


北京大学数字人文研究中心
包平(南京农业大学数字人文研究中心):方志物产知识库实践与思考
我先从三个小问题谈起。
第一,我们常说中国地大物博,“地有多大”能够精准测量出来,但是“物有多博”目前还没有具体的数字。随着生物多样性的发展,尤其是微生物的演化,很多物种是难以被精确计量的。但是,对于肉眼能够观察到的物种,我们能否获得一个相对准确的数字,以及是否能够从历史文献的角度为物种的演变和消长提供一定的线索呢?
第二,“一方水土养一方人。”例如,稻作文明(区)与麦作文明(区)养育的人、长江以南与长江以北的人在长期的历史中,所形成的文化与心理是有差异的。Science杂志2014年刊发的文章“Large-Scale Psychological Differences Within China Explained by Rice Versus Wheat Agriculture”[1]对这个问题进行了研究,结论指出:不同的环境孕育不同的人。
第三,中国传统哲学讲究天时、地利、人和,但并未探讨人和万物的关系。长期以来“物”的方面是被淡化的,其实人与万物应当是共生共存的关系。从文献记载来看,从早期记载物产的神话和传说,到地记、图经、志书等的定例描述,从花草鸟兽虫鱼到现代科学的界、门、纲、目、科、属、种的分类演变,体现的是人类认识自然的过程。我们今天的讨论就从“物产”开始。
这里所说的“物产”源于古代的“博物”,主要指动物和植物,涉及少量的矿物和作为手工品的货物。
“物产”一词较早出现在西晋时期张华的《博物志·物产》中,含有颇多神话、灵异色彩,与宋代以来的含义、指代范围均有不同。北魏时期贾思勰的《齐民要术》主要反映了北方黄河流域的农耕技术,但也介绍了少量的南方物产。唐代时期“物产”一词的使用已比较普遍,正史、区域史、游记、文学作品等均有记载,但指代范围仍较为笼统。宋代以来,志书类文献开始系统性记载物产。
方志(地记、图经)是中华文明独有的一种历史文献,传统地方志文献约占我国存世文献古籍的十分之一。1985年中华书局编撰的《中国地方志联合目录》记载了我国历代(1949年以前)方志8,264种,“爱如生—中国方志库”(前3卷)共收录方志4,997种,“中国数字方志库”共收录方志约11,000种(含部分国外游记)。
早在方志雏形《山海经》与《尚书·禹贡》中就有“某地生某物”的描述,两宋时期特色物产成为方志的基本内容,明清以来方志中涉及的物产信息逐渐全面且系统。在不同历史时期的志书中,物产的记录经历了从单纯作为内容的一部分到专列类目,从只记载物产之名称到物产之下详加注解,从以传统话语描述物产到使用近现代科学话语体系进行书写的过程。
许多前辈学者为方志物产文献的整理工作做出了卓越的贡献。1956—1958年,万国鼎先生主持《方志物产》的抄写工作,组织了100余人参与摘抄和校对,40多个城市、100多个文史单位参与其中,完成了7,532部地方志的摘抄,形成了3,600多万字的专题资料汇编。即《方志物产》446册(含补遗15册),与《方志综合》120册、《方志分类》120册并称学界“红本子”,1958年李约瑟还专门到研究室查阅该资料。
在时间维度上,《方志物产》涵盖了宋代以降的旧志,即从北宋熙宁九年(1076)的《长安志》到民国三十八年(1949)的《定西县志》,其中清代方志数量最多,约4,400种;空间维度上,涵盖了国内所有行政区划,目前最多的是河北(479种),最少的是新疆(5种);内容来源上,除了总志、通志、府志、厅志、州志、县志、乡镇志、乡土志、山志、湖志、关志、图志等外,还有一些罕见或广义方志,如物产集、地理志、风土志等。
《方志物产》是独一无二的古籍再造项目,是规模最大的中国地方志物产资料集成汇编。每册以空间为经,以时间为纬,经纬结合,方便查阅。记载的物产种类,在一定程度上反映了当时当地的民生状况,为社会史、经济史、农业史、生态环境史等研究提供了史料。该汇编记录的各地农作物、果蔬的种植历史及品种资源,可以为我们描绘动植物分布、变迁的地图提供参考,进而可辅助追溯和还原物种演变的线路图。
1962年3月15日,一位老先生在查阅并摘抄《方志物产》四川省目录索引时提出了几点意见和看法:1.《方志物产》可能还有遗漏,请逐地逐版地查阅有关方物资料,将一切有用资料全部搜集起来。2.遗产研究室没有按物产种类分编成册,使用不太方便。3.抄录方法:要注意将序跋注解录下来以便分析研究;以具体物产为对象,将有关此物的记载集中起来,便于统计。4.该材料的好处:可得作物在历史上的变化;循此研究栽培技术;了解物产背后经济情况的变化。5.注重对各种作物栽培起源、技术等情况的解释,可能是有用的珍贵资料。
在数字化的背景下,这位老先生所提的一些问题已经能够得到解决。20世纪末,王思明教授团队开启了方志古籍数字化保护和文本转换的工作,获得了科技部相关项目的支持,完成了《方志物产》从扫描图像到电子文本的人工转录与校对工作,为后续数据化、知识化、平台化奠定了坚实的基础。侯汉清教授团队开启了农业历史文献智能整理与知识组织的工作,开展了古籍文本的自动断句、自动标点、引书、本体构建、数据库建设等工作和研究,取得了古籍文本智能化整理与利用的可喜进展,相关项目获国家社科基金资助,并且培养了在科学技术史信息组织方向最早耕耘的学科带头人。
2008年,我们团队开始做这方面的工作,并于2018年获国家社科基金重大项目资助,开启《方志物产》的“数智化”时代。我们所做的主要工作包括五方面。
第一,对《方志物产》资料再辑录、整理与数字化,包括对方志物产资料查漏补缺、对古汉语文字信息化处理、根据资料描述制定元数据、构建基本素材库,重点解决“全”和“信”的问题。我们再辑录、补充了1,692种方志物产,目前总量已达到9,224种。经过辑录以后,现在方志最多的是浙江省(653种),最少的是宁夏(20种)。另外,完成了志书的格式化整理并构建素材库,基本可以实现物产的导入、导出、浏览、抽检、删除、修改、统计和用户管理等功能。
第二,在素材库基础上对方志物产资料进行多层级自动标注。这一部分工作有很多的技术难点,需要解决方志物产自动分词、方志物产自动断句、方志物产实体识别以及方志物产语料库构建的问题,这个语料库是在素材库基础上赋予它智能化的语料库,目前我们只抽取了部分语料,还处于做实验阶段的工作。首先,要制定一个“词汇级标注”体系,为构建方志知识库提供词汇级知识支撑,从词汇的层面了解方志物产整个文本的特征。然后,基于方志物产中描述物产语境的分布情况,结合古文语言学的特征,制定方志物产“分词与词性标注一体化”的规范。最后,结合分词、词性和实体标注任务,开发辅助一体化标注平台。我们使用的BI-LSTM-CRF模型在精确率、召回率和调和平均值上表现最佳,实体识别准确率达到98%以上,分词、词性准确率也达到了90%以上。2011年,我们在《中国图书馆学报》发表的实体识别准确率还只有63.38%,技术的进步超乎想象,但要达到领域专家认可的差错率,还有很长的路要走。
第三,面向知识服务构建方志物产资料库。首先,要采用深度访谈与问卷形式,面向领域学者开展方志物产知识库需求调研并分析。其次,基于知识组织理论与语义网技术提出方志物产资料语义知识组织框架,构建方志物产知识本体。再次,生成并发布涵盖物产、志书、人物、地名等实体的关联数据集,实现与外部数据源的知识聚合。最后,设计并实现方志物产知识库原型系统,提供知识检索、知识可视化、知识关联、用户研究平台等功能。
我们项目的物产知识检索功能分为随机浏览、简单检索、高级检索、分类检索四种,但分类检索仍限于志书原本的分类,对古今物产分类的映射依然是需要去解决的重要课题。物产知识库有物产名来源、来源方志、来源其他古籍、物产分类、物产记载地区、物产描述(方志与其他古籍)、相关诗句、百科知识、地图展示等方面,使用1582年、1820年、1911年这三个年代的地图来展现物产分布时空。
我们的知识库已经实现跟其他一些知识实体的关联,例如古籍实体关联到上海图书馆古籍循证平台,人物实体关联到CBDB、上海图书馆人名规范库,物产实体关联到搜韵网的诗句。因此,可以借助其他一些成熟的数据库来帮助规范被关联的知识。
在用户研究社区部分,我们设立了研究随笔、知识纠错、研究问答、个人网盘、他山之石等版块,研究人员能够自己上传资料、提出问题、回答问题、开展讨论。我们认为,方志物产知识库是数字人文研究领域基础设施的重要组成部分,应当将其纳入国家的基础设施建设中去,将来数字人文的很多研究需要有产品的产出,吸引更多研究者甚至公众使用。作为基础设施的知识库,不单单要能保存资料,还要能够便于使用,构建以用户为中心,以白板、工具集、社区为核心功能模块的产品,实现知识库的深度利用与服务。
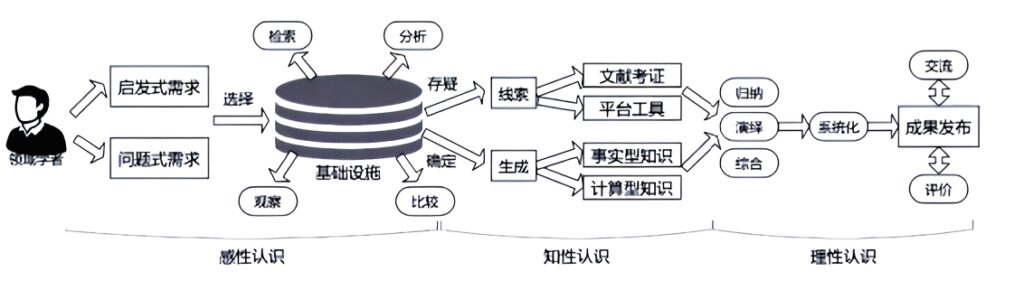
图1 基于方志物产知识库的数字人文研究框架设计[2]
如图1所见,我们当前的重点工作是第二单元“基础设施”,其后延续的单元如文献考证、平台工具、事实性知识、计算型知识,以及归纳、演绎、综合的部分,都还需要领域内专家的参与。知识库从最初的需求调研到最终的结果解释乃至将来的使用,会形成一个跟专家高度配合的闭环,如果缺乏专家和大众的参与将很难获得持续发展。
第四,方志物产知识的发现与考证。在知识库发布的时候,有一些问题是需要解决的,例如怎样对物产多维度关联数据集和方志物产隐含知识的解读,终端用户需要何种的可视化呈现,以及对方志物产知识的智能考证等,都还需要大量人工加智能的考证来支撑。当前,我们借助地理信息系统及社会网络分析等技术与方法,尝试做过某一地区某些物产的分布情况、基于社会网络的物产—人物关联分析、某一物种在某一时期的迁移问题等研究,开展了方志物产史料中物产分布与传播、物产名与人名之间等网络关系知识发掘与可视化呈现探索,这对指导农业生产、了解物产分布与多样性具有一定参考意义。物产研究不同于人物研究,存在同物异名、同名异物、信息不详和不准的难题,需要智能考证。我们也对此做了一些技术上的探索和设计,文本中的描述关系、共现关系、属类关系,是将来做相关考证的基本元素和基本点。
第五,物产资料的深度利用研究,主要体现为物产与自然、社会、文化的关联。例如,动植物资源种类分布研究、物产时空变迁研究、物产与地方文化关系研究、资料开发与利用模式研究等。
目前,方志物产知识库可以预期的应用场景主要有三个:第一,将资料延伸至方志以外,建成中华物产全景,包括物产的分布、传播、时空与演化,方志物语文化、数智物产,生物与生态环境学意义,长江下游稻作,海南物产大全等主题。目前我们正在整理长江下游稻作与海南全境物产情况,其中《中华物产大全·海南卷》已经形成初稿,计划2023年6月由中华书局出版。第二,对物产功效的开发。例如,种质资源及其科学意义,地标物产、物产药用,物产的经济与社会价值等,这具有很高的现实意义。第三,文旅产品的开发。将物产的前世今生挖掘出来,通过讲故事的方式赋予地标产品人文价值和商业价值,提高产品的传播力度和经济价值。
下面谈谈应用场景之一——梳理方志物产资料,挖掘传统种质资源。其一,能够为生物种质资源普查提供线索。据统计,我们的知识库囊括了152万种次物产,每种物产平均27个字的解释信息,为农业种质资源普查提供最为全面、丰富、系统的文献依据。其二,为优良种质资源挖掘提供依据。例如,康熙三十年(1691)《苏州府志》记载:“六十日稻,四月种,六月熟,米小,色白,又名早红莲,又名救工饥。”说明当地可能存在这种早熟的野生稻种,能够解决灾害造成的饥饿问题,为水稻早熟基因的寻根提供了线索。其三,为恢复生物多样性提供指导。地方传统种质资源的存续是当地先民结合本地特有环境有意识选育的结果,与一定区域内独特的生态环境关系至密。比如,主要分布在今云南省文山壮族苗族自治州的文山三七,在乾隆二十三年(1758)《开化府志》、道光五年(1825)《广南府志》、民国二年(1913)《马关县志》中均有记载,现在适宜文山三七生存的环境已经发生变化,而方志的记载为了解文山三七的种植历史及适宜的生态状况提供了参考。
应用场景之二——地标产品的历史文化内涵挖掘。追溯和梳理历史上各类优质农产品(土特产)及其产地、贡区、出口区,摸清地标农产品家底,挖掘相关名人、诗词歌赋等内容,增加地标农产品的历史文化内涵。例如,乾隆四十九年(1784)《杭州府志》将龙井茶的来龙去脉、文人吟咏都详细记载了下来,内容丰富,值得深挖。
应用场景之三——药用物产的整理与利用。《本草纲目》记载了大量的药物,但还有部分《本草纲目》未收录的药物出现在方志物产中。例如,乾隆十五年(1750)《如皋县志》卷十七记载:“地丁,有紫白二种。生平地者抽茎,生水边者引蔓叶。似柳而微细,夏月开花如铃状。疮毒初起时,连根捣烂入酒同煮,或取汁搅酒中,饮神效。”短短数十字说明:在疮毒初期使用地丁泡酒,或者将地丁同酒一起煮,或者捣烂了搅拌于酒中,对疮毒初期治疗效果奇佳。这当然使我们联想到了青蒿素的发现。东晋时期葛洪所撰《肘后备急方》中有“青蒿一握,以水二升渍,绞取汁,尽服之”十五字,成为了现代科学去探索青蒿素缘何对疟疾有医学效果的重要线索。方志中还涵盖了防疫抗疫物产,从数据库智能抽取防疫抗疫物产信息,挖掘古人与传染病斗争的历史线索,对当下也能够有所启发。
应用场景之四——中华物产的媒介视域与记忆建构。提出数智物产概念,综合运用现代传媒手段,勾连有关物产的个体记忆与社会记忆、丰富物产记录场景,链接过去、回应当下、共向未来,形成中华物产交往记忆的建构模式,对破解当下古籍传播的普遍困境提供可借鉴的模式,使公众参与文化传承。
关于《方志物产》知识库的未来任务,首先是完成既定的研究任务(实验室研究),目前95%以上的任务已经基本完成,很快就能够申请结题,将来也会开放部分语料。其次是将局部语料的实验工作逐步扩展到对全语料的研究。然后是从方志物产扩展到全物产范围,更多地采集地方志以外资料中的物产内容。此外,还需要寻求合作,在文献层面和技术层面需要更多学者参与,共同攻克难题,在传播层面还需要企业和政府的介入和关注,更好地利用资源。
知识库的社会需求体现在多方面。从宏观层面讲,一是历史文献中蕴含的物产知识信息搜集、保存、整序(知识库、“数智物产”);二是物产资料中蕴含的深层面文化基因的激活,产出原创性文化产品;三是人文与数据科学的交叉融合(交叉学科),推动当代文史学家从大数据视角观察思考大问题,讲好中国故事;四是为构建中国特色哲学社会科学话语体系添砖加瓦。在微观方面,包括某物产(动物、植物等)的种养驯化、引进传播史,某地物产的种群调查及与自然、社会之关系,某一物产的前世今生、消亡物种的动因考证,物产分布、变迁的图谱(时间、空间、关系精准还原),种业、地标、药用等功效,物产的自然、历史与人文意义,等等。
当下的难点问题还比较多,比如版本差异与资料完整性,字和词的使用级(包括集外字难题)解决方案,别名、同物异名、同名异物的智能考释,地方志外有关物产的收集、知识关联与呈现,古籍智能化整理与利用过程中可复制的理论与技术体系,文献视角的物种变迁与基因视角的生物演进之间研究结论能否相互验证,等等。在新生和发掘的资源不断补充、技术取得突破性进展、研究应用持续深入的大环境下,我们期望能够有更多的学者参与到相关工作中。
2022年5月27日,习近平总书记在中共中央政治局第三十九次集体学习时强调:“对文明起源和形成的探究是一个既复杂又漫长的系统工程,需要把考古探索和文献研究同自然科学技术手段有机结合起来,综合把握物质、精神和社会关系形态等因素,逐步还原文明从涓涓溪流到江河汇流的发展历程。”[3]《未来简史》的作者也曾写过一段话,大意是现代科学从实验室到博物馆,是阴和阳的关系,实验室解决的问题最终要面向公众,产出产品。这对我们的知识库专题工作也有很好的借鉴意义和启发。文献研究是我们的看家本领,我们要把探索的内容跟考古的发现对接,跟自然科学技术的手段对接,使我们能够更好地去解读我们的历史。
尹小林(首都师范大学电子文献研究所):“国学宝典”数据库的建设与应用
(一)缘起:此情可待成追忆
1980年代中期,PC机在我国处在发展初期,主机上只有软盘驱动器,容量仅为360千字节。汉字使用国标一二级字库,仅6,763个汉字,字体很少,只有宋体、楷体、黑体和仿宋体4种。我当时在部队,成为了最早一批使用计算机的幸运儿。出于对古籍和传统文化的兴趣,我用业余时间录入了《四书》《诗经》《老子》《庄子》等基本典籍,此即十多年后诞生的“国学宝典”数据库的源头。
1993年,我认识了王利器先生,他向我引荐了一位中华书局的编辑,说这位编辑对我所做的数据库很感兴趣,这位编辑即后来主持出版文津阁《四库全书》的卢仁龙。1997年,我开发了一套具有逐字检索功能的《全唐诗》软件,在学术界引起了热烈反响。1999年,我开始做“国学宝典”数据库。在此过程中,钟敬文、金克木、庞朴、汤一介、乐黛云、方立天、杨成凯、傅璇琮、冯其庸、白化文、许嘉璐、程毅中、傅熹年、李零等一批专家学者,都是早期古籍数据库的超级爱好者,为“国学宝典”数据库建设提供了很多支持和帮助。
尤其庞朴先生,可以说是“国学网”“国学宝典”的引路人。当时注册“国学网”是用庞朴先生的身份证去登记的,这件事给我留下了非常深刻的印象。另外,庞先生对数据库的兴趣也是在众多学者中较为突出的。杨成凯先生是国内著名的版本学专家,我购买的许多珍贵古籍都与他的积极推荐有关。还有傅璇琮先生,他是清华大学中国古典文献研究中心的创始人,为我做历代笔记的专题数据库提出了很多指导性意见。冯其庸先生曾为“国学宝典”题字,同时他也是“国学宝典”的资深用户,我曾多次上门为他安装调试检索软件。许嘉璐先生对“国学宝典”亦情有独钟,他在2007年首都师范大学国学传播中心成立大会上,专门介绍“国学宝典”,称“国学宝典”有“多、便、佳”三大优点,希望我们把人文社会科学和现代技术结合在一起,把“产、学、研”结合在一起,走出一条创新之路。还有中华书局的程毅中先生,曾手书对联“莫愁宝典深于海,自有金针妙入神”,鼓励“国学宝典”的发展。在古文献方面,李零先生几乎解答了我提出的所有疑问。除此之外,詹福瑞、赵敏俐、刘跃进、刘石、杜晓勤等学者也为“国学宝典”的建设提供了非常宝贵的方向性指引。
正是由于这些专家学者的支持和参与,“国学宝典”才得以从最初的《全唐诗》专题数据库发展成为超大型综合古籍数据库。
(二)建设:一山放过一山拦
“国学宝典”是一套经过全面标点整理、专家审定、适用于互联网及移动终端的超大型古籍全文检索数据库,收录了先秦至民国两千多年间的1万余种历史文献,超22万卷,总规模达22亿字。分类体系兼顾传统四部和现代学科,分经、史、子、集、丛书五个大类,下设五十个子类。
这里特别提出一个概念——“元古籍”。现在普通读者阅读和使用的多是“整理古籍”和“古籍选编”,“元古籍”是针对存世线装书的数字化——一种系统、规范的数字化。我们所有的古籍整理、古籍检索、古籍研究工作,包括数字人文的数据库、知识库建设都应建立在“元古籍”基础上,否则很多工作将无法统一到同一个大的系统之中。
数据库的建设工作分为七个阶段:选底本、录文字、进平台、统规范、校异同、分类序、测产品。
第一阶段是选底本。现在有很多人以出版社整理出版的书为底本,作为录入的基础,但如果没有参看原书的话,在建设系统时会出现很多不协调的地方,因为古籍整理本不仅书写格式和字形与古籍原本不同,而且存在各种注释和校勘内容,包括前言、后记、附录、索引等,这些内容多与文献检索无关,甚至会影响检索结果。选择底本在文献学上属于“版本学”范畴,需要实实在在地接触到古籍原书,将其建设为最接近古籍原貌的数据库。以《过庭录》为例,同一书名的就有范公偁、楼昉、叶模、宋翔凤、汪大宗分别所撰的五种书,每一种书或许还存在不同的版本,比如叶模的书有27卷本和37卷本两种,宋翔凤的书有16卷本和5卷本两种。所以,在整理古籍时,一定要写明版本。

图1 胡适《尝试集》封面

图2 古籍文本中的“殷”字异体字形示例
第二阶段是录文字。依据最新的国家标准,使用规范字进行录入。录文字过程中可能会接触到几个专业术语:“活字”指现在仍在使用的字;“死字”指仅在某时间段使用的字;“残字”指断碑残简上的字,有时候可以与别的文献进行比对将残字识别出来。古籍整理如同下围棋,规则简单,容易入门,但要想精深却很困难,其中最大的困难即“古字无定形”。例如,胡适《尝试集》封面文字中的“尝”字和“附”字(图1),字形都有所改变,通常不这样写。另外,图2中“殷勤”的“殷”字,如果单独出现在其他文本中,不一定能够被辨识出来。《四库全书》数据库在文字录入时,严格保留底本原字形,降低了整理的难度,却为检索使用带来了不便。因此,《四库全书》检索软件做了一项弥补工作,即增加了汉字关联功能,古今字、形近字、错讹字、中日文字等经过关联以后,大部分都能被检索出来。但是,部分关联的异形文字在复制时会变成乱码,并且会产生较多的冗余数据。因为人工手写具有一定随意性,异体字、简笔字在《四库全书》中比比皆是。在整理本古籍中,异体字基本已经处理为规范字,录入数据时可作参考。对于专业的古籍数字化机构,整理古籍时一定要见到古籍原书,至少要见到影印本。
另外,录入文字时还可能会遇到一些字库中没有的生僻字,需要使用描述的方式进行表达,如“[利-禾+(序-予+(共-八+(人*人)))]=庶刂”“[(仁-二+尔)*也]”“[糸*尼]”等。再以“鉆”和“鑽”为例。现在的“钻”繁体应该是“鑽”。“鉆鑽之属”指古代的两种刑罚,“鉆”是钳刑,“鑽”是去掉髌骨,惨苦无极,在汉代以后就逐渐被废除了。但是,在国内专业的出版社所出版的简体字本(《后汉书·卷三》)中,这两个字被写成了“钴”和“钻”,以至于后面的注释文字都乱了,根本无法阅读。此外,还有古体和书法体,在录入时都需要进行处理。总之,录文字是一个非常专业的事情,绝非看起来那样简单。
第三阶段是进平台。平台是指能够对古籍进行常规管理的软件系统,从初校至再校、精校都在此进行,需要增加书名、作者名、文件名以及标引时的一些符号等,删去原书的书眉、目录、页码等无用信息。例如,《四库全书》中,每卷首页都出现的“钦定四库全书”六个字即属无用信息,需要删除。至于书名、作者名等是否该录入,以及怎样录入,都需要专业人员进行处理。
第四阶段是统规范。在数据库中处理繁简体、规范字形和标点符号(半角/全角)等的过程影响着数据整合,是古籍整理中必不可少的一步。就字的规范而言,在GBK字库中存在大量一字多形的情况,有的字不仅仅有繁简体,还有异体,如果使用Unicode码,则存在更多的异体字。异体字在古籍整理中有时是必不可少的,更多时候会使数据库变得混乱,如果文字录入以后不做规范处理,那么在使用软件检索时很可能造成误检或漏检。因此,在完成录入后,需要进行繁、简字体转换,并统一使用规范字,这是平台必须要做好的事情。
还有一些很特殊的现象。比如,香港整理的中医古籍中出现了“香港脚”“毒瓦斯”这样的词。我查阅原始文献后,发现是整理者在此做了自主改动,用“香港脚”代替“脚气”,“毒瓦斯”代替“毒气”,但其他部分都是按照古籍原貌处理的。虽然怎么做古籍整理一定程度上取决于整理者自己的意愿,但我认为数据库建设专家应该多了解一些训诂学知识,减少平台间的差异,避免产生新的讹误。
第五阶段是校异同。校异同包括版本选用、文字比对以及图形表格、特殊符号的处理等,这一阶段的工作决定古籍数据库质量。我们研发过自动比对、自动标点、自动排版的软件工具,有助于发现和处理古籍异同问题。在进行数据录入工作时,我曾看到一个“盖屋答间”的陌生书名,感觉文义难通。找到原书后,发现它出自李颙《二曲集》“集为门人王心敬所编,每卷分标篇目,曰《悔过自新说》……曰《盩厔答问》,曰《富平答问》……”,原来是王心敬所编文集中的一个篇名《盩厔答问》,“盖屋答间”系文本录入错讹所致。因为生僻字在扫描识别时容易被误解,出现一些“常用”错字,版本比对、数据校对就显得格外重要。
第六阶段是分类序。数据分类以后才能入库,成为可以使用的电子产品。尤其对于大型数据库而言,分类和排序是很重要的两项工作,与软件的功能息息相关。在海量“元古籍”的基础上,可以通过分类快速搭建各种专题数据库。“国学宝典”数据库已经录入了一万多种古籍,先后建设了中医古籍库、科技文献库、园林建筑库、女性文学库、书画艺术库、古代音乐库、古代文论库、古代小说库、历代日记库等20余种专题文献库。再补充一些数据,通过合理组合,还可以建成唐代文献库、宋代文献库、明代文献库、清代文献库等断代文献库;或者巴蜀文献库、齐鲁文献库、湖广文献库、岭南文献库、江浙文献库、三秦文献库、域外文献库等地域文献库。这种以书为单位的“元古籍”能够自由组合,搭建各种大型专题数据库。
数据库排序主要有拼音字头排序、汉字笔画排序、时间排序三种方式,其中拼音字头排序和汉字笔画排序都相对容易,门槛较低;真正有难度、有意义的是按时间排序。像《汉语大字典》以及其他一些大型工具书,都会列引用书目表,表后有特别重要的附录,大多按时间排序。《汉语大字典》引书2,965种,第一种是《周易》,最后一种是1908年上海出版的《中国歌谣选》,基本上是按照成书年代进行排序的。
最后一个阶段是包装测试,即最终产品需要进行封装测试。数据库建设的目的在于使用,因此数据库的优劣取决于用户的使用情况,使用的人越多、使用者专业水平越高,该数据库建设的意义越大。
(三)应用篇:性灵出万象
数据库建成以后,具体能够做什么?以“元古籍”的功能为例,可以分为五大类:查有、查无、查源流、查关系、查字数,难度是逐步递增的。
第一,查有。“查有”是最简单的,查询书中是否有某事物,只需要输入关键词即可。但这也并非能够轻易实现,比如“与时俱进”一词,在《四库全书》中就查不到。此词最早出现在清代慈禧的侍女德龄所撰《清宫禁二年记》中,只有将这部书数字化并放入数据库中,才能查询到该词的出处,如果没有对其进行数字化处理,就无法查询到该词的源头。再如“玉东西”,原为酒杯名,后代指酒。通过“查有”,可知此词最早见于宋代文献,多次出现在宋诗中,如宋代苏颂《和陆农师侍郎三和前韵》“主人满酌玉东西,坐客无辞醉似泥”,再如宋代孔平仲《次韵和常父渡江寄经父》“想得蓬莱秋睡觉,暖寒方索玉东西”。唐诗中未见此词。
第二,查无。“查无”需要限定范围,设定查询范围,才能确认有无某字词。比如“了”这一字形,从先秦诸子到《史记》《汉书》,均无“了”字,但“了”字在《红楼梦》中却成为高频字。要得出先秦两汉文献中无“了”字的结论,需要先将先秦两汉的全部文献建成数据库,否则就无法确认结果。《史记》《汉书》合计用字量超6,000,但它们所使用的是带目字旁的繁体字“瞭”,简写的“了”字最早出现于《后汉书》中,三国时期之后才开始使用。而在先秦文献《尹文子》中检出“了”字,可佐证该书混入了三国时期之后的材料。还有一个例子是,《大学》《中庸》《论语》《孟子》四本书总字数约五六万字,其中却没有出现今天常用的“字”字,因此,有人戏称“《四书》无‘字’”。
第三,查源流。要实现该功能,需要将文献按时间顺序排列,而且文献的数量和准确度都要足够。比如,“风骨”是《文心雕龙》中的一个文艺理论概念,也是文学文本中的常用词,该词最早出现在《世说新语·轻诋》中,使用“国学宝典”数据库,能够看到“风骨”一词在历朝历代书籍中的源流情况。
第四,查关系。实现这一个功能难度更大,需要特殊文献、特殊架构和软件的特殊功能。比如,要在一首七言(或五言)四句诗中查“柳绿花红”一词,每句中分别有一个字,并按照成语顺序出现,这就需要“专题数据库”才能实现。现在也许人工智能可以实现这一功能,但本质上还是需要古籍元数据作基础。
第五,查数字。一部(类)书精准的用字量和字(词)频统计,是数据库各项功能中难度非常大的一件事,不仅要求文字精准,还需要有严谨的体例和规范的字形。我们目前正与清华大学的数字人文团队合作,编制常用古籍字频表。比如,统计发现《论语》中“子”字出现972次,这个次数必须是精准的。它需要把文献差错率控制在十万分之一以内的量级,因此难度特别大,必须要在底本可靠且文字规范的情况下才能实现。
“国学宝典”作为一个超大型古籍数据库,犹如一艘巨型航空母舰,其建设绝非单纯的文本录入和网页存贮,而是一个复杂精密的系统工程,涉及文字处理、标引规范、分类体系、目录索引、语义分析等方方面面的问题,需要运用很多古籍数字化专有技术才能解决。而超大型数据库对于学术研究的助益,也远超一般中小型数据库。超大规模数据库的建设与应用,将深刻改变传统学术的研究方法和方向,从而掀起一场学术研究的技术革命。
“国学宝典”下一步将在互动纠错平台、图文仿真对照、多版本异文比对、虚拟影像交互显示、知识总库和知识图谱、语音检索等方面继续探索。我们将以积极开放的态度,加强与相关研究机构的合作,加大元数据交换流通,避免低水平循环,实现各种古籍资源共享、互惠共赢,以推动数字人文的纵深发展。
李海燕(中国中医科学院中医药信息研究所):中医药古籍数字资源库介绍
中国中医科学院中医药信息研究所/图书馆(以下简称“研究所”)是从事中医药信息研究与教学的部属综合性科研院所,是信息研究所与图书馆所馆合一的独立法人单位,主要从事中医药领域古今文献的收集、整理、数字化与知识服务,致力于中医药信息学的学科建设,研究方向包括文献资源建设、信息标准与知识组织研究、情报分析评价、科学数据研究和智能化的集成应用研究。研究所拥有古籍5,589种、10万余册,历代版本6,556个,大约占存世中医古籍种类的50%,是全国中医行业古籍保护中心和国家级古籍修复中心。
研究所对不同时期国内图书馆收藏的中医古籍进行了系统调研,于1961年出版了《中医图书联合目录》,1991年出版了《全国中医图书联合目录》,2007年出版了《中国中医古籍总目》,目前正在对《总目》进行修订,第二版《中国中医古籍总目》即将出版。此外,通过正在实施的“中华医藏工程”,也即将开展海外的中医古籍资源调研,形成《中华医药古籍总目》。
依据以上调研成果,研究所建立了“中医古籍书目数据检索平台”,目前该平台包含了“全国中医古籍书目数据库”“中国近代中医图书联合目录”“中医近代期刊联合目录”“中医院藏古医籍书目数据库”。其中,“全国中医古籍书目数据库”主要是对国内200余家公共图书馆和专业图书馆收藏的中医古籍(1911年及以前)的书目信息的展示,“中国近代中医图书联合目录”主要收录的是国内180余家公共图书馆和专业图书馆收藏的近代(1911—1949年)中医图书目录信息。通过该检索平台,能够检索到不同成书年代的中医图书情况及其收藏单位、版本等信息。
另外,研究所还建立了一个专业的中医药古籍数据库——“国医典藏”,共收录先秦至清末民国的历代典籍1,500种,分为“馆藏精品库”(1,100种)和“子部医家库”(400种)两个专题。“馆藏精品库”书目按《中国中医古籍总目》分类法分类,涉及全部12大类中医古籍,收录内容精良,不乏世所罕见的珍善本及孤本医籍。数据库收录了古籍的原版及彩色扫描图像,能够原汁原味地展现中医古籍的内容,同时研究所也对这些内容进行了深度的人工标引,并建立了专业化的后控词表,以便于对古籍内容的检索。
相比于其他学科领域,中医古籍最突出的特点是具有很强的现实价值。屠呦呦研究员在研发青蒿素之时,阅读大量历代中医典籍,带给屠老师灵感的《肘后备急方》,即为中国中医科学院图书馆所藏古籍。当初屠老师在对包括青蒿在内的100多种中药进行了以水煎煮的实验,但是提取物对疟原虫的抑制率最高只能达到40%左右。《肘后备急方》记载:“青蒿一握,以水二升渍,绞取汁,尽服之。”屠老师从中获得了灵感,“绞取汁”而非水煮的做法使她意识到,温度可能是影响抗疟中草药成分提取的关键。后来的实验结果证明,使用乙醚低温萃取青蒿素,保留下来中性的成分,抗疟的效果能够达到最佳。
此外,数据库还收录了很多具有文化意义和欣赏价值的古籍。比如,明彩绘绢本《本草图谱》出自一位女性之手,这在古籍史上是极为罕见的。此绢本工笔绘制,色彩鲜艳,线条柔和,具有很高的文化价值。“国医典藏”还收录了现藏于中国中医科学院图书馆的孤本《补遗雷公炮制便览》。这本古籍在本草界和美术界都具有重要意义,它作为中国古代本草图谱,涵盖了药物的形态图、采集图和炮制图,共有1,128幅精美的彩色药草图和219幅中药炮制图,对中医的炮制乃至古代绘画的研究都具有重要的学术价值。另外,“国医典藏”还收录了明万历时期金陵胡成龙刊刻的《本草纲目》。这是《本草纲目》的原始版本,也是迄今为止唯一一个由李氏家族自己编印的版本。《本草纲目》在2011年入选了联合国教科文组织的世界记忆名录。因此,今年研究所尝试从文化传播角度去开发《本草纲目》数字藏品,将《本草纲目》中艾草的图片进行IP授权,作为中医药领域的首个数字藏品发布,当时一共发布了9,999份,但预约人数达到了22万余。因此,就中医药古籍对中医药文化的传播而言,这是很好的探索与尝试。
中医药古籍最重要的价值在于临床。“半日临证,半日读书”是中医人非常理想的一种境界。读书、出诊、思考、再读书,可以看到古籍对于临床医学仍具有极大的参考价值。利用数字化技术记录中医古籍中的方药和诊疗信息,并使其应用于现代的临床诊疗,能够最大限度地发挥古籍的临床价值。研究所研发了“古今医案云平台”[4],目前主要面向十几所中医药高校以及部分中医医院和科研院所的研究人员等,用于专业的医案管理和数据挖掘及研究。该平台收录了余万条中医古今医案,医案库实时更新,包括“古代医案库”“现代医案库”“名医医案库”和“共享医案库”,支持名医、方剂的关联检索。此外,医案库中还有“专病医案库”专栏并提供专题服务。在医案录入时,医生可选择手工或语音进行录入,也可以通过OCR直接识别导入。平台中嵌入了关联分析、层次聚类等20多种丰富的算法,便于学生分析名医的学术思想,促进中医传承。该医案库目前有着较好的应用效果,能够对病证、方药、穴位、治法、疗效等数据进行关联和挖掘分析。
出于实现古籍的文本结构化、知识体系化、利用智能化目标的需要,研究所还建立了一系列的中医古籍专题知识库,包括“医案知识库”“养生知识库”“温病古籍知识库”“本草知识库”“方剂知识库”等。
以“温病古籍知识库”为例,该知识库当前收录温病古籍70余种,基于温病类中医古籍,分析温病的病证、诊疗、用药规律,展示温病古籍全文检索和段落阅读、热点温病知识图谱及温病相关知识的关联分析和网络分析拓扑图。另外,“温病古籍知识库”还能够基于温病古籍知识本体和语义关联,在知识术语层面进行温病知识的检索与语义网络的展示,检索结果将呈现检索内容的知识本体、语义关联关系和可视化展示、原文出处、频次统计图等内容。例如,以“春温”为关键词进行知识检索,可以检索到“春温”的疾病知识、病因病机、症状体征、治法、方剂、中药、医籍以及所涉及的古代医家等,检索结果会将其进行关联展示。此外,还有频次统计图展示检索词在书籍中出现的次数汇总,以数据统计图的形式更加直观地反映“春温”在古籍中的记载情况。尽管目前频次统计可能还没有达到一个非常精准的高度,但对于科研人员了解相关古籍情况仍可起到一定的参考作用。知识库系统中还建立了关联分析和复杂网络两个子模块,对相关信息进行挖掘分析,依据两个关键词在同一段落共同出现的次数以及置信度,分析关键词之间的关联程度。
研究所还建立了“中国历代医家传记知识库”[5],该知识库收录了历代史志、典籍中记载的一万余位古代医家的传记资料,基于医家的籍贯生平、学术特点、代表著作等结构化数据构建历代医家知识图谱,利用数字人文方法分析与可视化展示医家学术传承与社会网络关系,结合地理信息系统(GIS)分析医学地域流派时空衍变,为医家学术研究提供数字人文工具。
此外,研究所还开发了“中医古籍养生知识库”[6],该知识库收录了精选的历代中医养生经典古籍百余种,基于养生古籍的原文图像、结构化文本和专业的养生知识概念词表,能够实现中医养生古籍的图文阅览和知识检索,并根据养生知识分类和语义关联,实现养生知识的深度挖掘与可视化展示。
这些知识库之所以能够实现强大的知识关联检索功能,得益于中医知识组织系统(KOS)的支撑,包括中医古籍后控词表系统、中医药学主题词表系统、中医临床术语系统、中医药学语言系统四大系统。
中医古籍后控词表系统主要针对古籍中的一些术语,给出其类号、标引词、同义词、近义词、上位词、下位词、关联词与现代医学对照词。比如,古代的“消渴”与现代医学中的糖尿病就能够做一些关联对照。
1980年代起,《中国中医药学主题词表》[7]就已经在建,目前该词表已经完全成为网络词表,实时更新,其架构与美国国家医学图书馆的《医学主题词表》相对应,建立起了中医药的树状结构分类,收录了主题词8,479条、入口词13,000条。万方医学、中国知网(CNKI)、中国生物医学文献服务系统(SinoMed)以及中国中医药文献检索系统等,都将《中国中医药学主题词表》作为标引和检索中医药文献的依据,GB/T 40670-2021《中医药学主题词表编制规则》已在2021年作为国家标准发布了。
第三个重要的术语系统是“中医临床术语系统”[8]。该系统主要针对中医临床的概念和术语,与英国“医学系统命名法——临床术语”(SNOMED CT)的构建方式一致且兼容,目前收录相关概念45,368个、术语11,9491个、概念间关联关系233,706条。“中医临床术语系统”支持临床电子病历规范化录入及分析,支持临床信息结构化存储、共享和利用,支持已有临床数据的清洗和规范化、数据分析与临床用药经验挖掘,支持临床文献的语义标引,支持中医药文献检索与关联检索,为临床诊疗知识库、知识图谱构建提供术语参照基础。ISO 19465:2017《中医临床术语系统分类结构》已于2017年作为国际标准由国际标准化组织(ISO)发布。
第四大术语系统是研究所开发的“中医药学语言系统”[9],其底层支撑的语义网络架构包括语义类型98种、语义关系58种,《中医药学语言系统语义网络框架》(ISO/TS 17938:2014)国际标准于2014年由ISO发布,于2019年成为我国国家标准。该系统与美国国立医学图书馆的“一体化医学语言系统”(UMLS)的构建方式是一致的,集成了21个中医学领域的词表。概念(Concept)的同义词或相关词称为术语(Term),当前本系统中有概念106,188个、术语273,594个,主要用于中医药数据规范、知识库构建、医药知识的语义关联检索,中医药知识体系的构建以及中医药知识图谱的展现。
最后,期待能够与其他领域的数字人文研究加强交流、通力合作,利用研究所丰富的数据资源和知识库系统,结合最新的人工智能技术,让中医古籍“活”起来,在临床诊疗、文献教学、科研攻关和文化传播中发挥出更好的作用。
释贤度(北京如是人工智能技术研究院):佛教大藏经数字化资源的介绍
(一)佛教大藏经数字化的历史与现状
佛教徒对大藏经的保护与传承有一种使命感,并且佛教的教理也会赋予佛教徒开放的心胸,勤于学习、勇于创新、开拓进取,因此,佛教徒中的有识之士会对先进技术有一种特别的敏锐,利用先进的技术来保护与传承大藏经,这几乎是每个时代佛教徒的共识。
回溯历史,雕版印刷术的产生和发展就与佛教的经典传播存在密切关联。潘猛补在《论佛教对雕版印刷术的影响》中指出:“7世纪前期的佛像雕印是雕版印刷术的起源,9世纪的佛经印刷是雕版印刷术开始成熟的标志。”[10]美国学者富路特的《关于一件新发现的最早印刷品的初步报告》也提出:“中国是最早开始发明印刷术的国家,印刷术是从它那里传播到四面八方的,而佛教是主要传播媒介之一。”[11]目前世界上已知最早的雕版印刷物是来自敦煌的《金刚经》,制作于公元868年。当时雕版印刷还未发展成体系,但已经能够为佛教徒所用,可见佛教有着重视利用先进技术来保存和传承文献的传统。在当今互联网时代,佛教界在尝试使用数字化技术手段服务大藏经的保护和研究。
1991年,在欧洲,Tim Berners-Lee发明了万维网,开启了web1.0的时代,互联网在web的加持下大行其道。1993年,在美国,伯克利大学兰卡斯特教授发起并成立了一个推进全世界各国佛典电子化的国际性组织——电子佛典推进协会(EBTI)。
1993年,在韩国,在EBTI的推动下,韩国海印寺一项规模宏大的工程——《高丽藏》全文数字化项目启动了。《高丽藏》是韩国国宝,也是联合国教科文组织认定的世界遗产。项目的主管是海印寺的宗林法师,工程得到了韩国三星公司在资金、人员及设备方面的大力支持。他们在汉字编码、输入法及缺字处理等方面做了大量创新工作,终于在2000年5月完成了《高丽藏》全文数字化工程,历时7年多。数字化成果以“高丽大藏经研究所”的名义,通过光碟和网站发布于世。可惜的是,高丽大藏经研究所后来因故停运,网站无法访问,围绕《高丽藏》数字化的研究和应用也就无法再深入开展了。
1994年,在日本,东京大学江岛惠教教授领导成立了“大藏经数据库研究会”(SAT),目标是将85册《大正藏》数字化。项目得到了日本政府3亿日元的资金支持,并于1998年首先将4册600卷《大般若经》完成数字化。之后,该项目由于经费不足而暂停。1998年,“中华电子佛典协会”(CBETA,下文详谈)的惠敏法师带领团队前往日本沟通《大正藏》数字化版权问题,并与SAT讨论了未来的合作方式。由于SAT认可CBETA在数字化方面的效率,但正面临资金不足的困难,因此双方口头约定:CBETA的工作以第1—55册与第85册为主,SAT则以与日本佛教相关的第56—84册为主,如此可以避免工作的重复和资源的浪费。1998年,SAT开始向日本全国佛教界募款。1999年,江岛惠教教授过世后,募款工作由2000年成立的“大藏经数据库支援募金会”接手并继续。2007年,85册《大正藏》的数字化工作最终得以完成。
1998年,在中国台湾,“中华电子佛典协会”(CBETA)在台北法鼓山成立,中华佛学研究所的副所长惠敏法师任主任委员,该所网络信息室主任杜正民任总干事,恒清法师任常委。自此,《大正藏》数字化工程全面启动。CBETA的《大正藏》数字化事业得到了大陆和台湾以及日本、美国佛教界同行的广泛协助,进展神速,到2002年5月,完成了第1—55册及第85册的光盘制作,并在网上提供免费下载,CBETA实现了第一阶段的工作目标。2003—2008年,CBETA完成了《卍续藏》数字化,实现了第二阶段的目标。2009年开始,CBETA陆续开展《嘉兴藏》《历代藏经补辑》《国图善本佛典》及《汉译南传大藏经》(元亨寺版)等数字化项目,以补充《大正藏》之未收。
下面以CBETA为例,从软件功能、数据内容、专题知识库三项特色介绍佛教大藏经数字化资源库的一些基本情况。
在软件功能方面,根据CBETA官网推荐,CBETA提供三种访问方式:“CBETA电子佛典集成”软件(CBETA Online)、在线阅读网站[12]、由热心居士开发的deerpark网站和手机app,[13]具备检索、阅读与研究功能。CBETA数据库提供了佛教典籍的多种分类方式以便于浏览,支持按照藏经类别、经名、作译者等进行字段检索和输入关键字进行全文检索,上线了原书换行(按原书排版方式显示)、现代标点分段、图像关联等阅读功能,以及学术引用、字典关联查询、词汇分布统计和文献关联查询等研究功能。
在数据内容方面,最为关键的问题是集外字。古籍校对时,常会遇到计算机字符集中没有的文字,即所谓的“集外字”(也叫“缺字”),给古籍校对带来很大的困扰。为最大程度还原古籍,在校对时应尽可能选用与古籍中的字形一致的计算机文字进行校对,这是古籍校对中的保真原则。《大正藏》第1册到第85册,全部字数约一亿多,而在目前已经完成的56册经文中,电脑缺字部分就有15,000字左右(不包括悉昙字)。在校对时,CBETA采用“组字式”的方法来解决录入的问题。
所谓“组字式”,是指在遇到计算机字符集中没有的字,无法直接输入时,采用多个文字组合描述的方式进行表达。这种直接而巧妙的表达方式解决了数万个集外字问题。随着Unicode的发展,当某个字进入Unicode字符集之后,它的组合式能够被替换为Unicode字型,因此这个工作成果实际上是有生命力的,且在不断生长。目前,CBETA数据库中的部分集外字有图片式、组字式、Unicode字型和通用规范字等多种显示方式,Unicode字符集中仍未收录的文字则使用图像和“组字式”来呈现,或者用通用规范字去代替原来的异体字。
CBE TA在完成《大正藏》和《卍续藏》的数字化后,着手开展《嘉兴藏》的数字化项目时,遇到了非常突出的异体字问题:“《大正藏》《卍字续藏》是现代铅版印刷,字型固定;《嘉兴藏》是古代木刻版印刷,许多异体字型。若要一一照实记录,‘缺字’问题会造成严重的作业瓶颈,所以我们必须订出用字规范,以克服异体缺字问题。”[14]因此,《嘉兴藏》的异体字是被转换为对应的正字来进行处理的。
另外,CBETA在校对时保留了古籍中的校勘记等注释,并在数据库中以弹框的形式予以显示;对于古籍中的图像,则是进行截图、编号,然后在软件界面中以图像方式呈现。为了让古籍更好地融入现代社会,CBETA于2004年开始启动“新式标点专案”,持续投入资金和人力对佛典古籍进行现代标点,至今仍在继续,可喜的是他们于2021年开始尝试利用人工智能标点加以辅助。
CBETA数据库的特色之三是基于CBETA全文库而整理的多种专题知识库,并为专题知识库设置了多个不同的平台。[15]比如,面向学者学术研究需求的“CBETA数位研究平台”,提供了整合经典阅读、深度资料搜寻、数位量化分析等三大操作功能。专题知识库主要有“唯识典籍数位资料库”“《瑜伽师地论》资料库”“满文藏经研究”“新修《华严经》疏钞”“别译《阿含经》版本对比研究”等。
以“《成唯识论》及其注疏编撰”专题知识库[16]为例,《成唯识论》是唯识理论非常重要的一部论典,由唐代高僧玄奘法师糅合印度十大论师的诠释编译而成,唯识宗的开山祖师窥基大师为它作了非常重要的注释。古代论书在流传过程中,除了原文以外,还会源源不断地有注解疏释补充进来,在学习和研读时需要将原书论文与注释疏文进行对照。“《成唯识论》及其注疏编撰”专题知识库整合了《成唯识论》的述记、枢要、了义灯、演秘,这些论述之间相互解释、同屏呈现,很好地满足了文本对读的需要,非常便于学习和研究。
(二)如是研究院大藏经数字化相关工作
北京如是人工智能技术研究院(以下简称“如是研究院”)成立于2019年4月,是北京市民政局批准的科技类民办非企业单位。如是研究院以“数字古籍,传承经典”为宗旨,致力于应用先进的人工智能和信息技术,推动古籍数字化的技术进步和推广应用。2020年4月,如是研究院发起“如是古籍之大藏经数字化工程”,旨在利用先进的人工智能技术深度加工、整理汉文佛教大藏经。
如是研究院的阶段成果之一是“如是古籍数字化生产平台”,主要用于古籍的校对工作,平台页面设有“任务大厅”栏目供校对者申领校对任务,其下有切分校对、切分抽查、单页校对、单页审定、单页抽查、聚类校对、提交抽查、修改抽查等任务步骤。在利用人工智能OCR扫描原书后,首先对原书图像中的每一个字进行图片切分,切分之后形成字图数据库,然后把相同字形汇聚在一起进行聚类,得到原书文本的所有字种,再进入到每一个具体的字进行校对。聚类校对能够提高效率、提升校对质量,相同的字形互相佐证,避免了“一形多校”的问题,如果因体例完善而需要修订,则可以批量修改,保证内在的一致性。在进行聚类校对时,如遇到字符集中没有收录的字形而无法输入时,校对员可直接选中字图进行造字,后台会自动分配一个编码(字形、编码是计算机文字的两个核心要素),然后就可以在平台上方便地使用了。由于造字过程非常简单、轻松,无需字体和输入法的配套,我们称之为“轻造字”。这些校对方法都是为了尽量地遵循古籍整理的“保真原则”。经过校对的文字有图片、编码、正字三种显示方式,不同的显示方式之间可以一键切换。以上人工智能OCR、切分校对、聚类校对、轻造字等方案,可以很大程度上提高古籍数字化的效率和质量,是我们主要的技术特色。
在内容特色方面,以《径山藏》为例,首先,我们按照原字校对的原则进行校对得到原字文本,校对过程中的新造字,实际就是《径山藏》的异体字,我们会整理这些异体字的正字和通字,基于原字文本和异体字的正字、通字转换表,就可以得到正字文本和通字文本。其次,基于切分校对的单字坐标信息,可以实现字符级的图文关联,和字符级的图文对照显示。再次,将字图切分出来,可以形成字图数据库。
文字校对体例也是我们在进行古籍数字化时的一个特色。我们认为,古籍数字化文字处理的根本问题就是认同问题和异体字规范化的问题。认同问题就是“判断两个字形是不是同一个字”,这是古籍数字化最核心的问题之一,如果是同一个字就直接校对,如果是不同的字,按原字校对就要造字,按正字校对,则可以用正字法校对为规范正字。针对认同问题,在文字校对体例中,我们提供了一套认同判断的过程与方法,经实践证明行之有效。异体字规范化的问题比较复杂,需要专业知识,而且目前学界并没有特别统一的规范和标准。我们采用原字校对的原则,一线校对员无需处理异体字规范化问题,而是将异体字集中起来处理,这也是我们采用原字校对的原因之一。
与CBETA相比,如是研究院的数字化工作在内容和技术上均有所不同。在内容方面,首先是收录范围不同,CBETA以《大正藏》《卍续藏》为主,同时逐步收录其它藏经中这两部藏经未收录的典籍,如是研究院则尽可能搜集能利用的所有藏经;其次是校对原则不同,对于异体字,CBETA采用的是正字法来进行校对,如是研究院采用的是原字校对,若字库中没有相同字形的文字就自行造字;此外,校对成果也不同,除文字本身外,如是研究院还提供文字的坐标、字图以及相应的字图数据库,以及该部藏经的异体字字库。技术上,如是研究院采用的是人工智能OCR、聚类校对与互联网众包协作的模式。
就大藏经数字化的未来工作而言,基础工作是提供准确的文本,提升工作是开发丰富的应用。
古人在校对时常常发出这样的感慨:“校书如扫落叶,旋扫旋生。”就是说在古籍校勘过程中,解决了旧问题的同时常会引入新问题。如何保证古籍在传承过程中不失真?这是古籍数字化过程中非常基础、非常关键的问题。从文本加工的角度来看,古籍数字化包括校对、校勘两个环节。校对就是用计算机文字转录古籍文字,保证校样与原稿的一致。校勘指针对同一典籍不同版本进行比对、勘误,是古典文献学三大科目(目录学、版本学、校勘学)之一。我们将一书的多个版本校对后,形成数字文本,然后交由计算机自动比对,便可得到异文(即校勘记),而计算机比对得到异文的过程,只要算法设计完善,是很难有疏漏的,能够有效避免“旋扫旋生”的问题。目前的大藏经数字化工作主要还是在校对方面。希望今后能采用数字化的方式来做佛典校勘,通过校勘将所有藏经整合成为一个有机、立体的整体,从多个面向提供服务。从文本质量的角度来看,经过精审校对、校勘工作,可以提供准确的文本;从版本学、语言学的角度出发,可研究不同版本文字内容的变迁;从文字学的角度,基于字图数据库,可展开文字字形变迁、异体字字形等相关研究。
有了准确的文本,利用大数据、人工智能、知识图谱、自然语言理解等先进技术,进而可以开发丰富的应用,这是一种趋势和展望。目前也有很多古籍数字化团队(如CBETA)在做这方面的工作。
最后,介绍一下如是研究院对外提供服务的两个平台。
第一个是“如是古籍数字化工具平台”。[17]它是由如是研究院的技术积累打包而成的工具平台,主要有四个板块的功能:如是OCR、智能标点、标点迁移、多文本比对。多文本比对主要服务于古籍的多版本校勘,比对多个版本的之间的文本差异,并自动生成校勘记。
第二个是“如是古籍字典”。[18]它收录了4部字典,分别是《汉语大字典》《敦煌俗字典》《异体字字典》和《高丽大藏经异体字字典》。平台的功能之一是部件笔画检字法。“国学大师”等很多网站都提供部件检字法,但本平台有所不同的是,除了部件外,针对不易输入的部件可以用笔画进行查询,比如输入包含“日月”两个部件和除此部件外笔画数是“3—4”的组合条件,可以检索到符合要求的字,点击检索结果中的某个字,可以打开《汉语大字典》等字典,进入此字的详情页面,这是将检字法与字典打通关联的成果。平台的功能之二是异体字的检索。输入并搜索某字,能够检索到这个字在《异体字字典》《高丽大藏经异体字字典》中的异体字情况,再点击此字,则会跳转到字典的相应页面,可以查看它在字典中的详细解释。
整理者:邓丽君/清华大学中文系
(编辑:王波)
注释:
[1]T.Talhelm et al., “Large-Scale Psychological Differences Within China Explained by Rice Versus Wheat Agriculture,” Science, vol. 344, no. 6184, May 2014, pp.603-608.
[2]徐晨飞、包平:《基于方志物产知识库的数字人文研究框架设计与实证研究》,《中国科技史杂志》2022年第2期。
[3]《习近平在中共中央政治局第三十九次集体学习时强调把中国文明历史研究引向深入推动增强历史自觉坚定文化自信》,《人民日报》2022年5月29日。
[4]古今医案云平台,访问网址:http://www.yiankb.com。
[5]中国历代医家传记知识库,访问网址:http://www.gjkb.ac.cn:8080/frontend/yijiaLogin.html。
[6]中医古籍养生知识库,访问网址:http://ysh.gjkb.ac.cn:8088/kmweb/home。
[7]访问网址:http://www.tcmesh.cintcm.com/。
[8]中医临床术语系统,访问网址:http://www.tcmcts.cintcm.com/。
[9]中医药学语言系统,访问网址:http://tcmls.ac.cn/。
[10]潘猛补:《论佛教对雕版印刷术的影响》,《法音》1982年第6期。
[11]富路特:《关于一件新发现的最早印刷品的初步报告》,《书林》1980年3期。
[12]CBETA线上阅读,访问地址:https://cbetaonline.cn。
[13]汉文大藏经,访问地址:https://deerpark.app。
[14]释惠敏:《中华电子佛典协会(CBETA)简史》,http://cbeta.org/node/4944,2022年9月1日。
[15]相关介绍,请见:https://lic.dila.edu.tw/digital_archives_projects#/tab1/cbeta。
[16]《成唯识论》及其注疏编纂,访问网址:https://vms.dila.edu.tw/。
[17]如是古籍数字化工具平台,访问网址:https://guji.rushi-ai.net:800。
[18]如是古籍字典,访问网址:https://dict.rushi-ai.net。