

作者:霍伊特·朗 刘凯(译);转自:DH 数字人文

霍伊特·朗/美国芝加哥大学东亚系
刘 凯(译)/四川大学外国语学院
编者按:
美国芝加哥大学东亚系霍伊特·朗教授为本刊编委,他于2021年六月在美国哥伦比亚大学出版社出版了The Values in Numbers: Reading Japanese Literature in a Global Information Age(《数字的价值:在全球信息化时代解读日本文学》)一书,以数字人文的方法深入讨论日本近现代文学文化。本刊邀请到四川大学外国语学院从事日本文学研究的刘凯老师作为译者,陆续译出此书部分章节,并在本刊刊出,以飨读者诸君,希望能以此来推动国内数字人文文学研究的进展。
—————————————————————————————————————————————————
要将青空文库理解为过往文学的一个样本,首先需要对散文体虚构作品进行细分。那些最初看起来很庞大的文本数量(删除重复项后约14,300个)遮蔽了它们之间多样且普遍的差异。[1]根据日本十进分类法(Nihon Decimal Classification,简称NDC)为每一个文本指定的主题代码可知,该文库的近40%(5,575个文本)为小说作品。在这个类目之中,有近20%(1,134个文本)被进一步归类为青少年小说。其次较大的类目有随笔和评论(占26%,3,695个文本)、诗歌(占10%,1,425个文本)、戏剧作品(占4%,612个文本)以及社会科学文献(也占4%,611个文本)。最后占比最低的类目有历史、书信、日记、美学、宗教和哲学,它们占文库总量的3%或更少。总体而言,该文库呈现了856位独特作家的作品,涵盖了早至与古希腊萨福(公元前630—580年)同时代的诗人和晚至1930年代出生的作家,他们中的大多数人(60%以上)出生于19世纪后半叶。
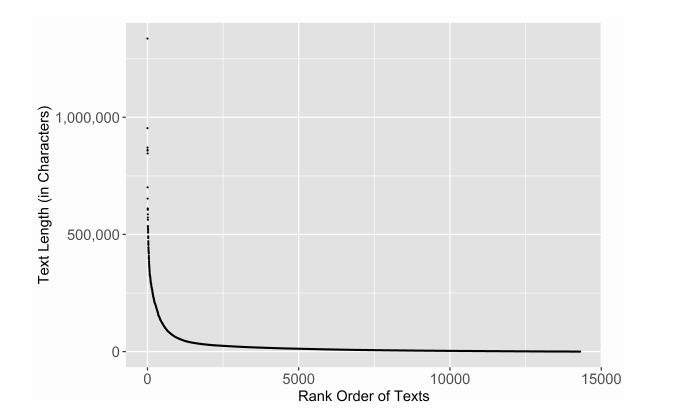
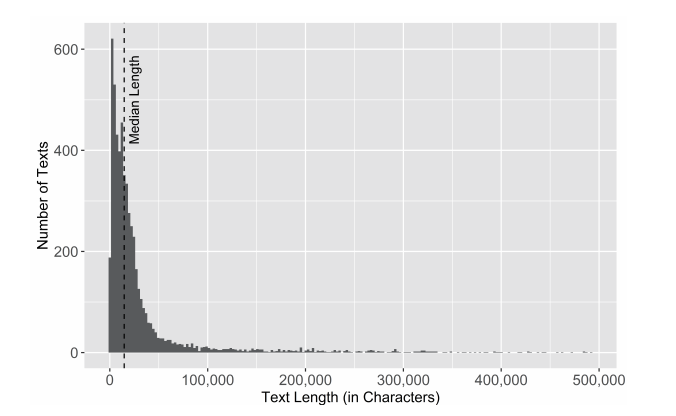
文本长度(text length)是揭示该文库多样性的另一个特征。就那些对散文体虚构作品(无论是长篇小说还是短篇故事)分析感兴趣的人而言,青空文库这面镜子可以迅速地将众多作品缩小到仅有几页印刷文本。处在分布图最末端的是宫本百合子的史诗性小说《路标》,这是一部创作于战后不久的半自传体作品,还有处在另一端的萩原朔太郎的一首俳句“从以色列归来,我独自站在雪地上”。我们按照字符长度对作品进行整理归类,并据此绘制总体分布图。可以看到,俳句远比其他文类更能体现该文库的文本长度特征(图1)。为更加精确地理解这一点,我们可以通过计算平均数(average)[2]、平均值(mean)或文本长度来观察分布在中间值(middle)的是什么。接近于平均数的是林芙美子的《下町》,这是一部战后的经典短篇小说,其文库本篇幅长达23页。不过,鉴于平均数对《路标》等异常值的敏感性,它有可能会是“中间值”(middle)的一个误导性标记,而且《路标》比次一级最长文本要长30%。另一个用来标示分布情况的中间值(middle)的统计方式是中位数(median),它是将观测值的上半部分与下半部分做出区分的点。此处文本长度的中位数约为平均数的三分之一,或者相当于宫泽贤治的儿童故事《月夜的电线杆》的长度,该故事的文库本篇幅只有9页。[3]如果仅选择将“虚构”作品的文本长度的分布情况绘制成直方图(图2),那么它们大部分仍然趋向于较短,而且文本长度的中位数大致介于《下町》(20,036)和《月夜的电线杆》(6,878)之间。这种趋势反映的是,长篇虚构作品在日本历史上并不那么占主导地位,而不是青空文库的志愿者们更偏爱短篇作品。
短篇作品的主导地位提醒我们注意,日本的叙事性虚构作品采用了一种特殊的本土形式,而且它同时受到了来自其他地区思想的影响,但也绝不仅仅是对这些思想的简单模仿。翻译在这个影响与发展的过程中起到了至关重要的作用,而且也的确有一个早就让人习以为常的观点,即认为大约1890年之后的日本现代文学史同时也是“用日语书写的西方文学”的历史。[4]学者们已经针对这种论断补充了各种不同的批判性元素,质疑这种论断狭隘地将“西方”当作主导性的影响并且假设这种影响可以在整个文学生产领域被迅速且均匀地感知到,但是大多数人也都同意,翻译曾经是日本现代文学在内容和形式两个方面基本的创造性力量。[5]任何想要再现此一时期文学成果的努力都必须承认这种“外国文学霸权”的存在,不管它与其他民族文学的关系强弱与否。这种霸权的遗迹也反映在青空文库中,它表面上是一个“日语”语言文本合集并且包含数量可观的翻译作品,其中有450部是文学翻译作品。它们大多诞生在战前,并且代表了当时活跃在文学界的作家和学者的劳动成果。
尽管本书没有任何一个案例研究大规模地讨论翻译小说,但是翻译小说在青空文库中的出现也是一个缩影,它揭示了此前描述过的抽样的双重问题。具体而言,该问题就是如何评估这个方便样本(convenience sample)作为外国文学霸权代表所具有的局限性。这450个翻译作品中的一半代表着15位作者,且全部为男性。这个名单包括托马斯·曼、亚瑟·柯南·道尔、弗兰茨·卡夫卡、汉斯·克里斯蒂安·安徒生、格林兄弟、埃德加·爱伦·坡、鲁迅和罗曼·罗兰,同时还有安东·契科夫、尼古拉·果戈理、里尔克、波德莱尔和但丁。同样占其中一半的作品(约110部)仅出自3位译者之手:诗人上田敏、作家森鸥外和俄国文学学者神西清。所有这些数字的影响力在学术界都已得到很好的证明,但是在如此小的规模之下,并且缺乏一个能够将它们关联起来的研究语境,使这种对外国文学的特殊排布得以成立的取舍选择充其量只能算是武断的和随机的。那么,我们应当如何处理这一排布与那种我们相信能更好地反映战前外国文学霸权之构成的排布之间的差异?
我们可以回顾一下历史,看看在当时似乎被视为理所当然的外国文学作品的代表。1927年以后,日本的作家和读者几乎肯定会将《世界文学全集》视为这样的一个代表。这套由新潮社出版、两个部分共计57卷的系列作品大受欢迎,并且帮助改变了商业出版的面貌。在一元本图书[6]的浪潮下,廉价的多卷本现代名著、古典名著以及其他不那么高雅的大众作品层出不穷,这使得一个富有竞争力的市场得以兴起。新潮社显然是一个赢家,他们卖出了超过40万套全集,而它的竞争对手改造社的“日本现代文学”系列只卖出了25万套。[7]在对大量可引进或可翻译作品进行长期甄别、分类和经典化这一操作模式之下,这些系列著作都成为了最新的成果,无论是由批评家开列的名著清单、图书馆馆长为不断扩张的公共图书馆网络所策划的书架,还是教育者渴望在日语课堂上为“国际交流”提供支持。[8]在日本以外,英国和美国的商业出版中的系列著作并行发展,“学术列表”模式和大众市场的“企业”模式从1890年代开始汇合,产生了所谓的“父权制资本主义”(patriarchal capitalist)模式。[9]在这种模式之外,还有诸如劳特利奇(Routledge)的“世界文学”(World Library)、牛津大学出版社的“世界经典”(World Classics)以及由丹特(J. M. Dent)创建于1905年的 “给青年的人人文库”(Everyman Library for Young People),该文库雄心勃勃的目标是出版1,000部名著。这些系列著作的策划者将浩瀚无垠的文本精心策划为一套选集,他们的初衷旨在教育大众,并尽可能地让普通读者“走出杂货铺或远离报纸”。[10]
《世界文学全集》与父权制资本主义模式的密切关系在一则空前的、长达两页的广告中体现得淋漓尽致。这则广告是由该系列著作的编者佐藤义亮写于1927年,他在广告中声称该系列著作在内容和价格上都可与人人文库(Everyman’s Library)相媲美。[11]就实际收录的作品数量而言,这纯粹是一种推销手法,但是这套选集的第一部分包含了诸多类似的作家和书名(表1)。但丁、歌德、弥尔顿、莎士比亚和塞万提斯在那里代表经典;雨果、巴尔扎克、狄更斯、福楼拜、莫泊桑、托尔斯泰、屠格涅夫、陀思妥耶夫斯基、坡和霍桑代表19世纪的小说;契诃夫、高尔基、梅特林克、易卜生和霍桑,以及包括其他作家都使其更具现代感。[12]佐藤和丹特一样,也给该系列著作赋予了教育的和文明的使命,将其标榜为“研究人类的伟大著作”和“成为全球公民的必要条件”。但是,普通大众并不是他和新潮社所追求的唯一市场。他们明白,这些作品必须能够同样吸引到有意向合作的作家和知识分子,因为他们可以给作品带来必要的文化资本并使其具有价值。在这套系列著作出版前,著名的政治理论家吉野作造在《东京日日新闻》上为其发表了一篇宣传性的文章,当时他引用了一个朋友的话,这位朋友在读了那则两页的广告之后感叹道,每一个作品,直到最后一个,都是“灵魂的食粮,并且应当永远触手可得。我对它们望眼欲穿,我已准备好夺门而出并得到它们”。[13]这就是一本为普通大众准备的教科书,它好比是一件装饰品,在不停地展示着人们已经吸收了其中包含的教训。

新潮社的系列著作为日本的世界文学史认识提供了一个窗口,皮埃尔·布迪厄的“双重话语”可以很容易地解释这一点,即一种文化“经典”的民主化和大规模生产只有“得到上层社会(无论是支持那些书籍的贵族和官员,还是编辑出版那些书籍的专家和知识分子)的许可、认证和最终廉价化”之后,才能部分地实现知识的解放。[14]但这并不是解读这些选择背后的意图的唯一途径。玛丽·哈蒙德(Mary Hammond)在研究牛津大学的“世界经典”系列时提醒我们,社会学框架会模糊掉许多文本选择上的更为平淡无奇的理由。对“世界经典”的编辑而言,通常比美学价值或权威认可更为重要的,是一部作品是否处在版权期内以及购得的成本是否低廉,作品长度是否符合该系列的版式,并且作品内容是否会冒犯到中低阶层读者。就新潮社自身而言,它此前已经出版翻译文学有十年,并且该系列的第一部分中有超过60%的图书是以早期版式编排出版。[15]编者佐藤也坚持应当选录对大众读者而言非常简明易读的作品进行翻译,并采取了一些额外的措施使翻译作品更加简单明了,即便该作品此前已经被出版过。[16]这种务实的原则让整个过程(即一些作品在被从全球流通中抽选、翻译乃至后来的经典化)看起来更加偶然和随意。
这些偶然性再次显示了一个问题,即在这种情况下,对作家和作品进行取舍排布并将其视为此前已经翻译和流通的文学的代表,这种做法有多大程度的合理性?编者的选择有多武断?如果他们被利润和教育读者的双重吸引力所诱导,那么他们偏向了哪个方向、以及在多大程度上有失偏颇?正如世界文学和书籍史的学者所揭示的,在将这些选择所带有的偶然性加以语境化时我们需要去考虑选集和经典化的过程、出版者在市场机制塑造过程中扮演的角色、在制度史和档案史中反复出现的接受情况、审美形式和可译性的效果。[17]在此我认为,书目文献记录(bibliographic record)本身也会成为限定偶然性的一种手段,这种偶然性常常被解读为选择行为。偶然的决定会随着时间的推移而变得复杂,并且使作品的价值具有了历史的厚重感,让这些作品在这个书目文献记录的尺度上变得可见,或者至少会让它们的轨迹对我们有用。在本小节的其他部分,我将展示这种可见性如何帮助我们把新潮社以及青空文库中的世界文学代表性的那种可被感知的武断加以语境化。
在本章收集的所有书目轨迹中,翻译作品的轨迹是数字数据中历程最长的一条。由于光学字符识别(OCR)附带的差错,对两种印刷资源的扫描和手动录入会在部分地方出现不完整,而且在其他地方还会出现干扰信息。但它同样也承载着两种资源的独特历史。第一个资源是《明治时期翻译文学综合年表》,收录范围涵盖整个明治时期(1868—1912),它提供发表在报纸、杂志和单行本图书上的4,510种各类文学翻译作品的综合列表。所有条目按照年代顺序排列,并按照原作者的国籍进行归类。[18]第二个资源是《明治、大正、昭和翻译文学目录》,它是由日本国立国会图书馆编纂的近800页的索引,时间范围是1912—1955年。[19]其中近28,000个条目呈现了2,398位外国作家的作品,每一个条目都包括作者的原国籍、出版日期、译者以及出版者的元数据。与前述明治索引一样,它记录所有类型的翻译文学作品,但是只限于独立成卷的或成套的多卷本,也包括重印的。因此,这导致它对大众趣味和小众杂志上刊载的大量翻译材料视而不见,而恰恰是它们往往能更快地接触到最新的文学作品的引入。[20]另外,这两个资源几乎都对欧美和俄国以外的文学视而不见,因而强化了“西方”与“世界”之间的等价关系,这也是新潮社的价值观中不可或缺的组成部分。例如,这两套目录中一个中国作家都没有。
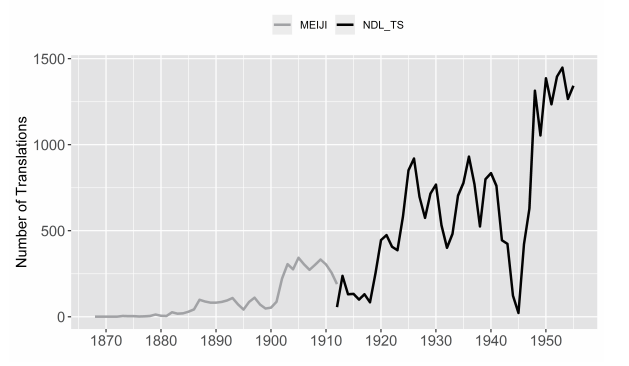
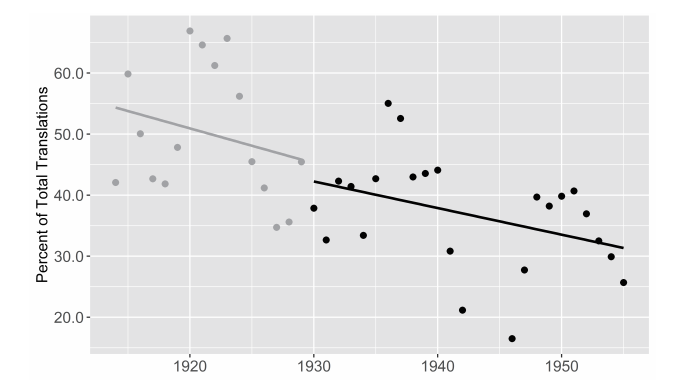
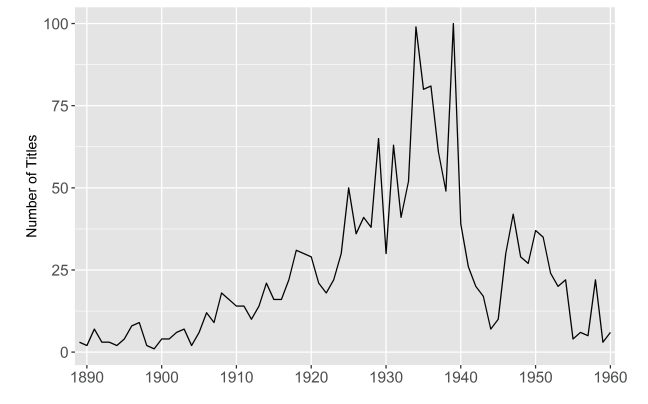
尽管这些书目的轨迹带有一种特定的世界文学定义的征候,但是我们仍然可以从中搜集到一些见解。在此我要集中关注数据的时间层面,因为它们可以帮助定位新潮社选集的编者们所做出的选择。图3显示了两个书目数据资源中每一年的翻译条目的原始计数。每一项翻译索引都被均等计数,无论它是独立成卷的一部长篇小说、收录在文集中的一个短篇小说,还是选集中的一首诗。很明显,这张图已然在用几个故事诱使我们去思考:文学生产领域和翻译之间的关系在此一时期是如何演变的?其中一个故事是随着太平洋战争(同时也意味着审查制度和资源匮乏)走向高潮而出现的衰退,尽管这种衰退与整体出版趋势是同步的。此外还有一些不太明显的故事,即翻译在战后废墟中的崛起与1920年代时一样迅速,数量在顶峰时达到了约900个,与当年新潮社准备发行文学选集时正好一样。最令人惊讶的一个潜在的故事是,翻译市场在1910年代看似经历了几年停滞之后竟然还有如此巨大的增长空间。那么与之前和之后几年相比,翻译市场真的收缩了那么多吗?还是因为出版业总体上陷入了低迷?
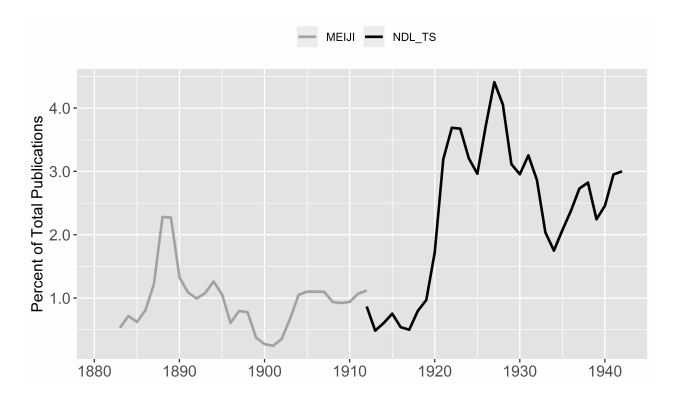
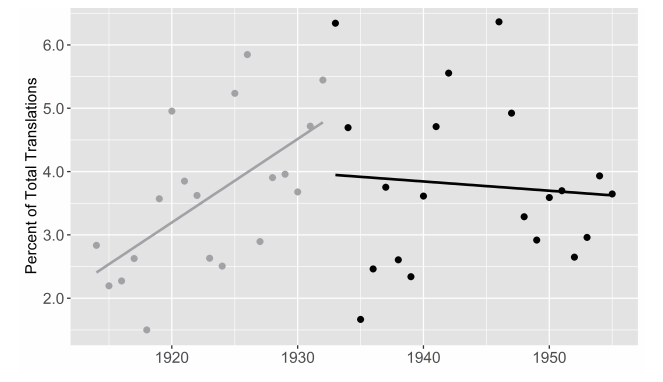
这些问题提醒我们,没有任何数据能够独立地提供充分的解释背景。数据总是衍生出更多的数据(例如,被用于解释的其他上下文语境)。至于图3中1910年代的这个特殊的最低点,我们需要知道在此之前发生了什么、了解原始数量和出版业总体趋势之间的关系。通过合并明治索引的统计数据,并将每年总数除以每年的出版总量,我们可以在这个新的语境下修正该数据。图4显示了1883—1942年间每两年的平均翻译数量占出版总量的百分比(出版总量还包括明治时期的报纸和杂志)。[21]这一可视化的结果表明,与之前十年相比,在明治时代结束不久后的几年内,翻译市场呈现出了相对低迷的状况,而且这种低迷也与出版业的总体趋势相关。究竟是什么原因导致了这种低迷,或者这种低迷在当时是否如图显示的那样被人们感受到,这些问题超出了本章的讨论范围。[22]我们不妨回望一下“大逆事件”,由于政府镇压那些被认为颠覆或不利于传统道德的材料,政治性和文学性的表述在这几年遭遇了寒冬。在这种情况下,外国书籍和文学翻译作品被认为特别危险,并且已经受到了内务部审查人员的管控。我们可以思考一下这几年间主导性的美学运动,无论是以自我为中心的私小说,还是永井荷风等人的对抗性的唯美主义,都导向了一种普遍的向内转。也或许翻译者们只是单纯地将他们的努力转向了杂志和其他媒体,而这些数据并没有被这个数据集捕捉到。
书目只是进入更深层次的定性研究的切入点,但是通过将书目的时间机制加以语境化,我们可以构建在更高分辨率下无法被识别出的周期。如图4所示,如果翻译文学在1913—1918年间进入了它的“寒冬”,那么这一证据将会如何突出更加本土化的意识形态、美学或制度性证据,从而影响到我们对个体翻译行为的解读?例如,我们可以知道在这些年间被最为广泛地翻译的是托尔斯泰、爱默生、莫泊桑和歌德——这一时期所有被翻译作家的出生年份的中位数显著降低,最低到1810年触底,或大致在108年以前(图5)——仅次于他们的是作家、小说家以及剧作家约翰·高尔斯华绥(1867—1933),而且他是后来的诺贝尔文学奖获得者,将更加引人瞩目。大谷绕石(1875—1933)在1914年决定出版他最新创作的23部戏剧手稿,并且其中一些内容带有阶级和性别问题的政治意识,他也正是因此而为世人所知,这似乎更加新鲜、激进和有预见性。[23]而随着翻译市场从1910年代的显著低迷中复苏并且在《世界文学全集》(1929)出版时走向顶峰,我们通过这一波动及其后果可以想见市场的选择是多么令人惊心动魄。那么他们是反映并强化了先前的趋势,还是偏离了先前的趋势,并预告了未来?

为了从数量上重新解释这个问题,我们可以将每一位作家的日译作品记录想象为一条时间趋势线,并计算每一年该作家的所有译作的占比。或者,我们可以将多位作家的趋势线汇总起来,以演示每年出版市场对他们的总体关注度。比如就《世界文学全集》而言,根据作家在全集中被归类的部分对其进行分组是有意义的,因为每一个部分的编辑计算方法不同。第一部分的作者通常年龄较大且更为经典,出生年份的中位数为1836年。从1930年开始出版的第二部分的作者年龄偏小,出生年份的中位数为1876年。在这个部分,新潮社选择在杰克·伦敦、厄普顿·辛克莱、奥尔德斯·赫胥黎、托马斯·曼和列奥尼德·列昂诺夫等作家身上押注,他们当时在翻译市场还比较新鲜。如果可以绘制出每一组的趋势线,那么我们就可以确定在出版的时刻是否发生了重大变化。这一时刻是否标志着趋势线的断裂,以至于翻译的百分比明显下降或开始上升?或者这一时刻仅仅是持续发生的趋势中的一个阶段?确定好这一点可以使我们理解,选集究竟是对以往的偶然性选择的历史引力场所做出的回应,还是推动了那些选择得以实施。
这也提出了一个至关重要的方法论问题,即每一项针对时间趋势的分析都必须回答:我们怎样知道数据的变化在何时有意义或没有意义。时间序列分析是专用于研究这一问题的统计学的一个分支领域,我从中借用了一个最为简便的方法来测试在一条趋势线的某个特定点是否存在“结构性断裂”。它被称为乔氏(Chow)测试,可以告诉我们与样本子集相对应的线性模型(如断点前后的趋势线)在彼此之间以及与整个趋势线相比是否有不同的表现。一个明显的结果(p<0.05)告诉我们,两个子集的不同表现足以证明数据中存在“结构性断裂”。[24]我将这一测试应用于第一和第二部分中作家的所有翻译作品占比的滑动平均值(moving average),并在各个出版的节点上打破总体趋势线。这些趋势线如图6和图7所示。就第一部分而言,乔氏测试表明其中没有显著迹象证明有结构性断裂(p=0.79)。尽管作家方面存在相当大的差异,但是总体趋势在持续地下降,这表明新潮社选择了那些在翻译市场中发展势头正在下降的作家(总共46位),虽然他们还没有完全退出。到1950年,他们的作品仍占数据集中所有译文的25%以上。对于第二部分,有更多的证据表明出现了结构性断裂(p=0.05),因为1932年之前的一次清晰且稳定的上升变成了一条嘈杂的趋势线,显示出逐年不同的关注程度。顺便一提,新潮社似乎在那些不太成熟的作家身上押下了更大的赌注,这个赌注在托马斯·曼和乔治·杜哈梅尔那里取得了成效,但是在杰克·伦敦和亚历山大·库普林那里没有。
那么,新潮社忽视了哪些外国作家?或者说哪些外国作家尚未出现在新潮社的视野中?书目文献记录给我们的最后一个启示是,它让我们能够解读哪些作家为何没有被选择,因为这一不被选择本身暗示了文学选集的编者所操控的文学价值的标准。它也让我们可以从相反的角度观察这一操控,也可以说,它暗示了一个作家会因为他或她在一个更大市场中的存在,而不被选集选中是多么的不可能。图8显示的是1912—1955年间被翻译最多的前50名作家,按照该作家是否入选《世界文学全集》进行的归类。每一个省略背后都有可能潜藏着一个更有趣的故事,无论是人们对安德烈·纪德、赫尔曼·黑塞等作家的缓慢接受、小泉八云在既成的世界文学图景中的模糊定位,还是那些阻止亚瑟·柯南·道尔出现在这些图景之中的文类偏见。

我以这份被翻译作家清单开始,也将以其结束。正如书目文献记录被用来将新潮社选集置入一个更为广阔的历史引力场,我们也可以将类似的做法应用于青空文库,并将它的内容与图8进行比较。尽管该记录没有提供任何有关这些作家在1955年以后的经历,但是任何重叠性的存在都是有益的。例如,多伊尔的作品在历史上受到如此多的关注,因此他在该记录中并不会让人觉得那么格格不入,契诃夫、坡、果戈里和托马斯·曼也是如此。青空文库并不仅仅是一个随机的或随意的世界文学样本,它与日本较为悠久的翻译历史有着一定的关联。与此同时,托尔斯泰和莫泊桑的缺席显得更加刺眼,特别是考虑到他们在书目文献记录中的主导性地位,这或许恰恰是在暗示1955年以后人们对这些作家的关注度已经转移了不少。过去的和现在的选择行为之间的这些差异实际上是一个契机,让我们去思考如何将青空文库优化并递补为一个数字档案,从而为战前的翻译文学创建更加合理的样本。如何实现这一点最终将取决于这些材料在一个更大规模的调查中会遇到哪些要求。但在此处,我们已经看到书目文献记录如何成为一个可资利用的语境,通过它,我们可以在面对复杂的历史偶然性时进行我们自己的选择。
一、作为样本的青空文库——一个国民文学案例
将关注点转移到占据青空文库绝大部分内容的日语文学之后,我们可以预料现在和过去的选择行为之间的差异会变得更小,或者至少不会显得那么引人耳目。当然,版权法是该文库收录范围的主要限制因素。但是日本与美国不同,美国的版权法划定了明确的界限(目前是所有在1924年以前出版的作品),日本的版权法截至2018年规定要在作者去世50年后(现在是70年)。[25]所以,这让我们更加难以确切地知道选择行为之间的差异在何处会扩大为断崖。如果我们将青空文库的收录内容与日本国立国语研究所挑选出的139部作品进行比较,就可以看出版权的影响力。青空文库收录了其中的79部(57%),不过按照当前的版权要求,它的收录内容可能会达到其中的100部。由于版权原因而被排除在外的作家包括在战后初期迅速成名的(如三岛由纪夫、井伏鳟二)以及活到了1970年代初期的经典作家(如志贺直哉、川端康成和武者小路实笃)。但是其中21种不存在版权问题的作品又是怎么回事呢?在版权限制之外,还有哪些限制性因素可以解释它们的缺席,进而帮助我们去理解青空文库再现出的日语文学与其他印刷档案轨迹中的日语文学之间存在何种差异?
要回答这些问题,我们需要深入发掘作为档案工具的文学选集。我们已经知道过往如此多的日语文学样本是如何将选集作为一级选择机制得以成立的,其中也包括刚刚讨论过的139部作品。青空文库的建设者们在选定底本时也同样是以选集为基本准则。因此,阐明青空文库与印刷档案之关系的一个重要方法是,厘清青空文库在哪些方面与文学选集的内容以及其中所包含的选择性偏差之间存在一致或差异。毫无疑问,与战前文学生产的现实相比,和选集的比较揭示了青空文库对现代文学的再现更多地与商业出版史相关。不过,正如爱德华·麦克(Edward Mack)和其他人所指出的,因为商业出版史在塑造战前小说观念的价值等级体系的过程中承担了将之具体化的责任,所以上述对比有助于我们去勾勒青空文库与战前印刷档案之间的关系,并且有别于那些等级体系。[26]那么青空文库的再现如何与出版商和编辑们共同想象的战前小说保持一致?
作为第一个比较点的是我们在前一章中曾提到过几次的选集:《现代日本文学全集》(1953—1958年间陆续面世),由筑摩书房出版(下文简称GNBZ)。它也是安本美典(やすもとびてん/Yasumoto Biten)以及其他学者在1950年代寻找扩大文体分析规模的方法时所使用的选集。GNBZ总共出版了99卷,并且开创了战后“日本现代文学”选集的新标准,复制了之前由改造社出版的同名选集在1926—1931年间的成功。如同它的前辈一样,筑摩书房的编辑们希望将它打造成一套大众读者买得起且易于阅读的选集。他们还试图恢复一种现代经典的视野,并以此清除掉在战争年代盛行的极端意识形态。该项目的策划人兼编辑臼井吉见(うすいよしみ/Usui Yoshimi)最初想将这套选集命名为《国民文学全集》(国民文学的全部作品),这是在利用战后日本对“国民”概念的反思,当时人们将之理解为一种更加民主、更加以人为中心的国家政体。[27]臼井作为一位出色的批评家和小说作家,主导了这套文集内容的选定工作,它包括1,758种小说、诗歌、戏剧和评论作品。小说占据了总数的四分之三。这些内容呈现了215位独特作家的作品——其中一半作家有5部或5部以上的作品被收录其中——最早的作品可以追溯到坪内逍遥的《小说神髓》(1885—1886),最新的作品收录到战后的畅销书大冈升平的《野火》(1952)。其中只有16位作家是女性(7%)。
筑摩书房认定日本读者会非常渴望一套崭新的、经过净化的现代经典,而且这套经典可以规避政治意识形态、避免处理阶级和种族问题(例如无产阶级和殖民地小说)。这套选集是所有已出版选集中最为成功的,销量高达1,300万套,并且将筑摩书房从破产的边缘拯救回来。它集中收录1890年代至1930年代初期的高雅的言文一致体小说——中村光夫将之称为“旧文学”——但是也收录了战后新世代作家采用中村光夫所说的“旧风格”写就的作品,这套选集在此一时期构建并巩固了文学的经典范式。[28]青空文库仅仅是部分地呈现了这个典范,它只占GNBZ中所有文类及其变体的34%(600部作品)。如果仅就小说而言,这一比率会跃升至38%(503部作品)。如果就作家的重叠而言,两者间的差距会缩小:在所有被GNBZ收录的5部或更多作品的作家中,青空文库收录了其中的62位,占58%。也许有人会怀疑并认为版权问题可以解释余下的差异,但是从GNBZ中的作者死亡日期来看,高达75%的作品已经进入了公共领域。具体而言,就是目前有700部作品可以但是尚未被青空文库收录。图9显示了GNBZ中所有作品的版权终止年份,并且告诉我们GNBZ所描绘的现代日本文学图景中目前有多大比率可以被添加到青空文库中。虚线之间的部分还显示了有相当大的剩余量要等到2055年才可以被添加到青空文库。

青空文库的内容没有完全反映出筑摩书房的战后文学图景,这也许并不奇怪。但是至少就GNBZ中的作品版权情况来看,青空文库也似乎并没有刻意追求这一点。一些明显的目标处在版权问题的范围之外,这其中就包括川端康成和志贺直哉等“旧文学”标准的确立者,但这并不是决定选择谁进行数字化的首要限制条件。一些作家根本就不符合青空文库志愿者的口味和兴趣,例如,坪内逍遥和宇野浩二的作品在文库中只有12部。当一个作家的确引人瞩目时,志愿者们的注意力会特别关注一组有别于GNBZ的编辑所选择的作品,并尽可能地去展现这个作家的全部作品。尤其值得注意的是,在青空文库中拥有最多小说作品的前100位作家中,几乎有一半(48位)未被GNBZ收录,他们大多是大众文学和历史小说作家。与GNBZ的比较虽然为我们揭示青空文库中潜在的选择逻辑提供了一些重要线索,但是它也只能帮助我们走到这里。它没有揭示出过去70年间趣味的形成过程和经典化的过程,而这些过程似乎使得特定的作家和作品更容易受到数字化的影响。那么我们怎样才能掌握到这些复杂且不断演变的过程所带来的聚合效应呢?如果我们可以做到的话,那么哪些作家和作品会登上榜首?
约翰·吉洛里(John Guillory)认为,任何再现经典的尝试,即便是以综合选集的形式进行,“仍然是从一个更大的且不会出现在任何地方的列表中进行选择”。经典永远是“一个想象的作品总体”,它永远无法成为总体,因为对它的任何调用都是部分的,而且和语境息息相关。[29]选集的编辑们将自身的偏见施加到了选择过程中,即便表面上看来他们在尝试做到详尽或尽可能地捕捉整个时代的“噪音”,就像当年改造社开创性的《现代日本文学全集》的编辑们所做的一样。改造社这个系列的灵感来源于著名的《哈佛经典》丛书,正如该丛书的策划人查尔斯·艾略特(Charles Eliot)所言,当这些偏见通过编委会逐渐形成时,其结果都会让人感到“或多或少带有随意性”。[30]这些决定即便看起来在当时是片面的或随意的,但是它们会随着时间的推移而被加强和重复。对这些决定(例如,哪些作家和作品被选集收录的次数最多)所造成的复合效应的探索永远不会将经典视为一个想象的总体,但是它指引我们走向不可预知的文学性判断潮流趋于汇聚的那些池塘或浅滩。
2004年,出版商日外协会(Nichigai Associates)为1,255套综合性和个人性的选集目录制作了索引,并据此为前述那些决定制作了海量记录。该记录拥有60万个条目,涵盖了8,500位独特作家的小说、诗歌与戏剧作品,其中最早的作品为1897年的成岛柳北的作品集(《柳北全集》)。图10显示的是每年出版的各类全集的卷数,并且向我们讲述了几个似曾相识但又鲜为人知的故事:第一波选集出版浪潮是由1920年代末期的一元本图书推动的;第二次浪潮出现在1950年代中期,当时以筑摩书房为代表的出版商试图重建曾经因战时审查制度而丧失了的文学市场,同时这也是顺应公共图书馆和学校图书馆的新需求;第三次浪潮始于1960年代末期,这一市场在当时达到了顶峰。[31]1925年以前的数据少得令人怀疑。只有几套多卷本作品集成为了改造社主导的一元本图书热潮的重要参考先例。[32]不过,1925年以后的数据更好地体现了综合出版物的范围和卷数。有一份历史记录表明,在一元本图书热潮的鼎盛时期(1925—1929),总共有超过300套多卷本丛书出版。不过,这项记录虽然听上去让人印象深刻,但是其中只有40套与现代日本的小说、诗歌、戏剧相关。另外,其中还有16套是综合性选集。[33]日外协会的索引收录了其中的12套,但是缺少2套专业的散文体虚构作品丛书。[34]
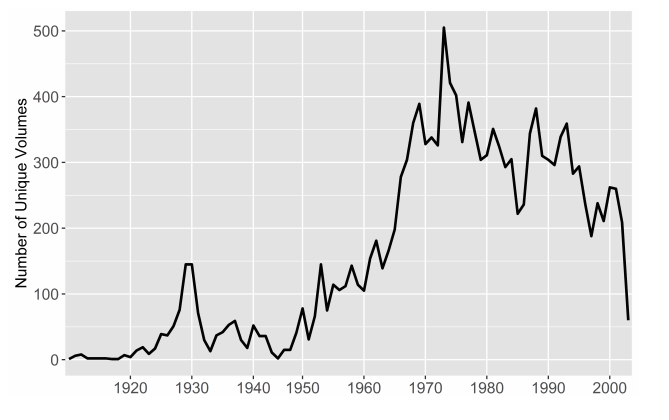
由于选集出版量的急剧增加,日外协会索引越来越难以覆盖战后几十年的状况。自1950年代开始,大众市场中的全集出版不断扩张,新旧出版商在其中激烈竞争,他们在改造社全集的原始理念之上生产出了几十种变体。根据高岛健一郎的估算,早在1953年出版物中的各类全集总共约有300套,占到了全部图书市场的30%。[35]由于缺少一份关于所有全集的总清单,所以我们很难估算日外协会索引所覆盖的比率。不过,该数据将每年出版卷数的趋势线分为了综合性选集和作家选集两类,这也能够反映出当前人们对全集出版市场兴衰的理解。图11显示了每一类选集对前述三次浪潮的不同贡献,并且清晰地表明全集出版泡沫如何在1970年代末迅速破灭。长达10年的投机性投资见证了出版商们如何向新中产阶级业主及其受教育程度日益提高的婴儿潮一代做市场营销,但一切都随着1978年筑摩书房的破产戛然而止。[36]此后,个人选集占据了大部分市场,而综合性选集将注意力转移到了长期被排除在经典之外的文学作品上。无论日外协会索引提供的日本现代文学图景是怎样的,它都会被泡沫破灭之前编辑策划过程中的取舍所支配。

想要在数百套选集和数千套个人作品集中获得这种图景,已经不再可能像查阅作品清单那样简单。首先,我们有必要将分析的范围限定到小说,因为其他文类,尤其是诗歌,可能会遵循不同的选录模式。我利用一本现代日本文学辞典,按照作家的主要创作文类为其制作标签。一部分被这种方法标记为小说家的作家当然也会创作其他文类的作品,但使用这一方法的目的是我们可以方便地抓取到那些最经常被选录了小说作品的作家。[37]这一操作过程将原始数据集缩减到了190,000条记录,其中有38,360条是来自179套综合性选集,其余的来自569套作家选集。尽管还有很多内容需要查阅,但是现在的分析单元在某种程度上更加具有比较价值。与前面的翻译数据一样,其中的挑战在于我们如何对这些分析单元进行排序。通过简单计算被选录次数最多的作品或按照被选录作品数量对作家进行排名,就可以掩盖掉查看那些数据的其他方式。但是,战前的作品与在战后出版并且相较战前作品更缺少时间被选录的作品应当受到同等的对待吗?我们对待一个少量作品被大量选录的作家和一个大量作品被诸多不同选集选录的作家是否相同?是否有任何一项策略提供了一种可以与青空文库进行比较的更为合理的基础?
任何策略都会影响我们对数据的解释,因为每一项策略都是以牺牲其他维度为代价,从而使某一维度特权化。就单个作品而言,它的原始频率体现的是一种有关其重要性的扭曲的视角,因为它没有考虑时间。那些早前被选录的作品之所以更有可能登上榜首,只是因为它们拥有更多时间等待选录。表2展示了这一点如何掩盖了同时代那些同样成功的作品。第一列是综合数据集中出现频率最高的10部作品(以及该作品的作者)。之后几栏分别列出的是1920—1959年间(第一次和第二次全集出版浪潮)、1960—1979年间(全集出版达到泡沫峰值)以及1980—2003年间(综合性选集市场崩溃之后)的出现频率最高的前10部作品。在此,我们发现,除大冈升平的《野火》之外,综合数据集的统计数据更偏向于战前作品。其中有几部作品在第一个时期取得了领先地位,并且在第二个时期保持着这种高被选频率。不过第二个时期的确推动了经典化的过程。其中有6部作品被综合数据集的名单收录。在第三个时期,我们可以看到泡沫破灭后市场对全集出版的影响,其表现是,这一时期作品在综合数据集中的统计数据更低,并且这一栏的作家没有在其他任何一栏中出现。这并不是因为这些作品较新,而是因为它们都是战前或战后不久的作品。更准确地讲,最后一个时期出现了一个明显的转换,即人们的注意力从“纯”文学转向了大众类型的小说,而这恰恰是GNBZ建构的文学图景中缺失的内容。

注:前10名名单根据综合数据集进行统计并依照具体时间范围排列。括号内为作者姓名。
由于原始频率掩盖了那些更早被选录的作品的自身优势,所以我们需要一种能够将时间加以标准化的方法,以便我们能够在时间中立的赛场上比较不同的作品,就像我们要根据一个城市的人口数量来对其犯罪统计数据进行标准化一样。最简便的方法是将原始数量换算为比率,即用一部作品被选录的总次数除以其首次被选录以来的年份。据此,一部在60年内被选录了10次的作品,其价值将是一部在30年内被选录了10次的作品的一半。此外,我们还可以给予在短期内被大量选录的作品更多的重视并以此标定时间,但是这种方法在经典面前难以立足。用频率分别除以其被选录的第一个年份和最后一个年份,我们将会得到一个“强度”(intensity)度量。表3展示的是根据这两个度量测算出的作品排名。即便是如此小的样本,我们也能够明显看出每一项排名都有着不同的故事。大冈升平的《野火》——有关一个士兵在菲律宾最后几天绝望战斗的故事,也是对战争的非人性影响的持续性反思——在标准化时间列表中排名第一。它与1950年代的几部获奖作品共享了这项排名,其中包括安冈章太郎《海边的光景》(1959)、吉行淳之介《骤雨》(1954)以及川端康成的经典作品《雪国》(1947)。战前的文学巨匠在战后迅速被当时的同行完全取代。相比之下,在被选录强度一栏中,我们可以发现榜单上那些知名作家的作品大都不太为人所知——其中也不乏在褪色之前引人注目之作,例如井上靖的《洪水》(1962),在短短三年内就被选录了9次(1966—1969)。
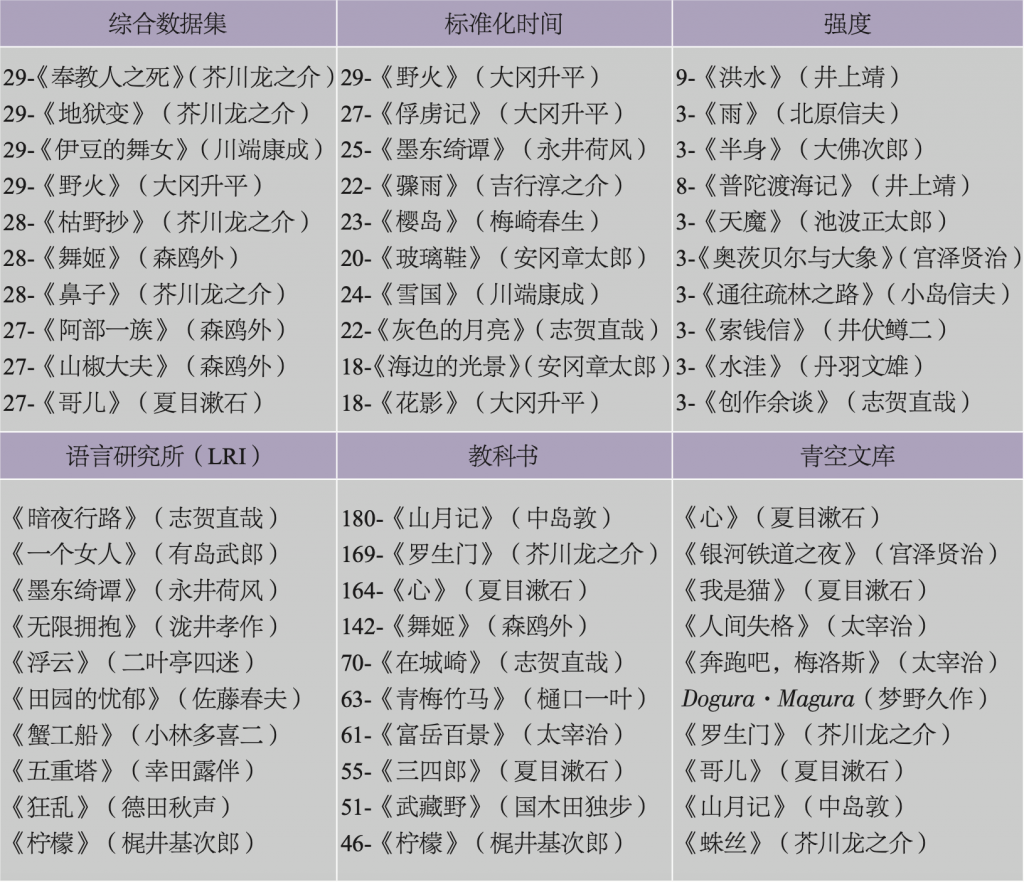
注:表格上半部分是基于三个度量值(原始计数、标准化时间计数和强度)计算出的日外全集索引中的前十位作品。表格下半部分是分别根据语言研究所(Language Research Institute)的调查统计、高中教科书的综合数据集以及青空文库使用者的访问次数做出的排名。
我们还可以想象使用其他语境变量(如销售数据)进行标准化的策略,这将允许我们按照每一套选集的商业成功程度对作品进行排名。不过,我的意图仅仅在于,指出在一个数据集中存在多种可能性去将频率转换为关系。数据中的每一条分叉路径都牵涉到要对其对象相互之间的关系做出假设,每一条分叉路径都生产出了不同的文学世界图景,并且与青空文库中的文学图景有着不同程度的重叠。比如,有着较高选录强度的作品很可能会更快地从文化想象中消失,而且因为它们很少被重印,所以也不太容易抵达青空文库志愿者的手中。在综合性选集中拥有更强存续能力的作品更容易受到数字化的影响。与此同时,如果我们以标准化时间作为度量,那么更容易受到数字化影响的仍然是拥有版权的作品。事实上,青空文库收录了原始计数排名前150部作品中的100部(67%);标准化时间排名前150部中的69部(46%),这受到了有版权作品的影响;强度排名前150部中的32部(21%)。(回想一下,与LRI列表的重叠率是57%)这些数据帮助我们理解青空文库如何与日外指数投射出的不同图景相匹配,以及它如何很好地处理了与这些图景相关的研究性问题。
如果我们以作者为分析单位,那么将会产生另一种关于青空文库的匹配度的视角。在此,我们可能倾向于按照综合性选集中的各自作品总数对作者进行排名。但是,这将给更早被选录的作者赋予特权,何况不论作品长度如何,都将每一部作品视为对作者身份地位的有效信息。如果我们假设简洁性增加了作品被选录的概率,那么原始频率将会进一步有利于那些主要写较短篇幅作品的作家。[38]实际上,综合性选集的编辑并不一定会回避长篇小说。相反,一些出版商在开发能够在每一页上塞满更多文本的印刷格式时,会将长篇小说作为卖点。[39]此外,仅仅拥有更多的短篇作品,也不能保证那些作家会被选录或者同一个作品可以穿越时间被选录。评估篇幅对选录的影响还需要更多的研究,更不必说还有精确的书页长度数据了。但很明显的是,我们需要一种方法既能控制时间又能考虑到选录作品的绝对数量掩盖了其他方面的因素。“多少”的问题至少需要由“频率”的问题来加以界定。
文献计量学中的一个通用指标,即赫希指数(亦称H指数),恰好做到了这一点。作为一种将科研成果在学术期刊引文中的影响广度加以量化的方法,该指标常常被诟病为象征着新自由主义下的学术生产力贬值和大学行政管理中算账阶层的崛起。不过,除却其政治用途和滥用之外,该指数其实是在尝试通过对应领域的引用广泛程度去量化一个作者的产出总量。如果将这一指数应用到选集中,比如一个编辑的选录被视为一种引用,那么H指数会将原始频率转换为一个关系框架,而在此框架中,一个作家被选录的方式要比被选录的数量更为重要。从数学的角度讲,H指数是通过获取所有已经出版(如选集)的作品,根据被引用(如被选集选录)次数对作品进行排名,并且只要排名大于或等于该排名的引用次数,该指数就会从第一个位置开始倒数。最后一个准确位置的排名就是H指数。例如,日外数据集中H指数排名最高的作家是芥川龙之介(H指数=21)。它的意思是,他被选录最多的作品中有21部作品至少被综合性选集选录了21次。为了将时间标准化,我们可以用这个数值除以该作家的第一部作品被选录以来的年数。计算得出的“M指数”可以使不同时代的作家处于更加平等的地位。
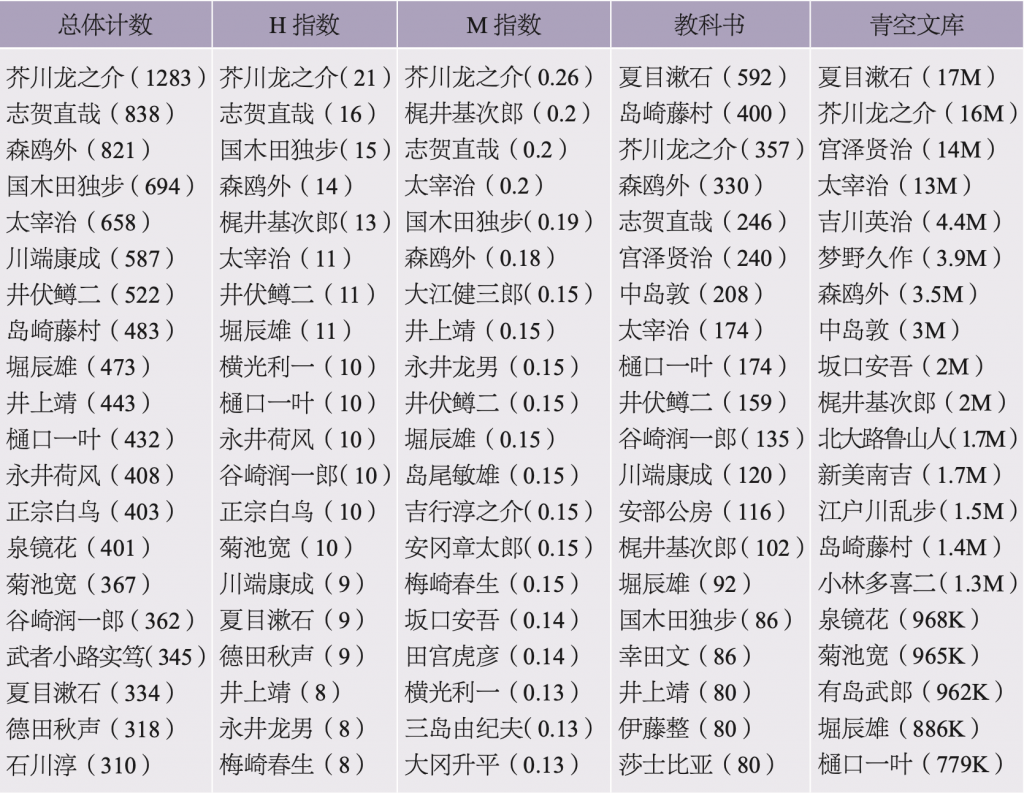
注:前3列依据日外全集索引列出了排名前20位的作家,分别根据3个指数:总体计数、H指数和M指数。括号内数字对应于各自的测量值。教科书一栏列出的是在高中教科书数据集中排名前20位的作家。青空文库一栏是根据2009—2017年间的作品被访问次数排出的前20位作家。
表4列出了根据每一种指数计算出的排名前20位的作者,其中总计数与H指数和M指数一同列出。通过比较这些名单,我们可以清楚地看到,原始计数如何为那些在战前最为活跃的作家赋予了特权。这种文学世界图景对现代日本文学的学生来说太熟悉了,其中有明治末期的小说巨匠(例如森鸥外、泉镜花、樋口一叶、夏目漱石),同样还包括他们的在大正时期和昭和早期取得成功的主要继承人(例如芥川龙之介、志贺直哉、川端康成、谷崎润一郎)。H指数度量调整了其中一部分作者的排序,但是仅用新作者替换了其中的四位:梶井基次郎、横光利一、永井龙男以及梅崎春生。不过,这些差异是有建设性意义的。以梶井基次郎为例,我们可以看到,尽管他的总体计数相对较低,但是如果计算一下他有多少作品被反复选录,那么他的表现会比其他作家好很多。他和横光利一登上榜单并不令人感到意外,但是永井龙男和梅崎春生的出现就有些令人意外了,特别是考虑到他们在战后早期的小说很少受到学术界的关注。当我们控制好时间变量后,他们两位的存在变得更加显著,其他在战后成名的经典作家也是如此,包括大江健三郎、坂口安吾以及三岛由纪夫。排在M指数一栏最后一位的是大冈升平,他在所有指数中的较低排位表明,他在综合性选集中的存在很大程度上是依赖少数被高强度选录的作品。
这些列表只是评估作家在战后的受欢迎程度和被学术界接受的程度。它们提供了一扇狭窄的窗口,让我们经由它们去窥视那个任何人都无法直接进入的想象的整体——一个通过公共图书馆或学校图书馆的参考书架中的星星点点过滤出来的整体,或者是出生于日本战后复兴时期的被新装备起来的中产阶级的内在。这些窗口可以为语料库的建设提供合理性,因为语料库是根据作家在这些列表中的相关排位来对他们进行抽样,但这也同样意味着要展示出它们的基本假设,并将它们与更为具体的研究性问题关联起来。这些窗口在此非常有用,因为它们揭示了长期累积而成的编辑选择行为对那些被淹没在重重档案中的作家造成的复合影响。特别是,它们允许我们将这些影响所造成的结果与青空文库提供的复合的文学图景进行比较。如果没有关于关注度(比如哪些作家在青空文库中最经常出现)的某种尺度,直接的比较就会变得更加困难,我很快会在下文讨论这个问题。不过,我们也可以通过青空文库收录的小说作品(少年小说除外)数量来观察那些最经常出现的作家并获得一些见解。图12显示的是排名前20位的作家以及他们相对于排名前50位作家的总体表现。其中只有少数几个名字在此前的列表中出现过,而其余大部分都没有。
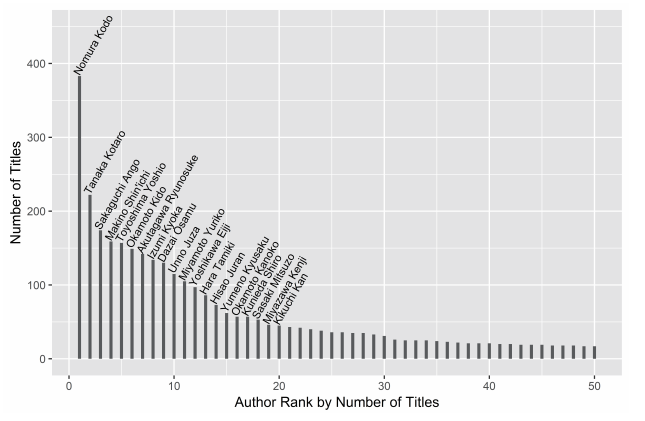
事实上,这个排名中有近一半的作家属于大众文学范畴,他们中的许多人都是在全集出版泡沫破灭后最经常被选录的作家:江户川乱步、梦野久作、久生十兰和冈本绮堂。他们虽然没有被排除在早期的综合性选集之外,但是出现的频率较低,或者被划分到特定的“大众”文学或其中的一个变体子集中,包括侦探、历史、幻想、恐怖和科幻小说。创建这样一种两级出版市场的冲动可以被追溯到1920年代末期的第一次全集出版浪潮,它是印刷文化产业的繁荣所带来的生产领域的细分,也是印刷文化产业发展的一部分,它助力了整个产业的发展。不过,在选集出版中,出版商对大众小说的公开投资水平随着时间的推移也表现得起伏不定。实际上,通过计算此类小说及其变体的卷数的移动平均值,我们可以发现对它们的投资正好在战后泡沫期触底,此后在1980和1990年代回升,占据了综合性选集市场的大部分剩余空间(图13)。从这个角度看,大众文学作家在青空文库中占据主导地位,实际上也矫正了第二波和第三波全集出版浪潮对战前作家和“纯文学”作家的经典化。如果说青空文库部分地再现了这个经典化的过程,那么它也填补了一些被早期的出版浪潮遮蔽或抹除掉的区域。
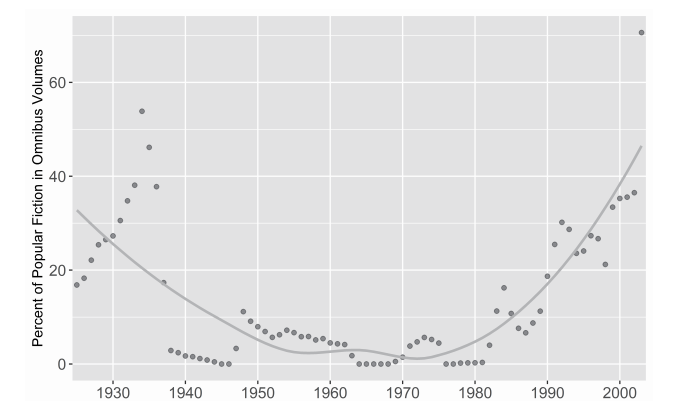
最后一个必须要解决的问题是女性作家的稀少,这与迄今生成的任何名单中女性作家的几近缺席的状态相吻合。在青空文库中被归类为小说(再次强调,不包括青少年文学)的作品子集中,女性作家的文本占比不足9%,略低于综合性选集中的10%和单个作家选集的12.5%。但是,这些低数值掩盖了选集数据中的一个更加令人担忧的模式。如果将女性作家的作品占比计算为历时性的移动平均值,那么这个占比会一直保持在10%左右,直至1990年代(图14),之后只是因为几套专门针对女性作家的综合性选集的出版才开始上升。如此看来,日本的经典制作过程对女性小说的偏见也就不足为奇了。不过,这种偏见在文学出版市场中的强烈存在和持久性仍然让人震惊。这一偏见究竟在多大程度上能够反映出1930年代以来的任何特定时期的作家人口统计情况,是有待进一步研究的问题。[40]此处最为相关的一个事实是,青空文库在性别问题上很好地反映了现状。当我们看到一个数值在各种不同的样本(文学价值的各种不同的全球动力机制传感器)中重复自身,它传递给我们的信息是,这些动力机制是多么具有系统性以及数字档案是如何将它们的印刷前辈的偏见变得更为复杂的。当我们通过这些档案去构建样本时,我们必须注意到这些偏见并做出判断:是对受到影响的亚群体进行过采样(oversampling)[41]以抵消这些偏见,还是将它们作为真实的潜在偏见的历史产物来处理。[42]

我们还必须去关注这些偏见趋于平衡的拐点。图13和图14显示,全集出版泡沫的破灭也导向了另一种不同的综合性选集及其读者的文学图景。与迎合大众趣味或者尝试弥补那些被长期排挤在此类经典边缘的声音相比,国民经典的神圣化是一场利润较低的冒险。就大众类型的小说而言,后泡沫时代(基本上在1980和1990年代)成长起来的出版市场和阅读群体在那些形塑了青空文库架构的选录逻辑中得到了很好的体现。但是在女性作家的创作方面,我们在综合性选集中看到的上升趋势并没有以任何整体性的方式迁移到青空文库中。这有可能是因为供青空文库志愿者选录的女性作家群体仍然受到版权法的限制。因此可见,即便在过去半个世纪中作者的人口结构发生了变化,但是在版权已解禁的作家群体中性别不平衡的现象仍然没有改变。[43]不过,了解到青空文库并没有体现文学选集对女性作家的日益关注这一点,同时也提出了一个问题,即自从全集出版泡沫破灭以来,普遍的文学价值评估过程是如何介入并形塑了人们对战前日本现代文学的纪念和重读方式,除此之外还有哪些因素使得一些作品比其他作品更有可能被数字化?
的确存在很多可能的影响力量,比如作品的除选集之外的其他有效存在形式,但更稳定、更广泛的经典化模式之一是中学教育。在此,我们可以发现一项决策高度集中、在波及范围内影响力巨大的制度,但是与此同时它也有着长期的制度性记忆并且趋于停滞。在对青空文库中的小说进行检证之前,我想简要地查看一下书目记录轨迹,它以一种较为恰当且可控的方式记录了文学价值变动所带来的普遍影响。它来自一个索引数据集,该数据集是对1949至2007年间出版的近1,700种高中教科书中涉及的约8万部文学作品的索引。[44]该数据集还可以作为另一个参照点,用来定位青空文库与其一直以来所想象的文学整体之间的关系。从教育教学的角度看,这也是一次机会,让我们去思考用一个更为精细以及有着具体制度的书目数据集能够做什么,并且我们还可以设计一套方法去比较基于该数据集的现代日本文学图景与其他文学图景的关系。至此,我们的分析所依据的是计算每一个核心样本在最表层的重叠百分比或观察它们之间的差异。但是,随着样本数量激增,我们需要以呈现其总体构成的方法来衡量它们之间的差异。
在本章分析过的所有数据集中,教科书数据集是迄今最纯净、最容易驾驭的。它作为一种电子数据可以直接从出版商处购得,它源自一种高度结构化的文本文件,可以通过Python脚本被轻松地转换为数据库。它的每一个条目都包含一个作品的标题和收录该作品的每一本教科书的元数据(例如教科书标题、出版社、出版日期)。不过,尽管它可能是一种比较可靠的数据源,我们仍然需要通过历史的和制度性的语境将其转化为有用之物。比如,特别重要的一点是,我们需要知道文学文本是在语言教育的框架内被教授的,而语言教育会随着日语语言的变化呈现出时代特征。所以,数据集中有将近一半的教科书是专用于古典语言教育。除去这个部分,剩下的842本教科书中包含了约13,000个条目,分别来自2,752位作者。此外,我们还应当知道,私人出版商出版的教科书自1949年以来都需要经过日本文部省的审查,而审查本身并不能保证教科书会被广泛采用。任何一本新的教科书都得面对一个以此前教科书为中心所建构起来的课程的基础架构。在此意义上,这个数据集也记录下了哪些努力使教科书通过文部省审查所做的编辑取舍,也记录下了教科书编订者如何关注那些教师和学校董事会已经投入资源和精力的文本。最后,散文体虚构作品通常会以重编版或精简版的形式出现在教科书中。因此,数据集中的条目应当被理解为作品的一部分,而不是全部。[45]
这个书目记录轨迹让我们洞察到一套价值体系,这个体系会奖励停滞和连续性,而非活力和创新。事实也的确如此,当我们测算每一部作品的原始计数时,很快就会发现这个价值体系的反馈机制一次又一次地奖励了相同的四部作品(见表3)。这些作品在高中教科书中占据了日本现代文学的主导地位,它们被统称为标准文本。受惠于1951年中岛敦的《山月记》和1957年其他三部作品所开启的制度化过程,这些标准文本逐渐积累了越来越多的价值,它们占据了1975年审定的现代国语教科书中的20%,并且除森鸥外的《舞姬》之外,到2007年这一占比增加到了40%。[46]在标准文本之后,其他作品的原始计数迅速下降,排名第100位的梅崎春生《樱岛》的出现频次只有9。另外值得注意的是,纵观表格中所有列表的排名,只有《舞姬》和梶井基次郎的《柠檬》出现在其他所有列表的前10名中。在以作家为单位将原始计数汇总之后,重叠程度会增加(表4)。夏目漱石现在升到了榜首,这个位置他在别的列表中从未有过。但紧随其后的是一串耳熟能详的名字——芥川龙之介、森鸥外和志贺直哉,他们在所有排名中都位居前列。中岛敦也紧随他们之后,这点也毫不令人奇怪。不过,他的名字没有出现在选集排行榜上,这表明教科书数据中的这个特定计数所提供的视角是多么地偏颇。
我们并不需要用这些教科书数据来为那些标准文本正名,虽然它的确澄清了标准文本在高中课堂上对文学关注度的巨大的垄断程度。这些数据的有用之处在于,它将出版商如何掌控文学关注度的走向这一累积性的努力过程可视化了。那么在标准文本的一成不变的表面之下究竟发生了什么?它与青空文库的建构过程是否完全一致?由于1949年至2007年间高中教科书里选录的散文体虚构作品数量较少,这导致档案重叠问题的相关性大大降低。尽管其中总共收录了13,000部作品,但是它们中的大部分在如此广泛的出版物中的出现频率极低,因此很难设想它们能够像文学选集中的作品一样对文化想象力产生同等力度的影响。除诗歌和非虚构作品之外,在教科书中出现频率最高的前100部作品里,有87%的版权已解禁作品(55部)同时也被青空文库收录。如果重叠不是一个有效的度量标准,那么读者的阅读习惯肯定是。青空文库从2009年开始会每月发布一份报告,用以记录每一部作品的用户访问次数。表3和表4的最后一栏分别提供了基于这些数据的作品排名和作家排名。我们可以感受一下其中的巨大差异,在2009至2017年间,夏目漱石的小说《心》的访问量超过了400万次,而中岛敦的《山月记》在同一时间段内的访问量是200万次。在将数据全部合计之后,夏目漱石作品的总访问量已经超过1,700万次,而排名第20位的樋口一叶作品的访问量是77万8,822次。[47]
从被访问次数最多的作品排名表(也包括标准文本前三名)中可以一目了然地发现,高中文学经典对青空文库的访问流量有着重大影响。这些课文的排名之所以往往很高,是因为老师们以及他们的学生发现在线阅读这些文本很方便实用。但是其他被访问最多的作品和作家又怎样呢?我们是否应该期待在哪几代被分发了教科书的高中生和青空文库的用户偏好之间,又或者在后者与几代选集编辑的总体决策之间出现更多的重叠?鉴于制造出这些排名的时间尺度、制度背景和媒介平台各不相同,重叠的可能性似乎很低。但是即便如此,还是有必要去考虑用一种整体性的方式对各个列表进行比较,并对那些排名不靠前的条目也能够做出解释。有好几种方法可以用来衡量各个排名列表之间的相关性,但在这里我选用的是经过调试的肯德尔等级相关系数(Kendall’s tau statistic),以确定五个列表中排名前50位作家的相互匹配程度。图15显示了每一对列表的测算结果,颜色越深表示相关性越高。从图中我们主要可以了解到的是,与高中教科书相比,青空文库与选集的一致程度更高,而高中教科书与选集的一致程度非常低。尽管标准文本非常引人瞩目,但是总体而言,课程上的选择并不能很好地预测哪些作家会被青空文库的用户阅读最多。[48]
通过这个相关性矩阵,我们把许多迄今发掘出的日本现代文学的核心样本尽可能地拉回到其诞生的语境中去。我们将作品列表缩减为作家排名列表,并将其进一步转换为有序的数字字符串,以便用统计学的方法对其进行测算。毫无疑问,这是一个令人迷惑的视角,因为单个文本和作家都像是被埋藏在冰层和土壤层中的细微颗粒一样,退回到了各自所属的核心样本之中。我们的首要意愿可能是撕开那些表层,将每一个微粒从其被绑定的单一语境中解放出来,并且从多重的解释角度出发重新将其暴露在光线之下。它值得我们采用还原论的视角将注意力聚焦片刻,因为它本身就是一系列解释性选择和统计操作的结果。这样做的目的不是为了对青空文库和印刷档案之间的关系提出一种标新立异的解释,而是要绘制一份裂隙与河谷的临时地图,在这幅地图中,青空文库对日语文学的再现与这些档案中的知识相互碰撞。在最大尺度,同时也是在最低分辨率之下,我们有一种方法去解释青空文库如何被文本选择和价值判断的各种不同历史所影响,因为这些历史已经在几个相互交叉的美学、商业以及教育的语境中被揭露出来。青空文库的传记是由这些早期的档案记忆工具编制而成的,尽管现在它已经开始编织自己的传记模式。我们知道,青空文库抓到了外国文学领域的几个亮点,尽管是互不关联且零零碎碎的。它与在战前被选集和教科书奉为经典的作家密切相关,虽然它并不总是将注意力转向那些作家的作品。它为那些以前在相同的选集和教科书中留下了微弱痕迹的大众文学作家弥缝出了一个宏阔的篇章。而且在最后,我们知道它也非常符合那些将女性作家边缘化的模式。
展望未来,我们将会根据其他书目记录轨迹对这张多视角地图进行扩充和修订。目前为止分析的问题还应当被视为用来构建所有种类样本的潜在资源,并且得到进一步的探究,这意味着我们需要确定什么样的问题群才有可能将这些样本导向有意义的推断。比如,在一个特定时期内被选录最多的作品是否共享了某些特定的形式或典型特征?什么样的特征使得一个时期的流行作品有别于其他时期的流行作品?不过,这些都不是本书要讨论的问题,本书会更多地关注战前的文学生产领域,关注当时特有的错综复杂的问题。若要解决这些问题,就需要有针对性地将青空文库递补为一个方便样本(convenience sample),在使用它的档案轨迹时,要采用比使用本章所提供的书目记录轨迹时更为细密的尺度。当然,这些轨迹将会继续约束着我们对青空文库所提供的独特视角的总体理解,而且随着证据规模从下一章的几百个文本增加到最后的几千个文本时,这一视角也将会越发宏大。作为这一进程的前奏,我们有必要简略地审视一下青空文库的大致边界,以及它的有限性会将自身引向哪些问题群。
二、青空文库的界限
我在发掘书目记录的过程中采用了几项技术,以便把数据集的轮廓线描绘出来并将之可视化,与此同时,这也是要提炼出一组文本所能够处理的研究性问题集。如果将这些技术应用到青空文库中的日文小说,特别是将其精确地应用于那些文本长度超过文库平均值的作品(例如文本长度大于或等于林芙美子的《下町》),那么一些内在于样本之中的限制就会显露出来。[49]如果根据首次出版日期对语料库子集进行绘图就会发现,大部分作品出现在1908年到1954年之间,而且高度集中在1925—1940年间(图16)。由于在这一时段之外每年只有不到12个文本,这导致我们对这一时段之外的纵向分析不再可靠。与之相反,这一时段内的趋势很有可能是由那些构成了图表中间峰值的大量文本所驱动的。另外一点是,这个文本群自1920年代初开始形成并在1930年代末发展到顶峰,至少如前文引用过的《出版年鉴》数据所显示的那样,这个过程与同时期的图书出版总量的上升趋势大致相当。不过,《出版年鉴》数据还显示,1897至1910年间曾经出现了同等规模的出版热潮,但是这一点在青空文库中几乎没有得到体现。即便我们承认文学出版物在前一个繁荣时期占出版总量的份额较小,但是其中明治末期小说的匮乏再次表明,这个语料库最适合用来讨论1910年左右及其后历史范围内的问题。
在上述历史范围内,合适的问题区间会进一步受到被再现的作家和作品的限制。该语料库中总共有174位独特的作家,其中有19位是女性(11%)。她们的作品共有126个,占总数的7%。尽管这个数据凸显了青空文库中小说在总体上的性别不平衡,但是这个较小的语料库也保留了高雅作家与大众作家的多样性(图17)。当我们按照语料库中的作品数量进行排名时,前20名作家中有一半与历史或大众类型的小说密切相关,比如野村胡堂、海野十三、冈本绮堂、吉川英治、佐佐木味津三以及菊池宽。另一半大多是经典作家,他们的作品在书目记录数据集中得到了很好的体现,比如泉镜花、太宰治、芥川龙之介、森鸥外以及夏目漱石。不太知名的丰岛与志雄和牧野信一在选集和教科书中的数据表现较差,但是他们在同时代的文坛很有名气,并且自那时起汇集了忠实的追随者。这种在文类和受众层面的相对多样化,对那些试图发掘两次世界大战之间文学生产的广泛程度的分析而言是个好兆头。正如新近的研究所示,这些分析渴望把在那些年间被积极建构和争夺的“纯文学”与“大众文学”之间的历史界限模糊化。本书的后几章将会利用这种多样性从风格、形式和话语层面去测试和干扰那些界限。

不过,要做到这一点,还必须考虑到一组额外的约束条件。如果该语料库在作者和文类层面表现出多样性,那么它在作品层面就会存在更强的同质性,至少那些很有代表性的大众作家是如此,比如野村胡堂和冈本绮堂。在野村胡堂的126个作品中,有114个是属于《钱形平次捕物控》系列,这个系列始于1931年,终于1957年,总共有将近400集篇幅不一的剧集。每一个新的剧集都是在继续讲述江户时代侦探钱形平次与他那忠诚的助手八五郎的冒险之旅。顺带一提,冈本绮堂在他快20岁时就以《半七捕物帐》开创了这一亚文类,其中有62个剧集收录在前述精简版语料库中。进一步的考察还揭示,许多历史小说作家都是经由数量有限的连载小说出现在语料库中。但对于侦探和科幻小说的作家(如海野十三和久生十兰)而言情况并非如此,不过尽管如此,该语料库中仍然有400多个作品归属于一个更大的系列。鉴于此类系列作品大多是情节性的,它们的叙事内容在每一个部分之间也有先后不同,因此将它们视为单一作品并没有太大意义。但是我们必须考虑到,当单个系列或单个作家的作品数量过多时,会为我们进行大规模分析带来偏差。通过创建更为均衡的样本来控制这些偏差,我们可以将系列性的重复或作者风格造成的局部效应描述为一种总体趋势(即特定词语在使用上的增加)。
这些偏差,连同我们已经指出的那些一般性和暂时性的偏差,共同界定了这个文库的“外部界限”。本章的大部分内容聚焦于如何通过与其他印刷档案的大型核心样本进行比较进而勾画出这些界限。尽管我们意识到了这些界限对于思考这个特定的数字样本所能解决的文学史问题至关重要,但是这种意识的目的不是要将该语料库作为一个(非)代表性列表或静态的经典样本加以回护(或批判)。相反,这种意识意味着它将会引导我们远离那些追求绝对精确和绝对满足的神话——因为根本就不存在一个完美的图景——并且走向这些体量巨大的文库所能提供的“关系推理模式”。[50]因为这个语料库可以被细分和被再平衡,我们在其基础上可以创建不同类型的样本,而我们可以通过这些样本来分析特定的现象;因为它的局限性在提示我们,让我们可以用其他文本和其他种类的证据对它的某个部分进行补充,并以此扩大它能够解决的问题数量;最后,因为它自身可以与其他样本和案例研究相互关联,进而能够对它们所提供的关于大规模文学趋势的证据进行确认或使其复杂化。
关于最后一点,还要考虑青空文库小说语料库如何允许我们重复访问和复制一些本书第一章曾经提及的对文学变化趋势的调查研究。如果利用我们的语料库,将安本美典对文学文本中汉字平均百分比变化的分析重新测算,就会发现它将显示出一个介于1900—1955年间的类似的下降趋势(图18)。从绝对值来看,这一结果显示每1,000个日文字符中的汉字数从大约200个下降到了150个左右,安本美典估算的汉字数是从393个下降到了295个。从相对值来看,我们测算出的下降25%与他测算出的下降30%很接近。一方面,鉴于我们的样本中的变化大多发生在数据量较少的一端,因此需要谨慎对待;另一方面,这一趋势被近似地重新描绘出来了,这也进一步证明该下降趋势是一种真实的变化背景,因此它也是一种可以将个人作品置入其中的有意义的语境。

与上述类似,我们还可以重新创建桦岛忠夫(かばしまただお/Kabashima Tadao)和寿岳章子(じゅがくあきこ/Jugaku Akiko)绘制出的那个情节,以便探索文学段落中的名词比例如何与MVR或者与动词之于形容词和副词的比率相关联。图19绘制出了该语料库中的词性统计情况。[51]图中的虚线表示两个变量的第2.5个和第97.5个百分位(percentile),在这个范围之外的,是相对于名词比率和MVR值总体分布的异常值文本。这个情节重复了他们的发现,即名词的增加与较低的MVR值呈负相关(例如,与动词相比,形容词和副词更少)。放大视野来看,因为有了更为宽泛的比较语境,它也带来了新的异常值。尽管井伏鳟二和谷崎润一郎之前分别是最具“概括性”(summarizing)和“描述性”(descriptive)的作家,而现在最具“概括性”的变成了历史小说作家森鸥外,最具“静态描述性”(statically descriptive)的变成了儿童文学作家宫泽贤治,最具“动态描述性”(dynamically descriptive)的则是现代主义风格作家堀辰雄。
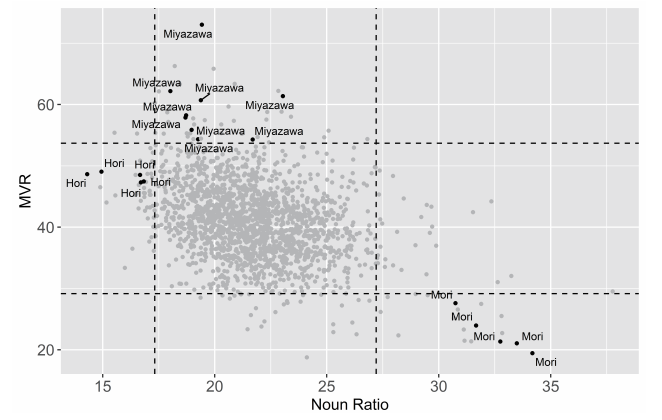
在更为巨大的青空文库语料库中涌现出这些新的异常值,使得本章开头讨论的“证据缺口”问题重新成为焦点。让我们回想一下,桦岛忠夫和寿岳章子拓展了波多野完治的早期工作,即利用句子长度和词性来区分谷崎润一郎和志贺直哉的创作风格。反之对于波多野完治而言,他当时是在尝试验证一位文学评论家的定性评价,在这位评论家看来,谷崎润一郎和志贺直哉的风格与众不同。随着比较尺度的不断延展和每一个证据缺口的逐步收窄,一个有关差异性的崭新形象得以实现,并且在这些图表所描绘的更为宏大的趋势中,解读特定文本的例外性与典型性的新方法也随之显现。志贺直哉被井伏鳟二取代了,而井伏鳟二最终又被森鸥外取代了。那么我们是否应当因为最后一个数据较之前的更为详尽,从而认为它更具决定性?详尽本身——这是一个无法企及的极点,在那里一切都被读取了——并不是事实或真理的保证。它永远只不过是一个想象的整体、一个制造事实的工具,在整体上被承认为事实之前,它需要“政治的和认知的”投入。[52]在一系列不断转换的差异性形象之中,比如本文所描绘的那些,很容易让我们优先将尺度作为真理的最终决定因素。但是在知晓了青空文库与书目记录之间的各种不一致之后,更为慎重的做法似乎是将尺度视为一场持续的、未完成的协商,去讨论何谓部分、何谓整体;去讨论这个整体需要显露多少才足以被看到;去讨论所有可能缩小部分与整体之间差距的方法,从而在更大的统一体中构建出更富有意义的变异体或典型性。
在本章开头的题词中,约瑟芬·迈尔斯(Josephine Miles)也暗示了同样的协商,她指出诗歌或其他审美对象的“质量的确立”往往是基于对数量的假设,而后者未经证实,并且超出了“总体印象”(general impression)的范围。但是这些“艺术的试金石”(touchstones in art)、这些被千挑万选并且在某方面最具独特性和特殊性的“珍品”(rarities),也会因为“它们在不同读者之间的易变性”而变得脆弱不堪。迈尔斯认为,我们现在需要认识到诗意“一切尽在其中,最好的也在其中”(all that is in it as well as the best that is in it),并以此给诗性之美“增加一些描述性的比例”。[53]如果文学评论家不再以“质量”来界定艺术对象的特性,那么我们就能够另辟蹊径,为继续关注那些个案所具有的“稀有性”(rarities)和解释上的弹性赋予合理性。但是案例研究仍然具有价值,这恰恰是因为它不会让一个文本的“丰富多彩”从属于那些对多个文本进行比较时所需要的抽象框架。比较总是会牵涉到描述文本的维度的缩小,特别是随着比较空间的扩大。[54]它们的内在相关性和局部意义片段被纳入了更高阶的结构和关系,正如斯坦利·费希(Stanley Fish)所说,这些结构和关系会阻碍“人类和语境将变化无常且丰富多彩的意义附着到任何正式布局的数字上”。[55]
为独特性而阅读的确是文学研究作为一门学科的基石之一,而且它也应当继续如此。但是在实践中,正如迈尔斯几十年前所建议的,以及其他研究者反复指出的,即便是最专注于特殊性的解读,也从未使自身完全脱离人们对相关数量的比较或假设。正如勃兰特(Lauren Berlant)提醒我们的,即便我们强调个案的不可还原性,但案例研究总是徘徊在“单一性、一般性和规范性”之间,或者如艾伦·刘(Alan Liu)所讲述的新历史主义轶事那样,将案例研究褒扬为对历史过程的随机访问,这放在历史过程的任何位置都是不确定的。一旦出现一种超越该案例的概括性——宣称该案例为一个更大整体的异常、典型或征候——那么一种定量逻辑就会开始发挥作用。研究者必须要对所有可能的语境的重要性做出假设和选择,因为这些语境很有可能会影响到文本的意义(例如传记、历史、话语、政治、可读性)。案例研究也许会试图再现由文本本身造成的语境的收缩,但这只会凸显艾伦·刘对“随机性决定或决定的随机性”的矛盾的愿望——即渴望立刻超越历史的束缚,同时又要看穿它们并从中择取与自己的解释最为相关之物。隐藏在这一愿望背后的,是一系列对语境的选择,而这也类似于数据库检索。
这是一个关键事件。它有一套微型设计,能够让人感知到它或许是某个尺度更大的模式的一部分。如果我们使用这个微型设计对整个历史数据集进行筛选(例如在SQL中,“从历史选项中选择作者、作品,关键词=‘自然’(nature)或关键词=‘拿破仑’(Napoleon)以及选择年份>‘1802’”),那么它看起来将会呈现出何种样貌?还有哪些其他“命中项”可以导向模式的识别(如“认知”“心理”“结构”“权力”的识别)?[56]
如果这被解读为对历史主义方法的戏仿,那么使这个幽默之所以有效的部分原因在于,数字档案和关键词检索已经深刻地介入并影响了学者们构建部分与整体、文本与语境之关系的方法。对更多证据的获取,以及通过这些证据实现更加快速的检索方法,已经迫使人们重新面对几个世纪以来的不同概括模式——那些潜藏在单个作品研究中的以及那些经由档案基础设施而得以更新(或得以可能)的模式——之间的对抗。尽管这种对抗由来已久,但是与早期的数据表格(numerical table)、词汇索引(concordance)和大型计算机(mainframe computer)相比,这些新近的基础设施将如何被应用到学术研究的实践当中,使得这种对抗显得更加激烈。对一部分人而言,忽视我们为“建构质量”所掌握的所有可用的证据已经变得越发困难,尤其是,尽管通过细读案例可以获得启示,但是仅仅依靠这一实践无法获取相关描述的语境和尺度。不过需要说明的是,此处说我们应当更加关注这些证据,并不是要摒弃那些启示,也不是要把解读的责任转交给尺度本身以及那些使这个尺度变得可知的算法。正如我所论证的,我们可以利用多方数据和多种方法缩小证据缺口。同时,这些方法可以视为是在尝试建构或模拟部分与整体之关系的代表性,它们本身变化无常、多种多样,但每一个步骤都要受制于相应的解释。
要辨别出这一点,其实也就是要辨别出贯穿在案例研究和非案例研究之中的连续性。我已经通过选择和抽样的语言处理了这些连续性,这套语言将“代表性”的语言转换成了完全不同的要素。这套语言,无论是在其统计学或社会科学的语域(register)中,还是在其更具人文主义的变体中,都将针对普遍性的认识论(即我们如何对待更大整体内部的或与之相对立的那些个体的多样性)进行编码。在某种程度上,文学史家都在被迫处理更大体量的证据,即便这些证据的片面性和不完整性已经为人所知,但是我们必须要学会这套语言,并且将之运用于我们自身的批评目的。这意味着要利用内容分析(content analysis)以及其他基于准则的资源和实践,而且这自然也会就如何以及在何时进行抽样引发持续的辩论和协商,即如何以及在何时构建外在于且超越单个文本的整体。[57]由于它牵涉到这种协商,因此也要求研究者们在面对历史遗留下来的一堆又一堆档案碎片时,要明确它们的样本的“代表性”。只要有人渴望撬开那个关键性判断经常操控的黑匣子,就应当是值得欢迎的。再次重申,数字档案是一个机会,它让我们重新思考单个文本的多重意义,重新思考当我们将这种多重性投射到更大关系尺度中的离散维度(discrete dimension)时,文本解读将注定获得(和失去)什么。
(编辑:姜文涛)
注释:
本文译自 Hoyt Long, The Values in Numbers: Reading Japanese Literature in a Global Information Age, New York: Columbia University Press, 2021, Chapter 2 “Archive and Sample,” pp. 69-127。 此章第一部分已经以《档案与样本——以日本青空文库和日本现代文学研究之关系为例》为题发表于《山东社会科学》2021年第11期,第50—58页。感谢本书作者和译者授予中文版权。
[1]青空文库中的重复项大多是以原初的或现代的正字法格式转录文本造成的结果(比如同一个作品会有旧体假名和新体假名两种版本)。本实验所用的全部作品都是利用青空文库提供的数据库索引从青空文库网站(https://www.aozora.gr.jp/)上提取下来的。有关用于获取文本的代码,我已经在芝加哥大学的文本光学实验室为这些作品制了一个易于检索的版本。可点击:https://artflsrv03.uchicago.edu/philologic4/aozora/。
[2]平均数(average)在本文中是统计学概念,还可以被细分为中位数(median)和众数(mode)两种计算方式。——译注
[3]在两种情况下,我都使用了筑摩书房的版本,以此确保相关的可比性。
[4]中村光夫在《日本的近代小说》(1961)中就曾提出过这个著名的观点,并且在此脉络上列举出了永井荷风的相关论断。乔纳森·茨维克(Jonathan Zwicker)曾讨论这种观点的各种含义,见Jonathan Zwicker, Practices of the Sentimental Imagination: Melodrama, the Novel, and the Social Imaginary in Nineteenth-Century Japan, Cambridge, MA: Harvard University Asia Center, 2006, pp. 29-30。
[5]See Zwicker, Practices of the Sentimental Imagination, chap. 3; Indra Levy, Sirens of the Western Shore: The Westernesque Femme Fatale, Translation, and Vernacular Style in Modern Japanese Literature, New York: Columbia University Press, 2006; Karen Thornber, Empire of Texts in Motion: Chinese, Korean, and Taiwanese Transculturations of Japanese Literature, Cambridge, MA: Harvard University Asia Center, 2009.
[6]在日语中的固定名称为“円本(えんぽん)”,意思为“1日元1本”。——译注
[7]Akikusa Shunichirō, “Jutsugo Toshite No ‘Sekai Bungaku’: 1895-2016,”Bungaku, vol. 17, no. 5, September 2016, p. 10.
[8]有关这些选择情况的讨论,参见:Brian Dowdle, “Why Saikaku Was Memorable but Bakin Was Unforgettable,” Journal of Japanese Studies, vol. 42, no. 1, Winter 2016, pp. 106-109; Ishii Jun, “1910 Nendai Ni Okeru Toshokan Sentei Jigyō—Toshokan Hyōjun Mokuroku O Chūshin Ni,”Toshokan to Shuppan Bunka, Yayoshi Mitsunaga Sensei Kiju Kinenkai, 1977, pp. 55-68; Akikusa, “Jutsugo Toshite No ‘Sekai Bungaku’: 1895-2016,” pp. 7-9。
[9]Mary Hammond, Reading, Publishing, and the Formation of Literary Taste in England, 1880–1914, Aldershot, UK: Ashgate, 2006, p. 94.
[10]Hammond, Reading, Publishing, and the Formation of Literary Taste, pp. 91-92.
[11]这则广告的影印件可参见:Obi Toshito, Shuppan to shakai, Genki Shobō, 2007, pp. 198-199。
[12]人人文库的图书列表可查看:A. J. Hoppé, The Reader’s Guide to Everyman’s Library, London: Dent, 1960。
[13]Obi, Shuppan to shakai, pp. 195, 198-199.
[14]Hammond, Reading, Publishing, and the Formation of Literary Taste, pp. 106-107.
[15]这个百分比是通过交叉引用图书和下文描述的大正和昭和时代文学翻译的综合索引得出的。
[16]Obi, Shuppan to shakai, pp. 201-202.
[17]See David Damrosch, What Is World Literature?, Princeton, NJ: Princeton University Press, 2003; Giselè Sapiro,“Globalization and Cultural Diversity in the Book Market: The Case of Literary Translations in the US and in France,”
Poetics, vol. 38, January 2010, pp. 419-439; Priya Joshi, In Another Country: Colonialism, Culture, and the English Novel in India, New York: Columbia University Press, 2002; B. Venkat Mani, Recoding World Literature: Libraries, Print Culture, and Germany’s Pact with Books, New York: Fordham University Press, 2017.
[18]“Meiji-ki hon’yaku bungaku sōgō nenpyō,”Meiji hon’yaku bungaku zenshū, ed. Kawato Michiaki et al., ōzorasha,vol. 5, 2001. 受限于运行OCR时遇到的挑战,每个条目只抓取到了出版年份和初始语言。
[19]Meiji·Taishō·Shōwa hon’yaku bungaku mokuroku, ed. Kokuritsu Kokkai Toshokan, Kazama Shobō, 1959.
[20]对于外国文学如何经由现代主义诗歌杂志实现流转的分析,见Hoyt Long, “Fog and Steel: Mapping Communities of Literary Translation in an Information Age,”Journal of Japanese Studies, vol. 41, no. 2, Summer 2015, pp. 281-316。
[21]出版数据来自《出版年鉴》,这是一份年度交易刊物,用于重新发布政府关于出版趋势的统计数据。截取这个时间段是因为这项统计直到1881年才开始,而1943—1949年间没有记录。在理想情况下,应当根据分散的成卷图书计算百分比,而不是根据单个翻译作品,但是大正/昭和时期的元数据无法聚合到成卷的级别。关于明治时期的翻译数据,特别是对作为一个行业的文学翻译的具体分析,参见:James Hadley, “The Beginnings of Literary Translation in Japan: An Overview,”Perspectives: Studies in Translation Theory and Practice, vol. 26, no. 4, 2018, pp. 560-575。
[22]在一项最早有数据支撑的文学翻译研究中,太田三郎发现,有一组根据上野图书馆和日本笔会的卡片目录记录编纂的数据集中出现了类似的低迷期。他还发现原创作品的出版率并没出现相应的下降。他认为,除“大逆事件”之外,日俄战争和第一次世界大战爆发应当也造成了这种低迷。参见:ŌtaSaburō, “Hon’yaku bungaku,”Iwanami kōza nihon bungaku-shi, vol. 14, Iwanami Shoten, 1959, p. 21。
[23]John Galsworthy, Shūto sono hoka, trans. Ōtani Gyōseki, Dai Nihon Tosho, 1914. 顺便一提,大谷绕石在1909—1911年间曾被日本文部省派往伦敦留学,师从小泉八云(Lafcadio Hearn),而他在1920年代翻译小泉八云的著作。
[24]用更为专业的术语来说,一个显著的p值意味着有证据可以拒绝零值假设:线性模型中与每个子样本相对应的系数都相等,因此与整个样本相对应的模型应当也一样。为了确定p值,要将每个拟合模型(整个样本和两个子样本)的残差平方和汇总到一起,并生成乔氏(Chow)统计量,然后再根据参数数量和样本规模将其与F分布的检验统计量进行比较。
[25]值得注意的是,2018年修订的版权法并没有恢复1968年以前去世的作者的版权。它只是将1968年以后去世的作者的版权延长到了70年。
[26]Edward Mack, Manufacturing Modern Japanese Literature: Publishing, Prizes, and the Ascription of Literary Value, Durham, NC: Duke University Press, 2010, p. 112.
[27]有关这套选集的历史,详见:Wada Yoshie, Chikuma shobō no sanjūnen 1940-1970, Chikuma Shobō, 2011, pp. 237-243;Onoue Yukio, Shuppan gyōkai, Tokyo: Kyōikusha shinsho, 1991, pp. 180-182。
[28]Nakamura Mitsuo, “Literature Under the Occupation,” trans. Atsuko Ueda, Politics and Literature Debate in Postwar Japanese Criticism 1945-1952, ed. Atsuko Ueda et al., Lanham, MD: Lexington Books, 2017, p. 258.
[29]John Guillory, Cultural Capital: Problem of Literary Canon Formation, Chicago: University Of Chicago Press, 1994, p. 30.
[30]转引自Mack, Manufacturing Modern Japanese Literature, pp. 97-98。
[31]斋藤美奈子指出,1950年的《图书馆法》促进了新型公共图书馆的建设,而1954年的《学校图书馆法》规定每一所中小学都要有自己的图书馆,这大大增加了对参考图书和选集的需求。Saitō Mineko, “Nihon Hungaku Zenshū to Sono Jidai (Jō): Zenshū Ga Shuppan Bunka O Riido Shita Koro,”Bungei, vol. 54, no. 1, 2015, p. 44.
[32]Mack, Manufacturing Modern Japanese Literature, pp. 94-95.
[33]完整记录见Hashimoto Motome, Nihon shuppan hanbai-shi, Tokyo: Kōdansha, 1964, pp. 366-376。
[34]当涉及作家选集的时候,日外索引就显得不那么全面了,它只收录了桥本列出的24套选集中的4套。不过,这个索引还收录了几套桥本没有列出的作家选集。
[35]Takashima Kenichirō“, Kadokawa Shoten Shōwa Bungaku Zenshū No Hanbai Senryaku-sengo Zenshūbon Būmu to Bungaku Jōkyō O Megutte (1),”Kindai bungaku kenkyū, vol. 21, 2004, p.1. 他认为,纸张生产的变化是推动全集出版的主要因素,因为政府取消了各种限制后,纸张生产变得更容易、更便宜。
[36]Saitō Mineko, “Nihon Bungaku Zenshū to Sono Jidai (ge): Kongon No Rokujū Nendai Kara Zenshū Baburu No Hōkai Made,”Bungei, vol. 54, no. 2, 2015, pp. 350-353.
[37]作者标签取自新潮社的《日本文学辞典》,并且适应于日外索引中的每一位作者。针对不在辞典中的作者以及日外索引中有10个或更多条目的作者,我采用其他参考文献(比如维基百科)自行手动标注。对于从事多种文类创作的伟大作家(如岩野泡鸣、宫泽贤治、长冢节、佐藤春夫),他们的小说作品都是手动标注。
[38]对于多产的诗人来说,这个问题可能会进一步复杂化,因此我剔除了那些仅致力于收录诗歌的综合性选集。
[39]Takashima, “Kadokawa Shoten Shōwa Bungaku Zenshū No Hanbai Senryaku,” p. 4. 对《野火》而言,文本长度当然不是一个限制性因素,即便按照绝对数量来计算,它也是被选录最多的作品。志贺直哉的史诗著作《暗夜行路》在被选录最多排名中位列第五。
[40]开始此项调查的一个组织是“日本笔会”,它是一个全国性的文学协会,大多数作家和诗人在战后都加入其中。在一份1979年公布的官方名册中总共有1,109名成员,其中13.6%是女性。该名册来自Iwaya Daishi, Nihon Bungeika Kyōkai gojūnenshi, Tokyo: Nihon Bungei Kyōkai, 1979。根据最新的一项定量研究成果,在两个多世纪的英国小说中,女性作家的人口比例发生了变化。参见:Ted Underwood, David Bamman, and Sabrina Lee, “The Transformation of Gender in English-Language Fiction,”Journal of Cultural Analytics, February 2018,https://people.ischool.berkeley.edu/~dbamman/pubs/pdf/ca2018.pdf。
[41]“过采样”(oversampling)是信号处理领域的术语,是指用远远高于信号带宽的频率对信号进行采样。在本文中意指提高受影响群体的文本采样频率,以便抵消其在各种选录过程中受到的忽略乃至抹消。与之相对的反向操作为“欠采样”(undersampling)。——译注
[42]苏真、朱远骋和我讨论这些问题,特别是当它们涉及到种族问题时。Richard So, Hoyt Long, and Yuancheng Zhu, “Race, Writing, and Computation: Racial Difference and the US Novel, 1880-2000,”Journal of Cultural Analytics, January 12, 2018, https://culturalanalytics.org/article/11057.
[43]在一份由青空文库收集的包括1,014位版权已解禁作家的名单中,女性作家占比仅略高于5%。
[44]Anno Izumi, Nichigai AsoshieÌ-tsu, Kyōkasho keisai sakuhin 13000: yonde okitai meichōannai, Nichigai AsoshieÌ-tsu, 2008.
[45]有关文学史与中学国语教育及教科书的关联,参见:Ken K. Ito, “Reading Kokoro in the High School Textbook,” paper presented at Sōseki’s Diversity: A Workshop, University of California, Berkeley, CA, May 2015;Ishihara Chiaki, Kokugo Kyōkasho No Shisō, Chikuma Shobō, 2005;Sano Miki, “Sangetsuki” Wa Naze Kokumin Kyōzai to Natta No Ka, Taishūkan Shoten, 2013。
[46]《舞姬》在高中教科书中出现最多时是在1985年,占到了25%,之后便开始下降。需要记住的重要一点是,教科书分为很多个年级,而且每个年级都有特定的标准文本。此表格中的百分比呈现的是所有年级教科书的总体情况。关于《山月记》在战后的经典化,参见Sano, “Sangetsuki”Wa Naze Kokumin Kyōzai to Natta No Ka。
[47]为了便于比较,我将外国作家和前现代作家都排除在了这些名单之外。但值得注意的是,紫式部、格林兄弟、埃德加·爱伦·坡、亚瑟·柯南·道尔都在被访问次数最多的前20名名单中。
[48]在选择适当的统计数据用来对列表间的相关性进行衡量时,我们首先必须要确定是否存在一个客观真实的排名,或者这些列表是否是在没有客观真实排名的情况下由观察者制作而成。在此,本文是后一种情况,我想衡量各种观察结果之间的匹配程度。第二个需要考虑的是,各个排名之间是否有关联。我们的数据的确如此,因此它也需要经过修改调试后的肯德尔等级相关系数,参见Julián Urbano和Mónica Marrero所做的研究, “The Treatment of Ties in AP Correlation,”ICTIR, vol. 17, Proceedings of the ACM SIGIR International Conference on Theory of Information Retrieval, October 2017, pp. 321-324。第三个需要考虑的是,人们是否更愿意给予那些榜首排名之间的匹配程度更多权重,而不是对全部排名一视同仁。对此,研究者可以使用AP相关性统计加以衡量。我在此并不偏爱排名靠前者。
[49]我采用平均值作为分界点或许有些武断,但是也有必要限制语料库的规模,如此才可以确认每一部作品的首次出版日期。但是需要特别注意的是,作品的首次出版日期并不总是与青空文库中收录的版本一致。文库的志愿者们通常更愿意选用选集中的作品,而不是最早出版或最早连载的文本。关于这种对选集的依赖所造成的变化和省略的范围与规模,还有待进一步的研究。
[50]关于“外部界限”的概念和一个巨大样本的“关系推理模式”,参见:Ted Underwood, Distant Horizons: Digital Evidence and Literary Change, Chicago: University of Chicago Press, 2019, pp. 176-178。
[51]本书中的所有文本都利用MeCab标记器和UNIDIC词典做了词性切分和词性标记,以便进行形态分析。UNIDIC词典代表了日语文本自动词法分析的当前水准,它由日本国立国语研究所的语言学家所开发。
[52]这个短语借自德罗西埃,他描述了随着各种统计流派中抽样方法的发展变化,这些政治的和认知的过程如何帮助定义了“一个贴切的整体”以及“代表性”的概念。参见:Alain Desrosières, The Politics of Large Numbers: A History of Statistical Reasoning, trans. Camille Naish, Cambridge, MA: Harvard University Press, 1998, p. 234。整体经由概念过程变为了事实,就像经过集体协商一样。
[53]Josephine Miles, Major Adjectives in English Poetry: From Wyatt to Auden, Berkeley: University of California Press, 1946, pp. 306-308.
[54]从认识论和伦理角度对比较进行批评的研究,参见:Natalie Melas, “Merely Comparative,”PMLA, vol. 128, no. 3, May 2013, pp. 652-659。
[55]Stanley Fish, “What Is Stylistics and Why Are They Saying Such Terrible Things About It?,”Is There a Text in This Class?: The Authority of Interpretive Communities, Cambridge, MA: Harvard University Press, 1980, p. 134.
[56]Alan Liu, Local Transcendence: Essays on Postmodern Historicism and the Database, Chicago: University of Chicago Press, 2008, pp. 259-260.
[57]先前引用的Bode、Piper以及Underwood的著作,是在将抽样作为方法论和认识论实践时发生的最典型的争论。