

作者:徐嘉泽 潘长在 贺莉丽 王宏甦 张力伟 邓 柯;转自:公众号 DH数字人文
基础设施

徐嘉泽 / 清华大学统计学研究中心
潘长在 / 清华大学统计学研究中心
贺莉丽 / 清华大学古典文献研究中心
王宏甦/ 中国历代人物传记资料库
张力伟 / 清华大学古典文献研究中心
邓 柯 / 清华大学统计学研究中心
———————————————-
摘 要: 大量数字化古代汉语文本资源的出现对其分析工具产生了巨大需求。作为一种基于统计模型的无监督中文文本分析方法,TopWORDS在针对古代汉语文本的词语发现和信息提取问题方面具有应用前景。本文介绍了TopWORDS方法的基本原理、工作流程以及特点和优点,并将其应用于《汉书》和《明史》这两部古籍的词语发现,且以相关古籍的人名及地名索引为标准对TopWORDS方法抓取古文献中专有名词的能力进行了量化评估和比较。相关结果证明了:TopWORDS在古代汉语文本分析中具有较强的专名抓取能力,有潜力在未知专名识别和专名索引快速构建方面发挥重要作用。
关键词: 词语发现 无监督学习 中文分词
———————————————-
引言
随着数字人文研究的兴起,越来越多的古代汉语文本资源得以数字化。这为古代汉语分析提供了极大便利,同时也对相应的数字化分析工具产生了巨大的需求。与现代汉语不同,古代汉语有着诸多独具的特点,对文本分析带来了许多新的挑战。首先,古代汉语文本的行文风格、用词特点、语法结构等与现代汉语有着显著的差异。其次,对大量的古文献而言,专名词库和索引还很不完整。再次,针对古汉语的语料库和训练数据到目前为止仍十分有限,针对特定时代的训练语料尤为稀缺。面对这些挑战,开发高效精准的人工智能方法,从古文献中自动化地提取词汇和短语,并快速构建专有名词词库和索引,对大规模古文献研究有着十分重要的意义[1]。
在中文文本分析中,词语发现方法主要包括有监督方法和无监督发现方法两大类。有监督词语发现方法需要有标注的训练语料数据进行模型训练,主流是基于统计学习的条件随机场方法[2]和深度学习[3]的方法。而无监督的词语发现方法不依赖于训练语料库,而是从文本自身挖掘并提炼信息,善于抓取目标文本中的显著信号,具有良好的适应性和稳定性。常见的无监督方法基于互信息准则[4]、假设检验[5]和统计模型[6]等。半监督方法在特定场景下也有一定的适用性,如人机交互式的分词方法[7]。有监督方法通常是根据现代语料库如新闻、百科等训练而成,适用于现代汉语。由于古代文本与现代汉语有着不同的风格和结构,且分析时常常难以获得相关的词语列表和语料库,大部分有监督方法应用于古文文本分析时其效果会大打折扣,无监督词语发现方法在这种情况下反而有一定的优势[8]。
在本文中,我们主要使用无监督词语发现方法TopWORDS[9]为主要工具来展开古文献关键词提取和专名识别研究。
TopWORDS方法以统计词典模型和模型选择技术为基础,在词语发现方面表现优异,能在无输入词库和训练语料的情形下有效地处理包含大量未知专业语汇的中文文本,对于古汉语分析领域来说尤为合适。在TopWORDS方法给出的词语发现结果的基础上,结合一定程度地手动分类和筛选,可以快速地进行专名识别。这一策略比直接从原始文本中人工识别专名要容易操作得多,效率也高得多。本文介绍了TopWORDS方法的基本原理、工作流程和特点及优点,并将其应用于《汉书》和《明史》这两本古籍的词语发现,且以相关古籍的人名及地名索引为标准,对TopWORDS方法抓取古文献中专有名词的能力进行了量化评估和比较。相关结果证明: TopWORDS在古代汉语文本分析中具有较强的专名抓取能力,有潜力在未知专名识别和专名索引快速构建方面发挥重要作用。
一、中文词语发现和分词方法介绍
在这一节中,我们将介绍五种有监督的词语发现和分词方法以及一种无监督的方法。我们在后续章节中将这些方法应用在两部古籍文献中进行词语发现,并评估它们的表现。
(一)有监督方法
有监督的方法需要高质量且大量的训练语料和预先给定的词库,在统计学习和机器学习的模型框架下进行学习,在目标文本与训练语料高度相似的封闭测试中能达到非常精准的词语发现和分词效果。训练语料库中的文本需要人工进行切分和分词标注,耗时耗力。在面对有多种可能的切分预测结果时,模型通过对所有的情况进行统计推断,在一定的准则下选择最优的预测结果。当目标文本的结构、风格、用词频率与训练文本相同或接近时,这些方法通常表现得很好。但是,当目标文本中的实际用词含有未包含于预先给定词表中的词汇时,特别是当目标文本的写作风格和主题与训练语料库有很大不同时,有监督的方法往往无法识别其中许多未登录的词汇[10]。
我们使用目前流行的五种有监督分词方法来进行测试。它们是THU Lexical Analyzer for Chinese (THULAC)[11]、PKUSEG[12]、语言技术平台(Language Technology Platform, LTP)[13]、Stanford NLP[14]和“结巴”中文分词(JIEBA)[15]。它们都是开源免费的软件,而且易于下载和使用。
THU Lexical Analyzer for Chinese (THULAC)是2016年由清华大学自然语言处理与社会人文计算实验室研发出的中文词法分析工具包,包含分词和词性标注功能。它通过5,800万字的中文标注语料库训练而成,具有能力强、准确率高和速度较快的优势。
PKUSEG是2019年由北京大学语言计算与机器学习研究组开发的中文分词工具。该算法基于条件随机场模型,可以进行不同领域的中文分词。在使用相同训练数据和测试数据的条件下,PKUSEG有着比其他方法更高的分词准确率。它还支持用户自训练模型和词性标注。
语言技术平台(Language Technology Platform, LTP)是由哈尔滨工业大学社会计算与信息检索研究中心历时十年开发的中文语言处理工具,在2011年开源。它涵盖了词法、句法、语义等中文处理功能。LTP分词模块通过最大正向匹配方法得到词特征,并将其融合到词典中来进行统计推断和分词任务。
Stanford NLP是由斯坦福自然语言处理团队开发的分词方法,可以处理多种语言的分词任务。该方法可以找到汉语句子的语法结构,并借此进行分词。
“结巴”中文分词(JIEBA)是非常优秀的开源分词算法,有十多种不同的编程语言版本。该算法运用动态规划方法找到最大概率的切分组合路径,并用隐马尔可夫链模型处理未登录词。该方法是通过大量的人民日报语料库训练得到的。
(二)无监督方法
无监督方法不依赖于已标注的词语列表,也不依赖于由已切分的训练文本构成的训练语料库。传统的无监督方法主要基于N元组(N-gram)、词语频率、互信息准则和假设检验等[16]。基于N元组和词频的方法对文本中的高频词语进行提取,但是忽略了构成词语的字符之间结合关系的显著性。互信息准则对其做了一定的改善,计算联合分布词频的同时,还利用边缘分布进行了归一化和标准化,有效地刻画了字符结合的紧密程度。基于假设检验的方法,如t检验、卡方检验、似然比检验等,设计出可以衡量字符结合程度的指标,根据检验统计量的数值大小来判断切分与否。基于互信息准则和假设检验的方法都是对文本的局部进行建模,缺少全局的统计模型,还需要对阈值的选取进行额外的选择。另外,它们难以提取文本中的多音节词语和短语。
TopWORDS方法[17]于2016年发表在《美国科学院院刊》(PNAS),是近年来无监督词语发现和中文分词研究的重要进展之一。该方法可以在不需要任何训练语料的情况下进行词语发现、中文分词,并对学习到的词语按照可信度进行排序。它从目标文本自身中进行信息提取和学习,并利用统计推断和模型选择技术,在处理具有很强专业性的中文文本时有着非常好的效果。如果研究者提供预先标定的词语列表或训练语料等先验知识,TopWORDS方法也可以很容易地把这些先验知识加载到算法中,以进一步提升方法的稳定性和准确率。和其他的无监督方法相比,TopWORDS方法所运用统计模型和分析技术从全局而非局部的视角对中文文本进行建模与分析,新词发现的能力和精准度有大幅度的提高。
1.WDM模型介绍
TopWORDS基于词典模型(word dictionary model, WDM)。设文本中的词语组成的词典为

其对应的词频为
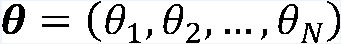
WDM考虑一个生成模型,通过有放回随机抽样的方式,对切分的句子进行建模。对于一个包含M个词语的句子
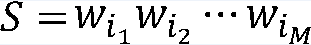
WDM给出的S的生成概率为
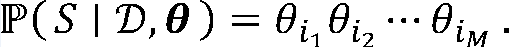
我们考虑一个未切分的句子T,设S(T|D)为(在词典D的条件下)句子T的所有可能的切分所构成的集合。那么,WDM给出的T的生成概率为
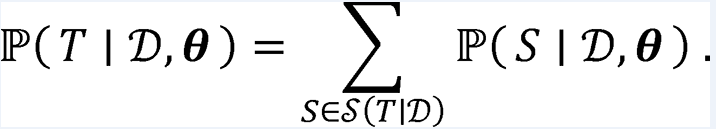
于是,我们可以对文本进行切分,通过计算条件概率
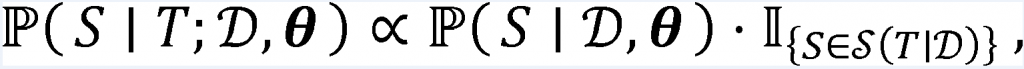

表1 词典D和词频θ的示例

下面我们举一个简单的例子来展示上述计算过程。表1中给出了词典D和词频θ的示例。词典D包含6个词语,其中有4个单音节词和2个多音节词。单音节词的词频比较高,都是0.2;多音节词的词频相对较低,为0.1。我们考虑一个未切分的句子T=“王安石为参知政事”。(在词典D的条件下)T有两种切分可能,分别为S1=“王安石|为|参知政事”和S2=“王|安|石|为|参知政事”。根据WDM,我们可以计算出S1的生成概率为P(S1|D,θ)=0.1×0.2×0.1=0.002,S2的生成概率为P(S2|D,θ)=0.2×0.2×0.2×0.2×0.1=0.00016。所以,两个已切分的句子S1和S2在观测数据为T的条件下,条件概率分别为
P(S1|T;D,θ)=0.002/(0.002+0.00016)≈0.926
和
P(S2|T;D,θ)=0.00016/(0.002+0.00016)≈0.074
也即T是由S1生成的可能性为92.6%,由S2生成的可能性为7.4%。我们选择可能性较大的S1作为T的切分结果。通过这个选择过程,我们可以发现,对于一个未切分的句子T,切分的次数越少,切分后的句子S中的词语个数就越少,其生成概率就可能越大(因为乘积的项数少)。选择生成概率大的切分,就可以对文本进行有意义的词语提取。另一方面,对T的切分的次数少,就使得S中的词语个数少,词语平均长度会增加,即多音节词出现的次数会变多。而多音节词的词频是相对较低的。所以切分的次数太少也可能会导致生成概率变低。这就使得模型在两个方向之间进行权衡,进而选择一个最有意义的切分结果。
2.TopWORDS流程介绍
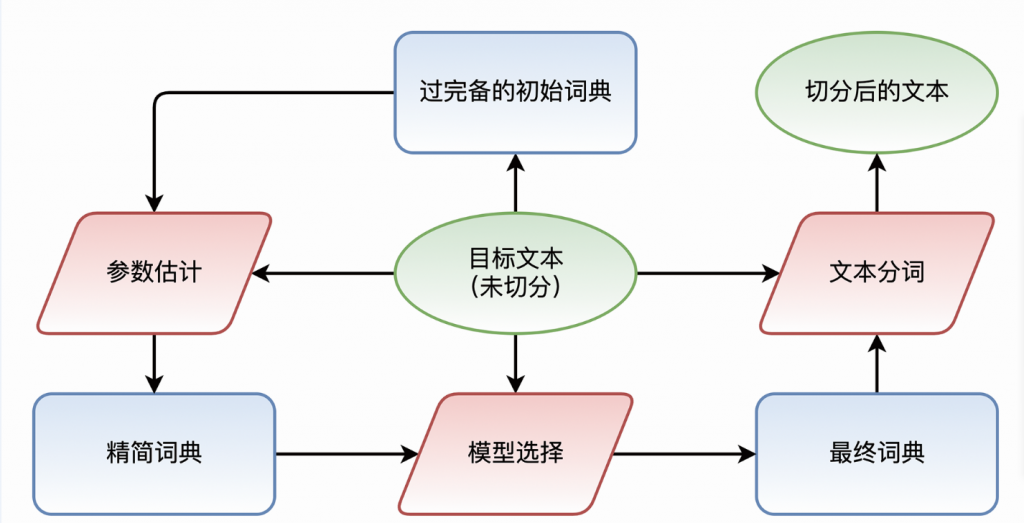
注:绿色椭圆形代表文本相关的模块,红色平行四边形代表算法操作模块,蓝色圆角矩形代表词典相关的模块。“目标文本”是方法的输入;“最终词典”和“切分后的文本”是方法的输出。

3.TopWORDS的优势和特点
TopWORDS方法作为无监督中文文本分析的工具有以下几个特点和优势。首先,它可以在没有输入词库和训练语料时,以无监督式学习的方式从目标文本中自动提取词汇,还可以有效地发现并识别低频的词语和短语。这使得它在处理包含大量未知专业语汇的中文文本时有明显的优势(尤其是训练语料较少的情况)。其次,它可以快速高效地进行中文文本分词。最后,它使用了词频和显著性得分两种指标对词语进行排序,方便学者进行审查并进行深入的探索和分析。
二、实例分析
我们选取了《二十四史》中的两部史书《汉书》和《明史》来进行实例分析。《汉书》是中国第一部纪传体断代史;《明史》是《二十四史》的最后一部,其卷数在《二十四史》中仅次于《宋史》。两部史书在史学研究中均具有重要的代表意义。在使用TopWORDS方法时,我们以未标注、非结构化但经过了文字清洗的《汉书》(王先谦补注本白文)和《明史》(武英殿本)文本用作算法的输入。为评估多种方法的词语发现结果,我们使用与两部史书相配套的三本索引《汉书人名索引》《汉书地名索引》和《明史人名索引》作为评价标准,对人名、地名等实体的挖掘率进行计算,从而展示不同方法在词语发现问题上的成效。相关史书和索引均采用中华书局的经典版本,数据质量可靠。
(一)实体频数
我们使用有专名标注的中华书局标点本《汉书》和《明史》来计算实体在文本中出现的次数。我们定义一个词的实体频数为该词语在标点本中被标注为一个实体的频数,而不是这个词作为字符串在文本中所出现的频数。例如,字符串“君之”在《汉书》的文本中出现了73次,但它作为一个人名在标点本中只出现3次。我们把“君之”的实体频数记为3。再例如,字符串“魏忠”在《明史》文本中出现248次,其中只有1次是作为人物“魏忠”出现在文本中,其余247次都是作为词语“魏忠賢”的子字符串出现在文本中。我们把“魏忠”的实体频数记为1。由于两部史书中均有一部分篇目中的专名是独立呈现的词语,如王侯功臣表以及地理志、艺文志等,而我们的方法主要应用于从正文文本的自然语言中提取词语,因此未将这部分数据放入验证分析中。
(二)《汉书》人名、地名识别
1.数据介绍
《汉书》是一部纪传体史书,主要记述了自西汉高祖元年(公元前206年)至新朝王莽地皇四年(公元23年)共229年的史事,包括本纪12篇、表8篇、志10篇、传70篇,共100篇。全文约70万字,使用了约5,500个不同的汉字。
为评估不同方法对《汉书》的词语发现结果,我们选取《汉书人名索引》和《汉书地名索引》作为评估标准。《汉书人名索引》包含了9,574个人名,其中3,923个人名在标点本中被标记成专名,这些人名的实体频数至少为1。其余5,651个人名没有在分析文本中出现,应当是出自被省略的类聚专名的表志之中。《汉书地名索引》包含了4,825个地名,其中有3,282个在标点本中被标记成专名。我们把人名和地名统一称作实体,那么两本索引一共包含了14,281个实体,有118个实体既可作为人名,又可作为地名。图2给出了原始数据以及转换后数据的样例,其中的实体频数通过索引中的词语列表以及文本中的专名标注可以计算得出。
2.实验结果


注:原始数据文本中的下划线为手动标注的专名。索引以主要称谓作为主目。其他称谓附在括号里,并在索引中单独成为条目,作为参见其主要称谓的条目。

3.结果评估
我们把TopWORDS方法得到的结果和索引进行对照和验证。通过计算索引中有多少比例的实体被算法学习到,得到实体的“挖掘率”(在统计学习和机器学习领域也被称为“召回率”或“recall”)。直观上来说,在文本中出现次数越多的词语,更容易被算法学习到。我们对不同实体频数的实体分别计算挖掘率。
TopWORDS算法给每个词语计算了显著性得分。显著性得分表示一个字符串在模型中被识别为一个词语的置信程度。显著性得分高的词语,对模型的影响程度较大,在算法的运算过程中,越有可能被保留下来,作为置信度高的词语保留在最终词表中。显著性得分低的词语,对模型的影响程度较小,在算法的运算过程中,可能会在模型选择步骤中被筛掉,不被算法识别为一个词语。我们把算法学到的词语按显著性得分排序,选取不同的阈值对词表进行截断,得到显著性得分最高的前K个词语。通过计算这K个词语中,包含了多少比例的人名和地名,得到实体挖掘率,并通过折线图来对比不同实体频数下的结果。图4(a)给出了不同实体频数以及不同截断阈值下人名挖掘率的折线图。每条折线表示特定实体频数下的人名挖掘率。实体频数高的折线大体上都在实体频数低的折线的上方,也就是说,实体频数高的人名越容易被挖掘到。在每条折线中,随着对显著性得分的截断阈值的降低,选取的词语个数增加,人名的挖掘率也会随之增加。折线上的一个点表示显著性得分最高的前K个词语中,包含了多少比例的特定实体频数下的人名。例如,显著性得分最高的前60,000个词语,包含了90%以上的实体频数为4的人名。图4(b)给出了不同实体频数下的人名个数和人名挖掘率。这里考虑的是TopWORDS算法学习到的78,844个词语,包含了多少比例的不同实体频数的人名,也即图4(a)中每条折线右端终点的情况。随着实体频数的增加,人名个数减少,但挖掘率增加。例如,实体频数为3的人名有343个,算法找到了其中的316个,挖掘率为92.13%;实体频数为10的人名有38个,挖掘率为100%。
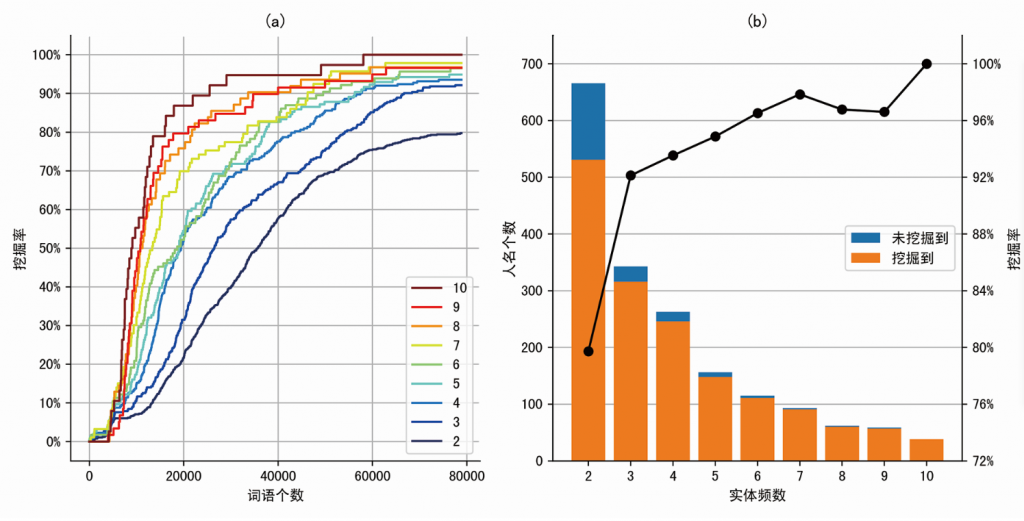
注:(a)不同实体频数的人名挖掘率。根据不同的截断阈值,横轴是截断后的词表的词语个数,纵轴是相应的挖掘率。(b)不同实体频数下的人名个数(柱状图)和人名挖掘率(折线图)。
表2给出了TopWORDS方法以及其他五种有监督方法的人名挖掘率结果。从表中数据我们可以看出:各有监督方法在不同实体频数下人名的挖掘率均比TopWORDS方法低很多;尤其是对于低频的人名,有监督的方法的表现效果较差,许多低频人名都没有找到。其中,实体频数大于等于3的人名一共有1,582个,TopWORDS方法学习到了其中的1,519个人名,挖掘率为96.02%。实体频数大于等于10的人名一共有491个,TopWORDS方法学习到了其中的490个人名,挖掘率为99.80%;未找到的人名是“王鳳”(实体频数是32),由于这个词在文本中几乎总是和官职或别名等其他词语一起出现而形成固定搭配的词组,例如“大將軍王鳳”和“陽平侯王鳳”等,TopWORDS方法成功地学习到了这些词组,但将单词“王鳳”遗漏了。从表中我们还可以看到:各有监督方法得到的词语个数比均比TopWORDS方法更多,但是其中包含的各类专名个数反而更少。这说明:TopWORDS方法与各有监督方法相比,在专名识别上具有更高的“精确率”(precision)。
表2 《汉书》人名挖掘率

图5(a)给出了不同阈值下地名挖掘率的折线图。实体频数高的地名越容易被挖掘到。显著性得分最高的前60,000个词语,包含了90%以上的实体频数为3的人名。图5(b)给出了不同实体频数下的地名个数和地名挖掘率。随着实体频数的增加,地名个数减少,但挖掘率增加。
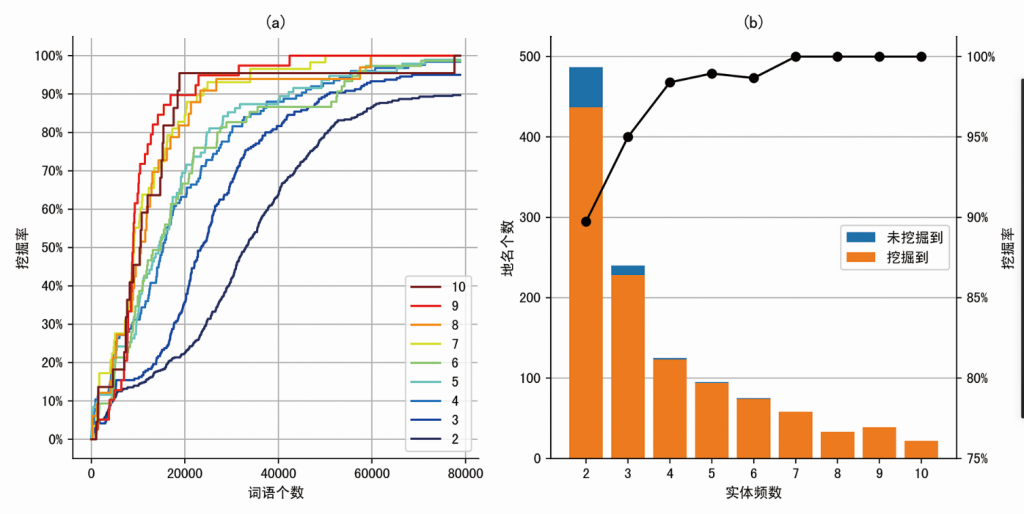
注:(a)不同实体频数的地名挖掘率。根据不同的截断阈值,横轴是截断后的词表的词语个数,纵轴是相应的挖掘率。(b)不同实体频数下的地名个数(柱状图)和地名挖掘率(折线图)。
表3 《汉书》地名挖掘率
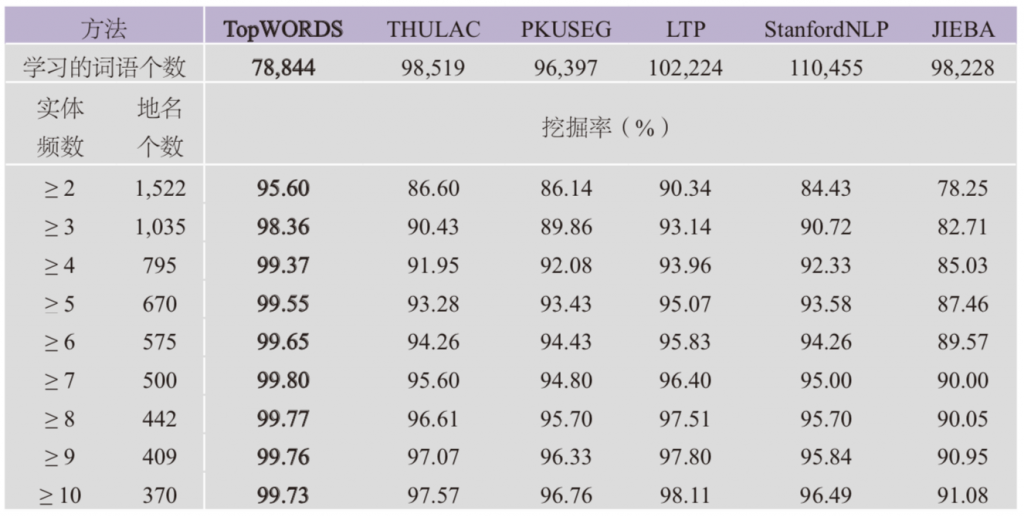
表3给出了《汉书地名索引》中不同实体频数下地名的挖掘率。TopWORDS方法的地名的挖掘率比其他有监督的方法要高一些。实体频数大于等于3的地名一共有1,035个,TopWORDS方法学习到了其中的1,018个地名,挖掘率为98.36%。实体频数大于等于10的地名一共有370个,算法学习到了其中的369个地名,挖掘率为99.73%,未找到的地名是“石渠”。它在文本中出现15次,实体频数为13,其余两次是作为地名“石渠閣”的子字符串出现在文本中。这个词在文本切分的结果中,大都包含在“論石渠”“於石渠”等词语中。
地名的识别率比人名识别率相对高一些。一是因为一些地名也会出现在其他语料中。有监督的方法会使用这些语料库进行训练,有能力对这些词语进行提取和识别。二是因为地名的独立性较高,与其他词语的结合性较低,而地名的字符之间的结合率较高,使得地名更容易被算法提取到。
(三)《明史》人名识别
1.数据介绍
《明史》是《二十四史》的最后一部,记载了自明太祖朱元璋洪武元年(1368年)至明思宗朱由检崇祯十七年(1644年)共277年的明朝历史。我们所分析的文本是《明史》的本纪24卷、志75卷、列传220卷,共319卷的文本,不包括表13卷。全文共约270万个汉字,使用了约7,000个不同的汉字。
《明史人名索引》包含了28,948个人名,其中有22,135个人名在标点本中被标记成专名,这些人名的实体频数至少为1。其余6,813个人名没有在分析文本中出现,应当是出自被省略的类聚专名的表志之中。
2.实验结果


3.结果评估
我们比较《明史人名索引》中的人名列表和TopWORDS算法给出的结果来进行评估。我们对TopWORDS算法学到的约24.8万个词语按显著性得分排序,设定不同的阈值对词表进行截断,得到显著性得分最高的前K个词语,并计算在这K个词语中的人名挖掘率。图7(a)给出了不同实体频数以及不同截断阈值下人名挖掘率的折线图。实体频数高的人名越容易被挖掘到。显著性得分最高的前20万个词语,包含了90%以上的实体频数为4的人名。图7(b)给出了不同实体频数下的人名个数和人名挖掘率。随着实体频数的增加,人名个数减少,但挖掘率增加。

注:(a)不同实体频数的人名挖掘率。根据不同的截断阈值,横轴是截断后的词表的词语个数,纵轴是相应的挖掘率。(b)不同实体频数下的人名个数(柱状图)和人名挖掘率(折线图)。
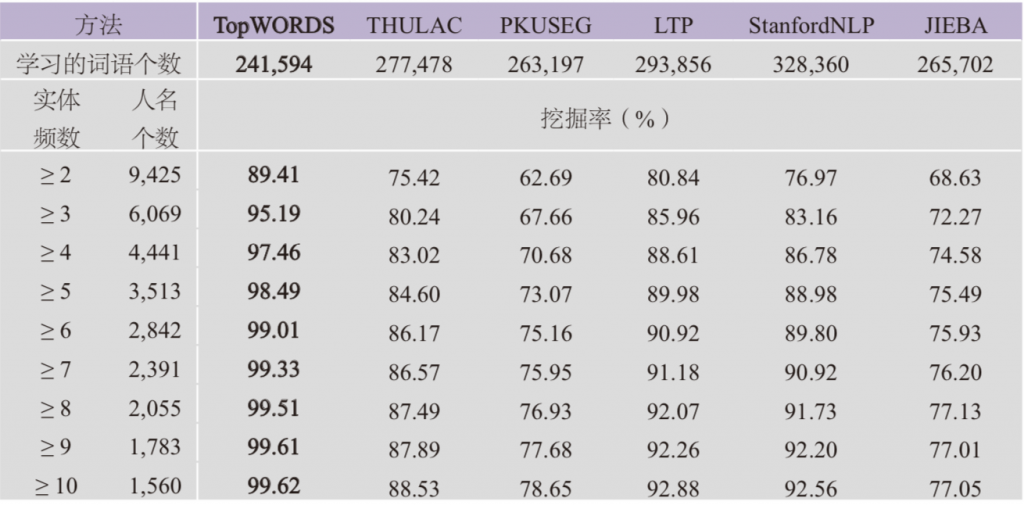
不同实体频数的人名挖掘率由表4给出。TopWORDS算法学习到的词语个数比其他五种有监督的算法少,但是人名挖掘率却显著地比其他方法高。实体频数大于等于3的人名共6,069个,其中有5,777个被TopWORDS算法从文本中学习到,挖掘率为95.19%。实体频数大于等于6的人名共2,842个,其中有2,814个人名被TopWORDS学习到,挖掘率为99.01%,超过99%。实体频数超过10次的人名中,有4个人名没有被TopWORDS算法挖掘出来。它们分别是“安遠侯”“寧陽侯”“恭順侯”和“撫寧侯”。算法虽然没有直接识别这些人名,但是却挖掘出了与之指代的人物本名结合在一起的名词短语,例如“安遠侯柳溥”“安遠侯柳升”“寧陽侯陳懋”等,这些词蕴含了更明确的指代信息。
表4 《明史》人名挖掘率
总结
本文介绍了基于无监督学习的中文词语发现和分词方法TopWORDS以及另外五种基于有监督学习的竞争方法,并将这些方法应用于两部古籍《汉书》和《明史》的词语发现和专名识别中。通过与权威的人名、地名索引相比较,我们发现TopWORDS方法在古籍专名识别中有着显著的优势:对于实体频数大于等于3的人名或地名,超过了95%的挖掘率;对于实体频数大于等于10的人名或地名,超过了99.6%的挖掘率;极少数未直接识别的人名,算法则找到了包含该词语的具有更详细信息的短语。相关结果一致地优于其他方法,在大多数情况下高出10个百分点左右,在比较困难的《汉书》人名挖掘任务上则有超过20个百分点的性能提升。
上述结果说明:在没有输入词库和训练语料库的情况下,TopWORDS方法可以高效准确地从古文献中识别专有名词。在目标文献专名索引尚未建立的情况下,上述基于TopWORDS方法的分析策略可以在少量人工干预下快速构建专名索引,从而极大地提高人文研究的工作效率。如果我们把视野放宽,以TopWORDS方法产生的结果为基础,生成相应的词库,并做出必要的整理,或许能为解决古汉语自然语言处理(NLP)的瓶颈——文言分词技术提供了一条有价值的通途。
(衷心感谢北京智源人工智能研究院对本文的支持。)
—————————————————————————————————————————————————————————————
Recognition of Technical Terms in Ancient Chinese Texts via TopWORDS Method:Take The Book of the Han and The History of the Ming as Examples
Xu Jiaze, Pan Changzai, He Lili, Wang Hongsu, Zhang Liwei, Deng Ke
Abstract: The appearance of large amounts of digital ancient Chinese text resources creates great demands for corresponding analysis tools. As an unsupervised Chinese text analysis method based on a statistical model, TopWORDS has application prospects for word discovery and information extraction in ancient Chinese texts. This paper introduces the basic principle, working process, characteristics and advantages of the TopWORDS method, applies it to the word discovery of two ancient books, The Book of the Han and The History of the Ming, and quantitatively evaluates and compares the capabilities of extracting technical terms in ancient documents based on name and address indexes as standards. Related results prove that TopWORDS has a strong ability to extract technical terms in ancient Chinese text analysis, and has the potential to play an important role in recognizing out-of-vocabulary technical terms and rapidly constructing indexes of proper nouns.
Keywords: Word Discovery; Unsupervised Learning; Chinese Word Segmentation
—————————————————————————————————————————————————————————————
编 辑 | 严程
*本文为国家自然科学基金(11771242)和国家社会科学基金重大项目“基于大数据技术的古典文学经典文本分析与研究”(18ZDA238)阶段性成果。
注释:
[1]陆宇杰、许鑫、郭金龙:《文本挖掘在人文社会科学研究中的典型应用述评》,《图书情报工作》2012年第8期。
[2]Fuchun Peng, Fangfang Feng and Andrew McCallum“, Chinese Segmentation and New Word Detection Using Conditional Random Fields,”in Proceedings of the 20th International Conference on Computational Linguistics(COLING), 2004, pp. 562-568;梁社会、陈小荷:《先秦文献〈孟子〉自动分词方法研究》,《南京师范大学文学院学报》2013年第3期。
[3]T. Xie, B. Wu and B. Wang“, New Word Detection in Ancient Chinese Literature,”Asia-Pacific Web (APWeb) and Web-Age Information Management (WAIM) Joint Conference on Web and Big Data, Springer, Cham, 2017;刘昱彤等:《基于古汉语语料的新词发现方法》,《中文信息学报》2019年第1期。
[4]Z. Liang et al.“, Chinese New Words Detection Using Mutual Information,”Trustworthy Computing and Services, vol. 320 (Berlin, Heidelberg: Springer Berlin Heidelberg, 2013), pp. 341-348.
[5]段磊、韩芳、宋继华:《古汉语双字词自动获取方法的比较与分析》,《中文信息学报》2012年第4期,第34—43页。
[6]Ao Chen and Maosong Sun,“Domain-Specific New Words Detection in Chinese,”in Proceedings of the 6th Joint Conference on Lexical and Computational Semantics (*SEM 2017), Vancouver, Canada: Association for Computational Linguistics, 2017, pp. 44-53.
[7]李斌、陈小荷:《面向中文陌生文本的人机交互式分词方法》,《中文信息学报》2007年第3期。
[8]欧阳剑:《面向数字人文研究的大规模古籍文本可视化分析与挖掘》,《中国图书馆学报》2016年第2期。
[9]Ke Deng, Peter K. Bol, Kate J. Li and Jun S. Liu“, On the Unsupervised Analysis of Domain-Specific Chinese Texts, ”Proceedings of the National Academy of Sciences, vol. 113, no. 22, 2016, pp. 6154-6159.
[10]Ke Deng, Peter K. Bol, Kate J. Li and Jun S. Liu“, On the Unsupervised Analysis of Domain-Specific Chinese Texts, ”Proceedings of the National Academy of Sciences, vol. 113, no. 22, 2016, pp. 6154-6159.
[11]孙茂松等:“THULAC:一个高效的中文词法分析工具包”(2016),http://thulac.thunlp.org/。
[12]Ruixuan Luo et al.,“PKUSEG: A Toolkit for Multi-Domain Chinese Word Segmentation, ” arXiv:1906.11455 [cs], 27 Jun. 2019, http://arxiv.org/abs/1906.11455.
[13]Wanxiang Che, Zhenghua Li, Ting Liu“, LTP: A Chinese Language Technology Platform, ”in Proceedings of the Coling(2010)Demonstrations, Beijing, China, 2010, pp. 13-16.
[14]Manning, Christopher D., et al.,“The Stanford CoreNLP Natural Language Processing Toolkit,” Proceedings of 52nd Annual Meeting of the Association for Computational Linguistics: System Demonstrations 2014.
[15]See https://github.com/fxsjy/jieba.
[16]罗盛芬、孙茂松:《基于字串内部结合紧密度的汉语自动抽词实验研究》,《中文信息学报》2003年第3期;孙茂松,肖明、邹嘉彦:《基于无指导学习策略的无词表条件下的汉语自动分词》,《计算机学报》2004年第6期。
[17]Ke Deng, Peter K. Bol, Kate J. Li and Jun S. Liu“, On the Unsupervised Analysis of Domain-Specific Chinese Texts,”Proceedings of the National Academy of Sciences, vol. 113, no. 22, 2016, pp. 6154-6159.
原刊《数字人文》2020年第2期,转载请联系授权。