


编者按:
马修·威尔金斯(Matthew Wilkens)现为康奈尔大学信息科学学院副教授,他使用定量和计算方法来研究文学和文化史的大规模发展,尤其侧重于文学文本挖掘、地理位置提取、文学文体检测,以及批评和社会科学方法的交叉融合。在康奈尔之前,他曾在美国韦恩州立大学(Wayne State University)和圣母大学(University of Notre Dame)长期担任英文系和美国研究的教职。他博士毕业于杜克大学文学项目,是理论家詹明信(Frederic Jameson)和芭芭拉·史密斯(Barbara Herrnstein Smith)的学生。威尔金斯的学科职业转型,即从文学研究转向信息科学,为我们提供了一项有趣的观察案例。此处收录的三篇文章从文本挖掘、网络分析、文学社会学、文学地理学等方面,以具体案例入手,讨论数字人文方法对于研究文学和文化史大规模发展变化的意义。
马修·威尔金斯 / 美国康奈尔大学信息科学学院
陈大龙(译) / 浙江大学国际联合学院
计算方法并没有掌控人文学科。即便是广义上的数字人文领域中,人数也并不多,而且其中只有很小一部分人从事主要由数据驱动的研究,从事比较研究的则更少。但是,文学学科对量化研究的好处和所谓的危险有浓厚的兴趣的原因,却并不难被揭示。因为长期以来,这些学科几乎完全以定性的方式进行研究,但他们所面对的源材料,体量却常大到令人棘手。一般来说,数字人文,具体来说是计算辅助的文学研究,提供了一套新的方法来处理这种大规模的材料。这些方法能够产生新型的证据,并可与现有的方法结合使用,以使人文研究能够以更丰富、更包容的方式开展。计算工作已经开始兑现这一承诺,尽管有社会和技术上的障碍,但未来的前景尤为光明。
计算方法最直接提供的是,基于不同的规模帮助识别和评估文学模式,从单个文本到文化生产整个领域和系统都可行。当然,这并非计算机唯一擅长的,但这是一个有用的起点,因为它表明新旧方法之间具有基本的连续性。实际上,文学学者的观点在一定程度上也包含了量化的、基于模式的成分,并依赖于他们所处理文本的简化模型。但是,这种程度往往被低估了。正如我说过的,若要说明某些晚期现代主义小说使用了寓言和百科全书式的知识来回应战后文化环境中高度现代主义表现手法的不可行性,就要能够证明这些特征在文本中确实是存在的,而且它们与你可能期望找到的其他(不存在或未被强调的)方面存在着显著的区别。另外,如果想要说明你的阅读选择是有道理的,就还要证明你所发现的特征在某种意义上是典型的,或者反映了当时发生的重要变化。然而,当你这样做的时候,就会局限于文本中的某些方面,因为这些方面抓住了你致力解决的那些问题,而你会几乎忽略掉文本中这个子集以外的所有特征。对于论证的部分,你很可能不会用数字形式为之建构框架,而是取决于一种合乎情理的感觉,这些具体的特征分布于一系列相关文本之内。简而言之,要基于此为研究的问题域和文本的位置建立一个抽象的可量化模型。我的论点是,在很多情况下,无论从概念上还是从证据上,这个过程最好都是清晰明显的,而不要(仅仅)隐含于其中,因此,文学研究对定量方法的需求其实很大。实际上,现在文学和文化研究已取得的各种不同的成果,能够令人信服地说明这一点,而这主要是通过产生新的证据并将其运用于社会文学分析来实现的。[1]
另一点看起来也很清楚,文学和文化研究中许多规模宏大的问题都最适合使用计算分析,包括那些属于世界文学和长时段文学史的问题,这些都与系统论提出的问题类似。这两个领域之间尚未有更多的交叉融合,也许是由于数字人文科学近来在北美以英语母语为主的研究机构中获得关注最多,但他们对系统论的关注相对不足,也是由于比较文学院系中数字人文研究者不多(这些院系最乐意接受伊曼纽尔·沃勒斯坦[Immanuel Wallerstein][2]、尼克拉斯·卢曼[Niklas Luhmann][3]、西格弗里德·J.施密特[Siegfried J.Schmidt][4]等人的作品)。但是,许多最好的计算研究,包括下文要探讨的对文本生产、接受和传播网络的关注,都带有社会学和系统性导向。这表明,系统论更明确地参与进来,将是数字人文崛起的一个几乎不可避免的结果。[5]
文本挖掘和变形(Deformance)
采用成熟的计算方法帮助实现较容易识别的文学目的,最近的一个例子是安德鲁·派珀(Andrew Piper)和马克·阿尔吉-休伊特(Mark Algee-Hewitt)在歌德全部著作中,选取《少年维特之烦恼》(以下简称《维特》)进行语言特征研究。派珀和阿尔吉-休伊特称他们的方法为“拓扑阅读”(topological reading),意思是这种方法适用于研究不同文本中的词汇共现的模式。[6]当然,他们的目标并非简单地对这些模式进行计数,而是利用它们追踪《维特》在歌德后期作品中的影子。
尽管这种方法输出的结果很复杂,他们的论点也很微妙,但是分析过程的技术细节却很易懂(见图1)。他们计算了《维特》中每个词的出现次数,删除了像der、die和und这些本身语义内容很少的高频功能词,然后比较了剩下的(确切地说,是91个)最常见的词在歌德出版的其他作品中出现的频率。为了给《维特》和其他文本的拓扑结构之间的相似性提供一个单一的衡量标准,他们在所得到的九十一维空间中计算了其欧几里得距离。令人高兴的是,实际上这并不像听起来那么困难,只要比较两个文本中每个词的频率,然后把它们的差加起来。[7]根据这一标准,这91个词的使用频率与《维特》接近的文本,在图上的距离就近;反之,词频模式差别较大的文本,距离则更远。最后,派珀和阿尔吉-休伊特将所有两两成对的距离测量结果降维生成图1中二维的维诺图(可类比于将地球仪压成地图的过程,只是相比于地图上的每个地点,此图中每个文本的最终位置有更大的自由度)。图1中每块多边形区块都对应着歌德的一个文本。相距较近的多边形表示它们在使用这91个《维特》词的比率上更为相似,尽管这些词不一定就是“维特式的”(Wertherian)。所谓“维特式的”,即经常出现在《维特》中,而不常出现在其他文本中(它们经常出现在《维特》中,但除了剔除的所有文件中的停用词之外,对于仅在《维特》中常见的词和在所有文本中都常见的词,该方法并不做区分)。同样,根据所使用的频率分布距离测量方法,与小多边形区块相比,大区块则与歌德语料库中的“均值”文本的相似度更低。

图1 根据《维特》中的常用词对歌德作品集中的文本进行排列[8]
派珀和阿尔吉-休伊特对他们的数据的处理也许并不是你所想象的那样。他们对《维特》的中心地位(或缺乏中心地位;它是图1左边缘附近的那个白色多边形)、长期以来认为的歌德早期与后期写作风格之间存在的断裂(以这种方式评估的话,其实并不是什么断裂)有一定的兴趣,对这两个问题他们的计算评估都给出了略有不同的看法。但他们的分析大都脱胎于继丽莎·萨缪尔(Lisa Samuels)和杰罗姆·麦甘(Jerome McGann)[9]之后、斯蒂芬·拉姆塞(Stephen Ramsay)所称的计算批评的“变形”(deformative)本质,[10]以及这两位作者所称的拓扑阅读的“变形引擎”(variation engine)。[11]我的意思是,他们把大量时间花在阅读页面尺度的新组合上,这些新组合来自他们的算法产生的两个顶层文本簇。具体来说,他们先将聚类于《维特》附近的文本打散成页面大小的片段(每页200词),接着将最初应用于整个语料库的程序再运用于这些片段,以产生相似和不相似页面的子簇。然后,他们将相同的计算方法运用于离《维特》中心较
远的一个文本簇(在图1中这两个文本簇都用黑线廓出了)。他们这样做并不是为了定位出某种经过计算得出的“维特性”(Wertherness)的本质,而是作为一个机会(也可以说是借口,但并无责备的意味),发现一种不同类型的原始材料,并对其进行一种看起来更合乎传统的细读。比如,在这篇长文中,他们花了一篇短论文的篇幅来解读“手”(hand)。他们将手作为在距离《维特》最近的文本“页面”片段中,与艺术生产联系在一起的、使文本统一起来的角色。对在距离《维特》较远的顶级文本簇中构建的另一个此类文本,他们也做了同样的解读,认为它代表了从具体的艺术知识转变为更普遍的对基于观察的认识论的思考。
派珀和阿尔吉-休伊特最引人注目的主张是,歌德的早期和晚期作品之间存在着强烈的潜在连续性。由《维特》的词汇所产生的词簇具有一致性和可解释性,就可以表明这一点。这有可能略微夸大了《维特》的联系作用,因为该小说中的高频词不一定是其独有的(他们的文章结尾处承认了这种可能性,并认为这是今后研究的一个方面)。但他们的方法反映了一个完全合理的解释选择,即在相似性的框架内强调差异的作用。这一事实也提醒我们,在定量工作中,解释和收集证据是不可分割的。不管这个具体问题的结果如何,派珀和阿尔吉-休伊特的分析展示了计算辅助文学批评的主要好处之一。这种方法使他们能够围绕一组新的前提重新配置歌德的语料库,并为他们提供机会将该语料库作为一个新的陌生的对象来阅读。我们对于主要作家、文本和运动的研究,往往都陷入了根深蒂固的批评叙事。这种陌生化常会是一个难得的、有价值的事件。
网络分析和文学社会学
与对文本细读分析的依赖截然相反的,是以文学生产和消费的文学社会学为主要目标的研究。弗朗科·莫莱蒂最近大部分的研究都属于这一范畴。但这种研究的必要性和潜力在苏真(Richard Jean So)和霍伊特·朗(Hoyt Long)对美国、日本和中国的现代主义文学网络的研究中展现得尤为清晰。苏真和霍伊特·朗对文学网络的结构很感兴趣,这既是理解20世纪初全球现代主义发展的一种手段,也是思考影响传播和诗歌形式之间关系的一种新方法。正如他们自己的文献综所表明的那样,在这个层面上他们所涉及的领域并不新鲜,但他们的方法是基于对与之相关的各种证据进行深刻的重新概念化。
苏真和霍伊特·朗使用的不是文学文本的语料库,而是关于这些文本的元数据,其形式是数百种诗歌和文学杂志的出版记录,不同国家的数据时间跨度分别为1915年至1930年(美国)、1920年至1944年(日本)和1911年至1949年(中国)。他们对这些数据进行了网络分析,按年份计算每个作者在各期刊上发表的诗的数量,并根据这个数量将相应的作者与期刊联系起来。[12]他们将数据可视化,形成大家已比较熟悉的图表,如图2所示。
他们的发现有两个重要的方面。通过对基于杂志的现代主义诗学进行比较描述,他们观察到三个国家背景之间存在重要差异。在美国,这个网络由杂志《诗歌》(Poetry)主导,这一时期的主要作家许多都与其有联系。但也有许多二级和三级集群,每个集群都组织了自己的诗人群体;一般来说,集群之间是由少数作家联系在一起的,他们的诗风更加不拘一格。在日本,这个网络则基本上分为两大阵营,而两大阵营之间几乎完全由《诗神》(Shishin, Muse)弥合。这说明日本的诗歌氛围更加两极分化,而《诗神》在日本现代主义的发展中发挥了核心作用。中国的数据更为稀少,不过看起来期刊促进了更为排他的小团体的发展,这一点可由多渠道发表作品的诗人数量很少这一现象见出。这显示了一个极端巴尔干化的文学图景,如要在这里发展出一个整体的或标准化的现代主义形式,机会要少得多。

图2 美国诗歌的网络结构,1917—1918年[13]
除了有关社会结构的不同演变方式的新证据之外,苏真和朗还借用社会学文献中的“掮客”(brokers)概念,论证了他们所称的诗歌领域的“掮客”的重要意义。通常这些诗人所处的梯队,现在被认为是仅次于当时最有影响力或最成功的作家,这些诗人起到了连接原本不相干的团体的作用。他们指出,诸如艾米·洛威尔(Amy Lowell)和康蒂·卡伦(Countee Cullen)这样的“掮客”,似乎都被至少部分地被排除于任何单一的内部小圈子之外,因此被剥夺了小圈子的领导人所具有的影响力和声望,他们往往只在他们团体的类旗舰杂志上发表作品。[14]对“掮客”中介作用的关注表明,对美国的洛威尔和卡伦,或日本的近藤东(Kondō Azuma)、竹中郁(Takenaka Iku)、北川冬彦(Kitagawa Fuyuhiko)和尾形龟之助(Ogata Kamenosuke)等诗人的研究具有新的意义。更概括地说,这意味着仍然需要这样适合社会结构定位功能的批评方法。此举标志着广泛意义上的结构主义考察再次兴起,苏真和朗的研究为其带来了一种比较和历史主义意识,使其区别于社会和语言结构主义的经典形式。
聚类和图谱
有的计算方法试图通过直接从大量文本中提取信息来描述文学创作领域特征,这些方法是介于文本变形(textual deformance)和社会学结构之间的。其中一些方法类似于派珀和阿尔吉-休伊特使用的方法,因为它们都依赖于识别词语共现的模式。这类方法还包括,诸如主题建模和其他文本分类算法。这些技术已经被一系列学者使用,特别是在使用单一语言进行研究的学科中,并取得了良好的效果。例如,在《大分析》[15]中,马修·约克斯(Matthew Jockers)通过功能词计数、主题建模以及派珀和阿尔吉-休伊特采用的距离度量等方法的组合,构建了一个有关19世纪英美小说影响的详尽地图。约克斯的书是近期唯一以专著篇幅探索文学研究的计算方法的著作,非常值得一读。因为它展现了一系列定量研究方法和运用这些方法进行研究的具体结果。浪漫主义文学研究者泰德·安德伍德(Ted Underwood)用相关的方法来评估18和19世纪文学辞藻的演变、20世纪批评实践的变化以及庞大的HathiTrust数字档案的一般构成。[16]
地理空间和文学关注的模式是比较文学研究者特别关心的领域。其中最受瞩目的数字人文项目是斯坦福大学的“文学共和国地图”(Mapping the Republic of Letters)。该项目试图建立一定时期的通信数据库并可视化为一系列可定制的交互式地图,来扩展帕斯卡尔·卡萨诺瓦(Pascale Casanova)等人在该方向上的研究。这个项目与苏真和朗的研究一样,强调元数据而非计算内容分析。
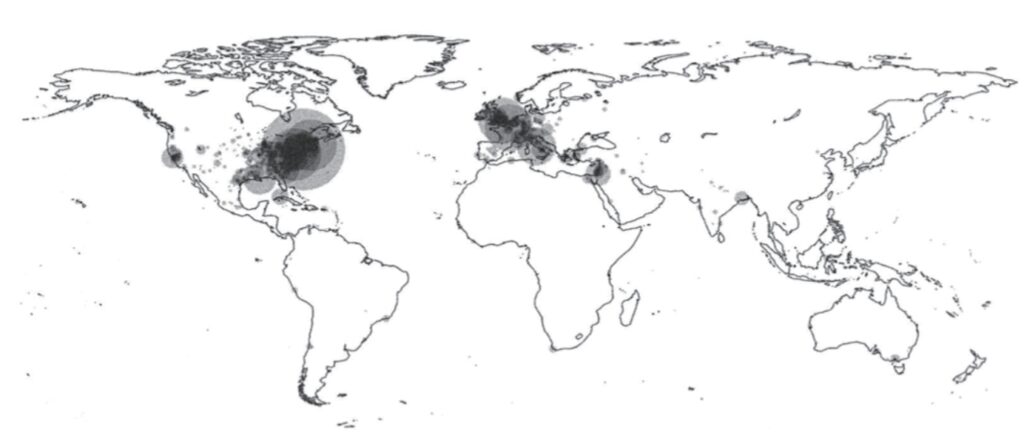
图3 美国小说中所提及地点的全球分布,1851—1875年[17]
我自己的研究,如图3所示,是使用自然语言处理技术来识别文学文本中的地名,并将这些地名与具体的地理坐标联系起来。就美国南北战争前后出版的小说而言,这种方法提供的证据表明,美国作家表现出了明显的对大西洋两岸和国际性的文学关注,在所有提及的地点中,有40%以上都是美国疆域以外的。它还显示出,所提及的美国国内的地点绝大多数都在新英格兰之外。也就是说,文学注意力在于追踪人口的西迁和南方的政治事件,而非想象的固守于清教徒的老据点。因此,这些数据表明了,19世纪美国文学的视野越来越多地向国外扩展,同时指出了与移民和城市化相关的国内人口和经济增长是该时期文学关注的显著驱动力。
从派珀和阿尔吉-休伊特对歌德的研究,到苏真和朗的现代主义者网络,再到约克斯的影响图、安德伍德的批评谱系和文体分析,以及我的文学地图,所有这些案例的学术贡献都体现在两个不同的领域。这些研究介入了已有的或新出现的重要辩论,对其研究的文学对象的本质和功能提出了具体的主张。它们是计算辅助文学批评所呈现出来的成果,意在独当一面,即使它们往往只代表了一个大的阐释项目中的一个步骤。同时,它们就整个文学领域配置提供了广泛和真正的新的背景信息。与文学史或社会学中现有的几乎所有学术研究所提供的信息相比,这种信息都有质的不同,这并非因为使用数字就一定更好,而是正如莫莱蒂所指出的,因为这样的领域“通过拼接有关个案的支离破碎的知识点是理解不了的”。[18]文学生产体系可能是由书组成的,但其本身并不是书,就像大象并非一大堆细胞一样。因而,计算方法能够提供有关整个领域的信息,甚至可以帮助最传统的批评家理解他们有时自称在研究的文学体系,以及他们所研究的一个个单独的文本的大背景。
问题与未来的方向
尽管这里描述的计算方法很有价值,但是要将这些方法广泛运用于比较文学和国别文学研究仍有一些很大障碍。撇开这些学科强烈的方法论保守主义不谈(这种保守常冠以“捍卫人文学科”的愿望,以避开任何可能对细读有所补充的实证方法),存在三个最大的问题。一个是法律和技术问题:收集语料建立适合计算分析的语料库可能很困难,尤其是1923年之后的许多文本仍然在版权保护期内。这也是现在许多计算研究的对象集中于18、19世纪文本的原因之一,这些文本可以免费获得进而被数字化(尽管并不总是那么容易)。但是,这些时代的文本可能既稀少又“有污损”,缺乏高质量的元数据,或者包含大量的转录错误(这往往是对印刷不规整的文件进行自动文本识别的结果)。而20世纪的文学作品汗牛充栋,因此自然也是最迫切需要计算方法的地方。HathiTrust数字图书馆及其相关的研究中心正在提供帮助,它们拥有超过一千四百万册数字化图书(涵盖多种语言,初版时间跨度覆盖16世纪至今),这些图书来自图书馆的扫描项目,包括规模宏大的谷歌图书。显然,HathiTrust的藏书中存在元数据错误和转录错误,而且要访问其版权保护期内的众多藏书还有一些具体问题仍在解决之中,但目前看来它仍将是未来几年内真正的大规模文学作品的唯一最佳来源。不过,对于那些依赖于清晰的原始输入或要绝对完整地覆盖某一时期或地区的研究项目来说,则仍需要更专业和更高质量的语料库,而建立并管理这些语料库资源仍将是相对有难度的。
第二个问题与人有关。目前,人文学科中很少有学者接受过进行计算研究所必需的技能和方法的培训。由于学术和市场的原因,这种情况正在发生变化,但要每个研究生都至少有基本的定量研究能力,近年内仍不可能。比较文学学者多在不同系所工作,并且要研究不同国家的文学传统,这增加了他们获得培训的机会。尽管如此,比较文学学科在这方面仍一定程度上受制于其规模过小。有幸,我们并不是最早发现定量方法使用价值的学科。我们仍能受益于大学中角角落落里现有的大量专业知识,即使我们不可避免地发现必须要改造他人的技术,以适应我们特殊的研究需要。
最后,比较文学和比较文化研究尤其需要应对跨语言研究的挑战。本文讨论的技术对源文本的依赖程度是有所不同的,但它们大多都以某种方式有赖于词汇计数并评估词汇共现的模式。这些技术可以应用于任何语言的文本,但要对运用同一技术处理不同语言的源文本得到的结果进行比较研究,通常却很难。事实上,前述苏真和朗的研究就具有这样的优点:它依赖于出版物元数据分析而非全文分析,这使他们能够相对直接地比较英语、日语和汉语(其实,只要有合适的数据,任何其他语言也都可以)的现代主义诗歌创作体系。但这个困难倒还不至于令人举步维艰:长期以来,比较文学家或个人或集体都具有以多语言文本和过程为研究对象的优势。考虑一下前述项目所研究的一系列文学史现象:全球现代主义、欧洲浪漫主义、跨大西洋文学形成、文学共和国,这些现象的发展都是规模宏大的、多语言的、跨越全球的,但在各国的发展却并不平衡,因此它们才特别需要计算分析所能提供的新型证据。但正出于同样的原因,它们也属于比较研究的经典对象。数字人文学科需要比较文学研究者,正如比较文学研究者需要计算方法一样。
(编辑:姜文涛)
原文信息:Matthew Wilkens,“Digital Humanities and Its Application in the Study of Literature and Culture,”Comparative Literature, vol. 67, no. 1, March 2015, pp. 11-20. 。翻译及出版已获得作者允许。
注释:
[1]除了本文其他地方引述的学者外,感兴趣的读者还可参考以下作者的作品,例如: David K. Elson, Nicholas Dames, Kathleen R. McKeown,“Extracting Social Networks form Literary Fiction,” Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics, ed. Jan Hajič et al., Uppsala: Association for Computational Linguistics, 2010, pp. 138-147; Michel Jean-Baptiste, Yuan Kui Shen, Erez Liberman Aiden, “Quantitative Analysis of Culture Using Millions of Digitized Books,” Science, vol. 331, no. 6014, 2011, pp. 176-182; Timothy R.Tangherlini, Peter Leonard,“Trawling in the Sea of the Great Unread: Sub-Corpus Topic Modeling and Humanities Research,” Poetics, vol. 41, no. 6, 2013, pp. 725-749。当然, Morreti的作品仍是许多人的起点:Moretti Franco, Graphs, Maps, Trees: Abstract Models for a Literary History, New York: Verso, 2005。
[2]Immanuel Wallerstein ed., The Modern World-System in the “Longue Durée”, London: Paradigm, 2004.
[3]Niklas Luhmann, Social Systems, Trans. John Bednarz Jr., Dirk Baecker, Stanford: Stanford University Press, 1995.
[4]Siegfried J. Schmidt,“ Literary Studies from Hermeneutics to Media Culture Studies,” CLCWeb:Comparative Literature and Culture, vol. 12, no. 1, 2010, http://dx.doi.org/10.7771/1481-4374.1569.
[5]就这种导向而言,系统式思维在文学研究方面明显的试金石包括: Wai Chee Dimock, Through Other Continents:American Literature across Deep Time, Princeton: Princeton University Press, 2006; Paul Giles, The Global Remapping of American Literature, Princeton: Princeton University Press, 2011; David Damrosch, What Is World Literature?, Princeton: Princeton University Press, 2003; Pascale Casanova, The World Republic of Letters, Trans. M. B. DeBevoise, Cambridge: Harvard University Press, 2004。 当 然 还 有 弗 朗 科· 莫 莱 蒂( Franco Moretti)。
[6]用他们自己的话说,“拓扑学关注的是词语的重现,是语言在一定距离内自我重复的方式。……拓扑学让我们更多地从行动上思考语言(它做什么),而非从意义上理解语言(它说什么)。它向我们展示了,文本中的词汇重复模式是如何产生意义的,而这些意义并不局限于或内在于这些模式。拓扑学中符号的功能,不是意义,而是组织”(第157页)。完整的方法论细节可在他们的论文中找到: Andrew Piper, Mark Algee-Hewitt,“The Werther Effect I: Goethe, Objecthood, and the Handling of Knowledge,” ed. Matt Erlin, Lynn Tatlock, Distant Readings: Topologies of German Culture in the Long Nineteenth Century, Rochester: Camden House, 2014, pp. 155-184。关于对拓扑学本身更多的理论讨论,见Andrew Piper,“Reading’s Refrain: From Bibliography to Topology,” ELH, vol. 80, no. 2, 2013, pp. 373-399。
[7]好吧,这其实并没有那么简单:你要对差进行平方,求和,再取平方根。你实际在做的就是运用九十一维的毕达哥拉斯定理进行计算,而不是在小学时就可能学过的二维的。在二维空间中, A和B两点之间的距离可以表示为

,其中x是A和B在一个维度上的投影距离, y是它们在另一个维度上的投影距离。派珀和阿尔吉-休伊特对x1、 x2、……xm进行同样的计算,其中, xi表示《维特》中最常见的91个词之一在任意两个文本之间使用频率的差(不包括已删除的功能词)。
[8]图表来源: Andrew Piper, Mark Algee-Hewitt,“The Werther Effect I,” p. 158。经许可转载。
[9]Lisa Samuels, Jerome McGann,“Deformance and Interpretation,” New Literary History, vol. 30, no. 1,1999, pp. 25-56.
[10]Stephen Ramsay, Reading Machines: Toward an Algorithmic Criticism, Urbana: University of Illinois Press, 2011, p. 32.
[11]Andrew Piper, Mark Algee-Hewitt,“The Werther Effect I,” p. 169.
[12]用技术术语来说,作者和杂志都是节点,这些节点由一些无向的线条连接,而这些线条则表示一个诗人在一份杂志上所发表的诗歌。线条是根据所发表诗歌的数量加权的(一般按年份划分)。
[13]图表来源: Richard Jean So, Hoyt Long,“Network Analysis and the Sociology of Modernism,” Boundary 2, vol. 40, no. 2, 2013, pp. 147-182。经许可转载。
[14]苏真和朗指出了他们所讨论的文学上的掮客与社交上的掮客是不同的。后者更多由高知名度的作家主导,比如庞德( Pound)或休斯( Hughes)。
[15]Matthew L. Jockers, Macroanalysis: Digital Methods and Literary History, Champaign: University of Illinois Press, 2013.
[16]关于文学词藻问题,见Ted Underwood, Jordan Sellers,“The Emergence of Literary Diction,” Journal of Digital Humanities, vol. 1, no. 2, 2012, http://journalofdigitalhumanities.org/1-2/the-emergence-of-literarydiction-by-ted-underwood-and-jordan-sellers/;关于批评期刊的专业实践问题,见Andrew Goldstone, Ted Underwood,“The Quiet Transformations of Literary Studies: What Thirteen Thousand Scholars Could Tell Us,”New Literary History, vol. 45, on. 3, 2014, pp. 359-384;关于文体问题,见Ted Underwood et al.,“Mapping Mutable Genres in Structurally Complex Volumes,” Proceedings of IEEE International Conference on Big Data, Santa Clara, California, 2013, http://arxiv.org/abs/1309.3323。
[17]Matthew Wilkens,“The Geographic Imagination of Civil War-Era American Fiction,” American Literary History, vol. 25, no. 4, 2013, p. 809.
[18]Franco Moretti, Graphs, Maps, Trees: Abstract Models for a Literary History, New York: Verso, 2005, p. 4.