oikawa Akifumi),项目组成员有立命馆大学理工学部教授八村广三郎、国文学研究资料馆教授安永尚志、大阪电气通信大学信息工学部教授小泽一雅、统计数理研究所教授村上征胜、国立国语研究所部长中野洋。项目期限为1995—1999年,拨款总额为1.35亿日元。项目信息主页:
https://kaken.nii.ac.jp/ja/grant/KAKENHI-PROJECT-07207105/。
[13]http://www.arc.ritsumei.ac.jp/en/index.html.
[14]赤间亮(あかま りょう/Akama ryo),日本立命馆大学文学部教授,研究领域为日本近世文学与艺术,是浮世绘、歌舞伎研究的代表学者。专著有《文化信息学事典》(与村上征胜合编,勉诚出版,2019)等。个人主页:http://research-db.ritsumei.ac.jp/Profiles/35/0003448/profile.html。
[15]http://www.kita.zinbun.kyoto-u.ac.jp/.
[16]http://wwwap.hi.u-tokyo.ac.jp/ships/db-e.html.
[17]https://int.nihu.jp/?lang=en&.
[18]Albert Charles Muller,东京大学文学部教授,研究领域为印度哲学、佛教学、语言学,是英文版电子佛教辞典的运营者。
[19]http://21dzk.l.u-tokyo.ac.jp/SAT/index_en.html.
[20]SAT是“Samganikikrtam Taisotripitakam”(大藏经)的英文首字母缩写。1994年,东京大学文学部印度哲学佛教学研究室的江岛惠教(えじま やすのり/Ejima Yasunori,1937—1999)领导成立了“大藏经文本数据库研究会”,其目的是将《大正新修大藏经》的全部文本进行数字化。该项目先后得到政府和民间的经费资助共计6亿日元,参与者226人,最终于2006年7月完成,历时13年。在江岛教授于1999年令人遗憾地去世后,其弟子、现任东京大学教授下田正弘继承其遗志,带领团队继续完成并深化了该项目。关于本项目的更多信息可参考永崎研宣:《SAT大蔵経テキストデータベース――人文学におけるオ ープンデータの活用に向けて》,《情報管理》第58卷第6号,2015年9月。项目主页:https://21dzk.l.u-tokyo.ac.jp/SAT/。
[21]東京大学大学院情報学環·学際情報学府,http://www.iii.u-tokyo.ac.jp/。
[24]村上征胜(むらかみ まさかつ /Murakami Masakatsu,1945—),生于中国南京。斯坦福大学统计学硕士、北海道大学工学博士。先后任日本文部科学省数理统计研究所研究员、综合研究院大学教授、同志社大学文化信息学院教授,日本数理统计学领域著名专家。专著有《计量文化——文化计量学序说》(朝仓书店,2002)、《文化信息学入门》(勉诚出版,2006)等。
[25]Eiri-Genji-Monogatari (Pictorial tales of Genji), ed. Yamamoto Shunsho, 1654. http://base1.nijl.ac.jp/~anthologyfulltext/.
[26]Ise-monogatari (Tales in Ise), Saga-bon, 1608, Typesetting printing. http://dl.ndl.go.jp/info:ndljp/pid/1287963/6.
[27]日语写作“崩し字”,念作“くずしじ/kuzushiji”。
[28]Ruby close to text body. Ohashi Matatarou, Jituyou-ryouri-hou ( A Guidebook to practical cooking ), Hakubunkan, 1895. http://dl.ndl.go.jp/info:ndljp/pid/849051/19.
[29]Continuous characters. Shiranui-monogatari ( Tales of Shiranui ), ed. Ryusuitei Tanekiyo, vol. 68a, Enju- dou, 1885. http://dl.ndl.go.jp/info:ndljp/pid/884924/8.
[30]这是一种在近代日语文本中较为常见的书写方式,常用来给汉字词汇标注日语假名读音,字号约为现代的七号,在日语中被称作“振り仮名”(furigana)或“ルビ”(ruby)。
[31]Application Programming Interface,应用程序接口。https://iiif.io/api/image/3.0/#11-audience-and-scope.
[32]Heroku是一个支持多种编程语言的云平台。
[33]The system was developed by Jun Homma.
[34]Smart-GS是一个用来对图像进行检索、查看、编辑等操作的文献研究软件。其名称中的“GS”是德语“Geschichte Studie”的缩写,意为“历史研究”。关于该软件的详细介绍和使用方法参见:http://www.is.nagoya-u.ac.jp/dep-ss/phil/kukita/works/SmartGS-Lecture-20140915.pdf。
[35]林晋(はやし すすむ /Hayashi Susumu,1953—),筑波大学理学博士,京都大学文学研究科名誉教授、神户大学名誉教授。研究领域为数学、软件工程、历史文献学、数字人文等。近期主要专注于利用数字人文方法研究京都学派的思想。林晋教授个人主页:https://shayashiyasugi.com/。
[36]寺泽宪吾(てらさわ けんご/Terasawa Kengo),研究领域为图像处理、算法、信息检索。个人主页:
https://www.fun.ac.jp/~kterasaw/。
个人主导开发的“文书图像检索系统”:
[37]http://codh.rois.ac.jp/index.html.en.
[38]https://folk.uib.no/hnooh/mufi/.
[39]该项目由加州大学伯克利分校语言学系在2002年4月设立,其目的是为在Unicode标准中没有编码的字符提供编码支持。项目主页:https://linguistics.berkeley.edu/sei/index.html。
[40]京都府立総合資料館,https://www.pref.kyoto.jp/shiryokan/。
[41]原文为“Crowd-sourced transcription”,众包(crowdsourcing)是指从一个广泛的不特定群体,特别是在线社区获取所需想法、服务、资金或内容贡献的行为,与外包(outsourcing)相对。
[42]原文为“The Transcribe JP Project”,该组织现在是日本数字人文学会(JADH)的分支学会,作者永崎研宣在其他论文中也将其名称标记为SIG-Transcribe JP。
[44]桥本雄太(はしもと ゆうた /Hashimoto Yuta),京都大学文学博士,现为日本国立历史民俗博物馆助教、日本数字人文学会成员。研究领域为数字人文、科学史、数学史。Japan and the World.org在2020年7月发 布了一则对桥本博士的视频采访,桥本博士在视频中针对前近代日语文本的识读与转录方法做了介绍,参见:
https://japanandtheworld.org/2020/07/02/reading-early-modern-japanese-texts-with-ai/。
[45]该名称为日文“みんなで翻刻”的罗马字母转写,意为“大家一起来转录”。系统主页:https://honkoku.org/。
[46]http://pj.ninjal.ac.jp/corpus_center/chj/.
[47]http://pj.ninjal.ac.jp/corpus_center/bccwj/en/.
[48]http://21dzk.l.u-tokyo.ac.jp/SAT/index_en.html.
[49]https://jats.nlm.nih.gov/.
[50]计算机术语,意为“跳出循环”“结束”“断点”。
[51]Cascading Style Sheets,层叠样式表。
[52]Special Interest Group for East Asian/Japanese Texts, https://wiki.tei-c.org/index.php/SIG:East_Asian.
[53]JavaScript Object Notation for Linked Data.
[54]http://codh.rois.ac.jp/software/iiif-curation-viewer/.
[55]Digital humanities initiative: https://21dzk.l.u-tokyo.ac.jp/DHI/.
[56]https://dzkimgs.l.u-tokyo.ac.jp/SATi/images.php?alang=en.
[57]http://bauddha.dhii.jp/SAT/iiifmani/show.php.
[58]https://khirin-ld.rekihaku.ac.jp/.
[59]https://park.itc.u-tokyo.ac.jp/UTArchives/uta/s/da/page/home.
[60]关野树(せきの たつき/Sekino Tatsuki),京都大学理学博士,现为日本人间文化研究机构地球环境学 研究所教授。研究领域为环境政策、图书情报、人文社会信息。
[61]http://www.h-gis.org/.该研究由京都大学区域研究综合信息中心在2004年成立,其目的是将区域研究和信息技术进行融合。
[62]https://www.nihu.jp/ja/publication/source_map.
[63]吉见俊哉(よしみ しゅんや/Yoshimi Shunya,1957—),东京大学教授、东京大学前副校长。研究领域为社会学、文化研究、都市研究、媒体研究。本文作者提到的吉见教授的专著为:《文系学部廃止の衝撃》(集英社,2016)。2015年6月,日本文部科学省向公立大学发布了有关废除文科院系的通告,顿时引起社会各界激烈讨论。吉见教授在这部著作中对日本大学教育中重理轻文、认为理科有用而文科无用的倾向做了梳理和批判,他认为,为应对社会历史的转变,与能够给出短效解决方案的理科知识相比,能够发现、创造新目的与价值的文科知识才是真正有效的。吉见教授是一位广受赞誉的学者,并且积极为社会问题发声,他的学术论著已有多部中文版。个人主页:http://www.yoshimi-lab.jp/。
原刊《数字人文》2021年第1期,转载请联系授权。