

作者:Spencer Stewart,朱吟清,吴佩臻,赵薇,Clovis Gladstone,Hoyt Long ,Anatoly Detwyler,Richard Jean So;转自:公众号 DH数字人文
学术通讯

Spencer Stewart / 芝加哥大学历史学系
朱 吟 清 / 芝加哥大学人文学院
吴佩臻 / 伊利诺伊大学厄尔巴纳-香槟分校英语系
赵 薇 / 中国社会科学院文学研究所
Clovis Gladstone / 芝加哥大学Textual Optics Lab
Hoyt Long / 芝加哥大学东亚语言文明系
Anatoly Detwyler / 威斯康星-麦迪逊大学亚洲语言与文化系
Richard Jean So / 麦吉尔大学英语系
——————————-
文本光学·实验室(Textual Optics Lab)
随着数字人文在亚洲乃至全球范围内的兴起,技术的更新为文学文本的探索带来了新的期许,所能处理的规模也是前所未有的。当文学经典的范围扩张至上百万量级的文本时,我们该如何革新我们的文学和文学史研究?如何启用最前沿的技术和方法来从大规模文本中揭示出之前无从勘查的趋势、长时段的历史转型,以及跨文化存在的语言模式?软件可以帮我们跨越语言的壁垒,达成一种真正全球视野的比较文学研究吗?
这些提问正体现了所谓远读(distant reading)研究的惯常思路和宗旨。事实上,也正是在这一思路的指引下,该领域最复杂的软件工具目前仍执着于远读的方面,如此,过于抽象的远读便有可能在以算法处理文本和文本自身之间造成了不同程度的断裂,抹掉文化和知识生产的特殊性,然而这却是人文学者最看重的东西。
正是基于这样的认识,最近几年来,一个带有多种语言和文化背景的跨学科研究团队在芝加哥大学组建起来。他们在积极应对数字技术为文学研究带来的潜在挑战和变革的同时,也致力于更好地理解远读和细读两种研究样式之间的转换。文本光学实验室(Textual Optics Lab)营造了一个类似于实验室的环境,来巩固和扩大他们的工作范围。[1]这个项目聚焦于新的可伸缩(scalable)的阅读方法的概念和实践,尝试利用一系列工具和阐释办法,通过多种尺度的“透镜”来阅读和分析文本档案——从单一的词到上百万卷的资料,可以在细读和远读之间自由滑动,在诠释学之类的传统定性研究和从大量数据中提取统计学意义上的显著模式之间来回交替。一般而言,工具是用于在很高的层面上从大型语料库中勘查现存抽象模式(pattern)的——无论是数据挖掘,可视化,还是机器学习和网络分析,只有把工具和语文学的文本分析方法真正结合,将远读和细读统一在数字化的工作中,才便于从计算机计算和人文质询的交汇处发力,最终导向一种计算批评(computational criticism)和文化分析学(cultural analytics)的研究。
作为一种潜在方法的文本光学项目主要包括三个方面:其一是技术基础设施建设,有助于远读和细读之间的转换;其二是范围更广的语料库;最后是研究者跨语言和跨文化的合作网络。在项目的实施过程中,在构想、发展和使用高质量的文本工具方面,团队不断征集到大量技术经验,大跨度地创造多种语言文化背景下的数字文本档案,发展出从数据中提取洞见的工具。参与者生产制造了一系列技术平台和文学研究的数字模型,从而扩展了此类工作的途径,同时也有助于建立一种意识,让人们知道这些方法和其他分析框架的相通之出。
该项目由芝加哥大学纽伯尔文化与社会科学院(Neubauer Family Collegium for Culture and Society)发起并资助,由成立于2012年的芝加哥文本实验室(Chicago Text Lab)[2]和历史悠久的ARTFL数字化项目组成。[3]ARTFL数字化项目分支中的多个子项目共享了一个语文学的检索平台PhiloLogic,这个平台目前已经建成三十多种英文、日文、法文、中文、德文的数字语料库。其中开放语料库有“莎士比亚手稿文库”(First Folio of Shakespeare’s Plays)、“青空文库”(Aozora Bunko)、美国小说语料库(US Novel Corpus)等;限制性开放的语料库有“十三至二十世纪英文文献汇编”(English Language Collection)、“英文戏剧汇编”(English Language Drama Collection)、“英语圣经”(Bibles in English)、“黑人写作史语料库”(History of Black Writing Corpus),以及正在建设中的“民国时期期刊语料库(1918-1949)”(Republic China Periodicals: 1918-1949)等。
PhiloLogic的检索基础来自语料库语言学和欧洲语文学传统。它是一个全文检索的引擎和分析工具,内嵌入了CONCORDANCE、KWIC、COLLOCATION和TIME SERIES等基本的语义检索功能,并且可以在团队所收集的元数据基础上进行精细化检索。最近研发出的一个工具叫作TextPAIR,是基于基因序列比对技术(sequence alignment)的测量工具,用于从大量文本中发现语段间的相似性,包括直接引用、剽窃和其他形式的借用以及一般表达的化用等。团队在2018年5月的芝加哥大学数字人文论坛上发布了这一工具,收到了同行们的积极反馈。这一工具曾经较成功地应用于言文一致运动时期的日语散文研究,以及古罗马哲学家卢克莱修在18世纪英国的接受研究。[4]
民国时期期刊语料库(1918-1949)
一个还在建设中的项目是芝加哥大学文本光学实验室与上海图书馆合作的民国时期期刊语料库检索分析平台(1918-1949),这项始自2016年的工作,致力于完成一个大型的数字化工程,也有望整合进更广泛的跨语言、跨平台的基础设施中。在此前一阶段的合作中,上海图书馆投入大量人力和财力,对民国时期的原始期刊档案进行扫描和光学字符识别(OCR)工作,并保证人工校对后的错误率在万分之五以下。芝加哥大学实验室支付相应费用,根据包含几项基本元数据信息的机读纯文本文档的语料特征和研究需要,开发适用的分析检索工具。语料库知识产权归上海图书馆所有。
这个项目将总共数字化278种期刊,总数达666000页的文本,其中既囊括了那些著名的近现代杂志,也将更多散落在历史角落里不为人知的期刊纳入进来。目前已经完成的除了第一阶段的数字化工作,也对语料进行了元数据的搜集、考辨和分词标引(tokenization)等结构化处理,并将这些信息整合进PhiloLogic4的框架。基础建设阶段的第二大工作是文类自动识别工具的研发和探索。已经初步开发出了针对一定量样本的诗歌/散文区分工具,fiction/non-fiction的辨识工作还在多个方案的路径上同时推进。
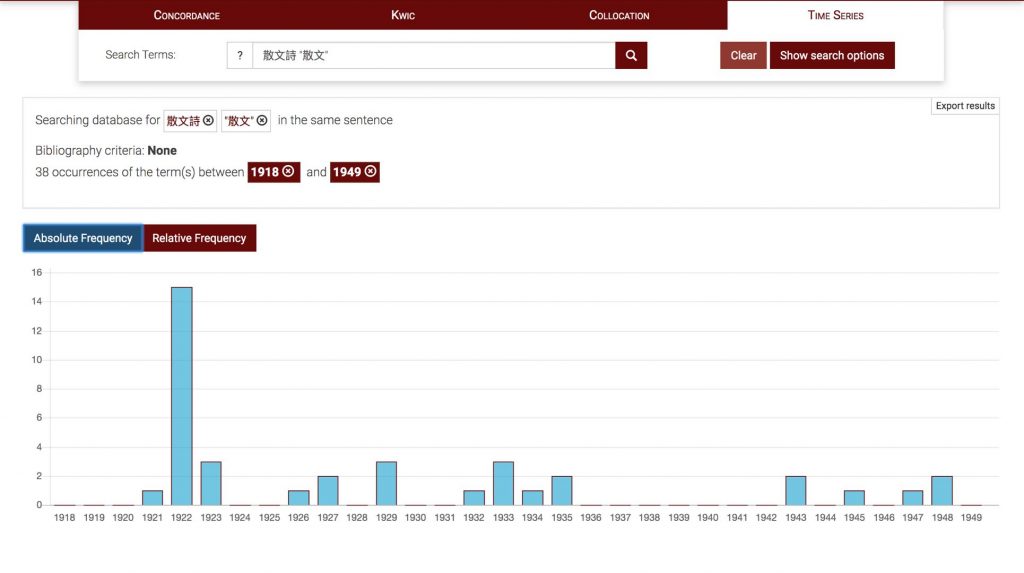
在PhiloLogic界面,使用者可以按照期刊题名或年代对语料进行检索。通过对逐词检索(CONCORDANCE)、关键词居中检索(KWIC)、词语搭配(COLLOCATION),以及时间序列(TIME SERIES)的综合运用,可以对民国时期的文学和思想文献实施一种远、近交替的初步观察。例如,在检索条中输入“散文詩”一词,不仅可以看到语料库中全部包含该词的语句和段落,以及出现次数、出处和时间等信息,还可以找出使用该词最多的作者和刊物等元数据信息,以及三十年间和该词“共现”最多的词语及其相对频次;继而,如果将这些共现词汇的频次按照时序进行统计比较,可以发现1922年左右出现了一个高峰,很可能和当时发生在新文学阵营和旧体诗群体之间的散文诗笔战有关;最后,如果点击进去,则可以回到每一篇原文中,进行最详细的阅读。

元数据的搜集整理及分词工作(Metadata and Tokenization)
作者元数据的整理是团队正在积极完成的一项重要的工作。由于中国文学文献的语料库大多集中在版权公开的古典文学领域,且近代、现当代文学较少,而现有的数据库大多也只有原始的文本数据和内容,并未进行深度加工,因此,团队并不止步于呈现原始文档,而是将重点放在了对文献的进一步整理和标注上,为更深入的数字人文研究提供支撑。
在元数据的搜集整理方面,除了最基本的出版信息外,语料库一共有9,424个作者姓名,其中不少是笔名。目前进行了别名、假名、异体字消歧;分别考证作者的性别、生卒、国籍、籍贯、教育等信息。充分借助于现有工具书如《五四以来历史人物笔名别名名录》《民国人物大辞典》和 《20世纪中华人物名字号辞典》等,研究者从它们的电子版中提取相关信息,匹配了1,693个人,这些人一共发表了8,680篇文章,占语料库的36%。此外还找到了一千多位外国作家,其中大多数来自俄苏,美国,英国,法国和日本。剩下有大约5,000个名字需要辨认,通过调用API接口,可以连通上海图书馆人名规范库的资源。对这些元数据的收集整理无疑将会有助于文学、政治、印刷文化等领域的研究,它将使学者更广泛地了解到年代、性别、文化地理和教育等因素将如何具体而微地影响到体裁、写作风格、文学思想、语体特征等方面的演变趋势。
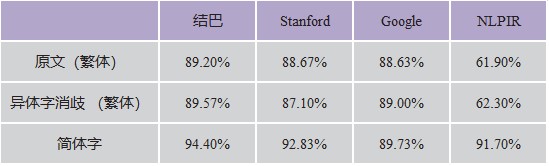
在分词方面,PhiloLogic4仍然需要以空格的形式来对所有语料进行最基本的语义划分。在比较了结巴、Stanford、谷歌和NLPIR四种分词系统在不同文类(诗歌、戏剧、评论)文本的运行结果后,实验室采用了结巴软件。这一环节仍然需要与一定量的人工消歧工作相配合才能最终完成。
表1. 四种分词工具的准确率对比
文类区分(Genre Classification)和文本重用(Textual Reuse)
此阶段的第二大工作是分类,即文类自动识别技术的研发。由于语料库涵盖整个民国时期期刊的各种主题和体裁,为了使学者能够更高效地找到与他们的研究问题相关的文章,团队进行了文类区分的工作。严格地说,文类区分仍然属于元数据标引的一部分,也成为富于实验性和探索性的开放环节。具体说来,即如果我们可以在一个相对宽泛的、文献的意义上承认“文学”的概念,并且认同在文类边界剧烈变动的近现代“转型”时期,文体形式上的韵散问题,和内容方面的写实、虚构问题已经构成了现代文学的核心问题,我们便可以尝试利用classification的一些主流手段或模式来对语料库其进行类型区分。再以个体化的研究经验,结合文学史上的既有结论去对“机读”的结果进行批评性的质询,从而形成“远读-细读-批评”的循环。截止目前,研究者已经初步设计出了针对一定量样本的诗歌/散文区分工具,而fiction/non-fiction的辨识工具还在从五个方案的路径上同时推进,也将有更多有意思的结果出现。
首先是诗歌与散文(Poetry/Prose)的区分。这一部分相对容易,但是同样凝结了开发者的智慧和心血。为了对总数超过24000篇文献进行分类,将其区分为“诗歌”和“散文”两大类,并给每篇文献派以相应的标签,在开始具体分类之前,需要先明确诗歌与散文的区别。近代诗体革命的特征可以从建行和跨行的形式特征中体现出来,经过反复观察,研究者决定单纯从文本的形态特征入手,以最少的参数来建立标准。首先是文本中每段(行)的平均字数。新诗比之古体诗,虽然在诗句的字数上有了明显增多的散文化特点,但是语句的长短却仍然远远小于散文,所以,当每行字数的平均数小于某个数值时,机器就有可能将其判定为诗歌。但是,仅依靠平均数是不够有参照性的——如果平均数较小但是每行字数的差异较大,便有可能依然是散文而非诗歌。为此研究者设置了第二个参数:每个文本中段落字数的标准差。根据这两个参数,便可以设计python算法,遍历了所有文本并计算出每个文本的段落平均字数和标准差,试图界定数个边界来判定诗歌和散文。最后,再针对诗歌和戏剧的易混性,以及算法不够完善的地方,设置人工校验程序,经过反复调试,将诗与散文较成功的区分出来。在语料库中,一共有3,509首诗,占语料库的14.5%。按照这种方法,区分结果的正确率达到了99%。
较难的一类区分工作是对小说的辨认。这个工作显然难以一步到位,于是任务被转化为了区分fiction和non-fiction,再根据现实情况随时降低难度,以迂回渐进的方式达到目标。团队成员分工合作,分别从三种方案上往前推进。第一种路径类似于诗歌文本的区分办法,是靠人工采集特征,编写表达式,观察结果,再不断调整。采集的特征点主要有对话引语的提示词和提示符、特定关键词出现的次数、引文的形态等等。而为了将主要混淆源“文艺评论”区分出去,也设定了相关的标准。经过一系列的程序调试,目前基本上已经可以将符合fiction标准的文本辨别出来。下一步的工作将是继续从fiction中区分戏剧剧本文类,将non-fiction分为小品文和政论,散文诗等亚文类。
第二种路径采用了LDA主题模型的做法,再配合以专门的赋分标准来做区分。即,使用比较流行的主题建模方法,先将语料全部分为20个主题并进行降维处理,发现最主要的成分,依据主题在此成分向度上的分布来设置算法,为每一篇文献打分,继而将之分派到fiction或non-fiction的相应区间。

第三种路径较复杂,主要采用了基于神经网络的机器学习的办法。研究者结合Keras和TensorFlow,设计了机器学习模型,有选择性地将具备高可能性的fiction/non-fiction的文章辨认出来。简单的说,先人为制造四种类型(虚构,非虚构,诗歌和文言文)。然后从24115篇文章中手动选择191篇文章(差不多每个类型下面50篇)作为TensorFlow的训练集。在对训练集(40000词表)进行标准化处理(包括分词,移除停用词以及非中文单词和符号等)和压缩降维后,将每篇文章的前100个词输入,构成张量的对象,用以建构模型。最后发现,这100个词已经足够将文章分为四类对应的文类了。如果将同样的训练数据用于效度检测并且评估预测,发现准确率大于88%。而只有当被预测为fiction或non-fiction中任一种文类的概率大于等于50%的文章,才会被选出来用于进一步的分析,如此便产生了4090篇“fiction”和2855篇non-fiction。这一方法的基本原理是基于次序模型(sequential modeling)的,本质上是线性层叠的,目的是为了用相对简单的模型,来从线性文本输入中抽取和压缩文本特征,而不采用过于复杂的计算。此外,尚在实验中的朴素贝叶斯模型和文本聚类(clustering)的方法都显得更有希望。总之,实验室已经采用了一系列的手动和机器学习方法来区分fiction和non-fiction,却尚未达到90%以上的分类准确率,但无论哪个方向上,都还存在继续探索的空间。

另外, 一直处于建设和更新中的一个重要的研究平台TextPAIR,利用基于N元语法的序列比对技术,从大量文献中找出“共享段落”。最能彰显其优势的项目叫“Commonplace Cultures”(“复述文化”或“共通文化”)[5],是跟牛津大学和澳大利亚国立大学合作的一个大型文献数据挖掘项目。[6]使用该平台,可以从ECCO(“18世纪作品在线”)的200,000多种文本中,共抽取出400万以上的“共享段落”,用以考察漫长的18世纪中某种“引经据典”的文化向自治性文化的范式转移。这一项目目前已经扩展到了18世纪之前的语料库(EBBO-TCP涵盖从15世纪末到17世纪末的早期现代时期)和更大范围的古典拉丁文献库,这两个语料库也可以作为比对语料库使用。如此,人们通过简单的搜索,便可以对历史上某个原典表述的传世和借用状况一目了然,某种程度上实现了跨语言文化的搜索。
这一项目也算是最能体现所谓“文本语文学”(Textual Philology)精髓的数字化项目。使用算法寻找相似性段落并经过电子校勘和版本消歧等步骤,可以将不同原典中具有相同或相似用词的字符串及其后世“变体”——长度从几个字至完整段落,即时关联、再现出来。通过比对差异,不仅可以获得作为校勘“证据”的原典表述的流传线索——在发现最高重现段落后,可以找出该段落的高频重用者和最高重用时段,以及它们的分布状况,将一个跨时空的互文网络瞬间展现出来;还可以发现经典之外更广泛存在的文本重现模式(例如,来自《圣经》的引用占据16和17世纪英国文学所有类似段落的70%以上,占18世纪的一半以上,ARTFL已经设计了段落识别算法,从非常高频率的文本或作者中过滤掉了重复使用的内容,从而促进了对“可见度”较低的文本的识别,这些流行文本更能说明重复使用的重要模式)。利用一系列专门算法,研究人员也对ECCO本身进行了压缩,就像是制作了一个超大型文库的精校精编本,据此人们是可以实施更精确的“文献批评”(Textual Criticism)工作的。此工具经过一系列针对汉语文本的修订和改进,也将植入民国时期期刊语料库,使用这一工具,可以从现有汉语语料中找到3,704条重要的共享段落,这些段落将为进一步深入了解民国时期思想文化观念的发展流变提供宝贵信息。



注 释:
[1] https://textual-optics-lab.uchicago.edu/
[2] https://lucian.uchicago.edu/blogs/literarynetworks/
[3] http://artfl-project.uchicago.edu/
[4] http://commonplacecultures.org/?page_id=259
[5] 这里取“述而不作”的意思。
[6] 此项目的算法设计和开发工作较为繁复,而且具有极强的问题和针对性,具体步骤详见http://commonplacecultures.org/?page_id=291
编 辑 | 桑海 邓曼兰
原刊《数字人文》2020第一期, 转载请联系授权。