


皮特·布劳德韦尔 / 美国斯坦福大学交叉研究中心
陈 威 / 美国弗吉尼亚大学
大卫·谢帕德 / 美国加利福尼亚大学洛杉矶分校学术创新实验室
曹瀛月(译)/ 北京大学中国语言文学系
摘 要:文章处理的问题关涉到文学史数据的全面性和选择性,并不希求解决文学史叙述不可能性的问题,只希望从计算机视角出发重新阐释这些问题。我们的工作对象是《全唐诗》,它是有清全盛时期编定的唐诗总集,体量庞大、收诗完备。《全唐诗》收录的海量诗歌已经超越了人类所能进行的文本细读的限度。为了从整体上理解这部文献,我们采用了两种远读方法——主题模型与散度度量。这两种方法使我们得以重审上述文学史问题,并为唐诗阅读提供一种新的视角。
关键词:《全唐诗》 文学史 主题模型 散度度量
文学史书写或许是一种不可能的尝试。即使越过何为文学这个大问题,我们也还会面对其他的问题:一种历史叙述框架如何能够有效、全面地表现一种既有的文学传统?这个问题在很多方面都与数据建模关系匪浅,它更关注如何将大量的文学数据整合为一种全面的叙述。[1]也就是说,即使目光仅集中于某一特定文学传统中的某一特定类型(genre),比如,唐代(618—907)的诗歌,仍然有太多作品需要进入视野,形成连贯的文学史叙述所要整合的文学作品仍然太多。而明确去取标准的缺位,以及对入选部分能否如实反映数据整体面貌的疑惑又使这一问题更加复杂。最终的结果就是,只要不是特别要求扩大经典的范围,或者不是为了提振之前被忽略的某一支传统,文学史仍然倾向于重复使用同一批小型样本,也就是那些高度经典化的作品和作家。
本文主要从数据全面性以及选择性的角度出发审视这一文学史问题,意在从计算机视角出发对此问题做出阐释,而并不希求解决文学史叙述本身不可能性的问题。我们的研究对象是《全唐诗》。《全唐诗》编定于1705年,彼时正值清代鼎盛时期。这是一部奉旨集体编纂的求全求备的大型唐诗总集。历经各朝各代,唐诗早已成为诗歌创作的标准,因此《全唐诗》可以说是约800年间文学经典化集大成的产物。《全唐诗》是现存唐代诗歌的主要来源,更重要的是,它还以繁复、多向度的分类模式建构了一种关于唐诗发展的文学史视角(详见下文)。不过,《全唐诗》所收的唐诗总量——50,000多首诗歌及残句等——远远超过了人类读者进行文本细读的限度。但是,如果不能完整地阅读《全唐诗》,也就无从对唐代诗歌的面貌有完整的理解,更不用说形成一种既能充分利用唐诗材料,又仍然保持简明清晰的历史叙述了。为此,我们需要另一种方式来实现更大规模的阅读,这是一种被称为“远读”的方式,[2]但将之称为机器阅读或计算机批评则更为确切。
有两点需要注意。首先,关于远读与文本细读二者的关系问题。远读与文本细读之间通常是二选一的关系,Andrew Piper对这种二选一的审慎反驳是我们始终需要铭记于心的。他写道:
我希望我们注意到,在建构一种在特定范围内发生作用的文学观念时,不要在这两极之间游移是何等不可能的事情(尽管这种游移何时发生仍不可确知)。我尤其希望我们看到定性分析与定量分析相结合的必要性,正如我所要尝试着呈现的,这种结合有基本的循环性,因而具有本质的阐释力。[3]
尽管在机器与人类对文本的理解之间调和折中意义何在仍旧成为问题,机器视角的介入如何影响人类对阐释学的理解也仍旧存疑,但我们仍完全认同兼顾远读与文本细读的阅读方式能够让我们在两种规模不同的阅读方式之间形成阐释的循环。其次,有关东亚文献的远读方法研究仍有待完善,这不单是因为诸如字符编码、标记之类的技术层面问题,同样也因为掌握东亚语言和文学传统的难度更大。近几年确实有人将主题模型方法与文言文献结合起来,[4]他们关注的是早期思想中的一些特定话题。尽管将主题模型方法应用于规模更大的汉语文献能够得出更具普泛性的初步结论,但这项工作仍然任重道远,而且文本选择、准备方面也仍存在基本问题。[5]运用计算方法研究东亚文学史也已产生了一些成果,研究的是与标量阅读相关的体裁与风格问题,[6]也有学者在唐诗领域沿着相似路径展开了更为具体的研究。[7]
在进入对《全唐诗》的概述之前,本文首先讨论的是文学史,文学史向我们提出了数据选择与数据完整性的问题。为了从整体上了解《全唐诗》这部文献,我们接下来将用到两种相互联系的远读方式——主题模型(topic modeling)与散度度量(divergence measures),展示这两种方式是如何让我们重提与重审这些文学史问题,并且获得了文学史实践的新视角。
一、当我们书写文学史的时候,我们在做什么?
文学史作为文学研究的一个分支,目前正处在一个模棱两可的位置。虽然新的文学史书写源源不断,但机构化、制度化的文学史训练却在衰退。我们可以从多个角度来界定文学史书写的目的,包括一种或几种文体的产生和发展、一种国家或民族文学的兴盛或者是某种历史、文化语境之下的文学写作情况。但是,无论文学史是如何被定义的,它都会在一系列因素的作用下而变得复杂:批评家的个性和历史叙述方式会制约哪些作家、作品可以入选,以及作家、作品去取中蕴含着什么深意,更不消说引入历史语境之后还将面临更大的问题。戴维·珀金斯在其颇具影响力的《文学史是可能的吗?》中写道:
无论文学史家还有什么额外的追求,他们首先都要将历史呈现出来,并对之进行阐释。呈现历史是要告诉读者文学过去的样貌,阐释则要求说明原因——为什么文学作品呈现出现在的特征?为什么文学会如此发展?……当然文学史家和理论家也都明白,这种呈现与阐释并不会尽善尽美。历史学家就算知道所有相关的事件和答案,他也不能将之尽数塞进一本书里。唯一完整的文学史只有过去本身,但过去本身并不具备演绎和解释的属性,因此它并不能成为一种历史书写。[8]
接下来,珀金斯追问道“多大程度的不完整是可以接受的”;另外,他还关注到“历史必须从特定视角出发”——批评家视角终究是受限的——这一事实如何影响了文学史叙述中的阐释性论断。[9]这些问题存在于所有历史叙述的基底当中,因为叙述性历史论断的本质就关涉着简化,这种简化是以追求代表性的方式发生的。也就是说,一些确定的数据被选择出来充当整体的代表,这些选择又总是受价值判断影响、被批评视角干预。
就数据选择而言,选择行为本身需要有可资举证的标准,但是在文学史书写当中,去取标准的确定过程却并不总是清晰可见。数据并非不可知,因为被选择的数据本身已经是价值判断的呈现。[10]韦勒克和沃伦几十年前就注意到了这一点:
在文学史中,并没有哪些数据是完全中性的“事实”。材料选择中就已经暗含着价值判断:在一般书籍与文学作品的初步区分当中,在哪位作家应该获得多少篇幅的简单篇幅分配中。即使我们保证有一些事实信息,比如日期、题目、传记事件等,是相对中性的,我们能保证的也只是文学编年的可能性。而任何问题,哪怕是文本批评或者渊源、影响方面的问题要想有所推进,都需要一直做出价值判断。[11]
无论韦勒克、沃伦还是珀金斯,他们都不否定历史叙述的简化属性,因为文学史就像地图,它为我们提供的是有引导性的定点,由此出发,我们去探索实际上无边无际的文学数据的疆界。其实,我们还可以走得更远:文学史告诉我们要去读什么,什么可以算做文学——简单来说就是划出文学与其他广大漫漶的文本之间的边界。如果文学史这张地图还要继续发挥作用的话,那么它就不能,而且不应该是文学史研究的全部疆域。也就是说,文学史写作中最初的材料选择如何完成仍旧成为问题。在历史叙述中给一位作家辟出位置就意味着其他作家需要被忽略或者只能简要提及;有时候叙述的线性要求使一些数据被排除在外,或者只能谈其大略,这就使得最终呈现出的数据可能就在圆融通畅的文学史叙述中被模糊掉了。[12]
数据缺失一方面出现在历史叙述的写作过程中,另一方面则体现在阅读史中。Margaret Cohen谈到了“未被阅读的大多数”(Great Unread),它提示我们,因为读者的轻忽而流失的文学作品多到不可计数。[13]Franco Moretti将同样的观点表现得更有声色,他提出了“对文学的屠杀”以及“屠夫式读者”的观念。“屠夫式读者”概念指的是“读者只读小说A(而不读B、C、D、E、F、G、H……),A因此得以鲜活地进入下一位读者手中,依次类推所有读者都只读小说A,因此A得以经典化”。[14]Moretti的模型本身有一些问题:第一,它之所以能够有效重审那些所谓可以被质疑的经典,是因为它“对过去形态的假设建基于现在的情况”;[15]第二,它将每一部虚构小说都视为稳定而独立存在的实体。小说B、C、D并未被文学史选择的结果并不必然意味着它们之中的特质没有被后来者继承。而有相当一部分特征被承传下来的小说A,可能也与B、C、D等有相似之处。创作于同一时期的同类型小说也确实更容易呈现出相似的形态。就算Moretti的模型站不住脚,我们至少也可以说读者在文学史的选择过程中扮演着一定的角色,文学史做出选择的过程在很大程度上是失控而分散的,在一定程度上,单凭一个人的智能完全不能决定哪些文学作品会被经典化,而另一些就不会。
但是,尽管Moretti认为文学史的写作在很大程度上属于事后追认,用他自己的话来说,这就像盖章认定;分散的读者代表全部的读者,完成了文学史写作的实际工作。文学史书写并不只是阅读史的单纯反映,正如文学史学也并不能完全决定人们阅读的对象。文学史家站在漫长的历史选择流程的末段,承担着用历史书写将文本数据中代代相传的文学质素呈现出来的重任;但是,她也将批评家的干预引入了读者的阅读史,从而使批评家有可能与读者视角的历史协商对话。也就是说,文学史学既需要阐明从前并未厘清的经典化过程,也要结合读者认定的经典和尚未经典化的文本,有意识地作出更进一步的选择。
无论海量的文学材料来到我们手中之前怎样被精简过、整饬过,我们可能还是要将数据的流失视作一种恩赐,正如Ann Blair所说,不然要读的东西就太多了。[16]不过,随着文本数字化项目的到来以及与质量导向的阅读大异其趣的量化阅读方法的发展,我们大概也可以开始探索作为整体的文学史(某一文学类型、时代、作者,甚至是某一支文学传统)究竟是何模样了。我们知道,量化的方法不能取代质量导向的视角,质量导向的视角也不能仅被用来证明(或证否)基于定量方法的判断。而且,计算方法(computational methodologies)的影响尚且没有得到充分的评估,如何在多样化的视角之下审视个体的阅读也还没有进入文学研究和文化研究。从计算视角出发理解文学史需要认知方法论的=支撑,在这个方面,本文只是做出了初步的努力。
二、何为《全唐诗》?
为了探究上述文学史问题,我们将以《全唐诗》为分析对象。《全唐诗》编定于1705至1707年之间,是一部求全求备的唐诗总集,汇集了有唐(618—907)一代(几乎)所有的诗歌。它名义上的编者是著名官员、皇室亲信曹寅(1658—1712),以及由彭定求(1645—1719)领衔的一批学者。[17]尽管《全唐诗》的文本讹误、归属不当以及重收、漏收现象往往为人诟病,但《全唐诗》的编定保留了7到10世纪的几乎全部诗歌,使之免遭流散之苦,仍不失为一项卓绝的学术活动。Matthew L. Jockers对英国文学进行微量分析的方法存在一些固有缺陷,也即与他宏大的目标相比,他面对的文本“不完整、有断裂、无秩序”,但是,因为《全唐诗》的大量文本是对传世唐诗的全面搜集,也是对唐诗历史地位的认定,所以Jockers面临的缺陷在《全唐诗》当中并不存在。[18]
《全唐诗》的结构本身就非同凡响,堪称当时那个时代的精妙制作。在《全唐诗》搭建出的复杂系统之中,大量的文学数据得以各归其位,有效地对文本进行检索也成为可能。《全唐诗》凡900卷,收诗49,403首,另有1,055组联句及残句等。[19]《全唐诗》的编纂工作基于先前完成的两部唐诗总集,其一是明代学者胡震亨(1569—约1644)编撰的《唐音统签》;[20]其二是更早的一种《全唐诗》,其编纂始于明清易代之际的诗人钱谦益(1582—1664),成于季振宜(1630—?)之手,现称《全唐诗稿本》。[21]《全唐诗》大部分内容都依当时风尚编年排列,当然也有一些值得关注的例外。内容序次如表1。

表1
前九卷全都是唐王室的诗歌,第10卷至第29卷是仪轨相关的诗歌以及乐府诗(与汉代官署乐府相关,或用汉乐府旧题的诗歌)。[22]不过,这部总集的主体部分(卷30—731)仍旧大体依循所收诗人时代先后顺序编排。对于唐王朝的乱臣贼子,如宦官高力士(684—762)、起义的黄巢(?—884)(卷732—733),《全唐诗》则打破了时间脉络。但是,在这些人之后,我们会看到所收诗人的生平信息越来越少,先是一些无可系之年,却有名有姓,抑或行第、籍贯可知的诗人;接下来是一些姓名不传,但有一些其他指涉信息的诗人(如丽山游人);最后是一些无主名的诗(卷767—787)。这之后收录的是联句(多人合作完成的诗歌,参与联句的诗人轮流作出一句或一联诗)、没有其他诗作传世的诗人所留下的不完整的诗(句、联或是诗节)以及无主名的残章断句(卷788—796)。
除去皇室成员以及乱臣贼子的部分,这部选集在很大程度上依循着文学史的逻辑,即编排诗歌时,以基于诗人生平信息的时间顺序为优先原则,接下来编排缺少相关信息的诗歌,按照信息保留的完整程度降序排列。Pauline Yu在她对唐诗选集的研究中表示,总集与文学史之间的紧密联系十分值得关注。她指出,中国古代的文选“通常依时代先后排序。如果可以考知时代,某位诗人的别集会遵循时间顺序,而将更多作者排列在一起也同样采用这样的原则。”后面她还注意到,这种编排方式与日本的选集不同,“日本选集重视主题,这种重视相关性以及主题连续性的编排模式表明,它们明显并不遵照历史原则”。[23]后一种编选方式导源于类书,类书的编排通常依主题层级为序,从极大(天地)到极小(昆虫)。[24]从这个层面来讲,类书可以类比百科全书;尽管与西方的百科全书概念有显著的不同,但类书与百科全书都旨在充当文本信息的大全式汇编,在这一点上,二者是有相近之处的。[25]
从第797卷开始,我们看到了另外一种组织逻辑。从此往后,《全唐诗》背离了文学史的模式,而采用了另外一种编排思路,这种思路与日本选集的主题分类模式相似。这一部分(卷797—805)集中于女性诗人,从名媛、妓女到知名女性作家薛涛(?—832)、鱼玄机(约844—868)和李冶(?—784)。在这之后是佛、道二教的诗人(卷806—859),再之后是仙、神、鬼、怪诗(卷860—866)。最后几卷的内容更加庞杂,包括占辞、谚谜、谣、梦诗和题语。有可靠依据的话,这几卷内部也会按照先宫廷(帝王、后妃)、后时间顺序的模式编排。
《全唐诗》的编排顺序值得多说两句,是因为它结合了两种较早的文学选集编排方式:其一是主题导向的编排方式,这种编排方式与百科全书式的类书有关;其二是全面编年的编排方式,此法在明代文学选集中开始成为主流。两种编排方式都体现着批评家的智慧,这种文本编排方式使对特定文本的查阅和检索在理论上成为可能。但是,《全唐诗》的规模要远远超过一位个体读者能够有效把握的限度,这部集子的功能要更接近于一部档案或者数据库,而不是供读者进行细读。
人们可能会将《全唐诗》与其他体量较小的唐诗选集进行对比,体量较小的那些选集明显是供具体读者阅读之用的,比如稍晚一些的清代诗选《唐诗三百首》。《唐诗三百首》是孙洙(1711—?)所编,这部收诗约300首的选本格外流行,对于许多代人来说它都充当着基础的诗歌入门读本,直到今天还是如此。[26]在更大的文学史框架中来阐述这个问题,可以说作为一部唐诗文本,《全唐诗》从它的编集过程开始,就明确地受国家约束、承担着文化经典化的功能;而对于大多数读者来说,《唐诗三百首》(以及其他类似的选本)为阅读唐诗提供了方便,使读者更加熟悉唐诗,因此也最终塑造了读者对于唐诗的概念。在这个意义上,《唐诗三百首》充当的角色是带有初阶阅读训练性质的数据集合,它使人们获取文学史知识,在社会上建构起阅读唐诗的普遍经验,最终树立起文学鉴赏品味的轨范,在读者心中形成对唐诗的期待视野。
尽管唐代文学通史不会以《唐诗三百首》这样的基础选本为根底,但文学史通常也建基于其他有文化立场的数据集合,不管是更具学术性质的选本、带有批评性质的研究还是大学中的课程。如果现实情况不过如此,那么如果数据集合足够全面,或者至少更加坚实之后,唐诗的历史应该呈现出什么面貌呢?也就是说,阅读《全唐诗》会如何改变我们对唐诗的看法?可以确信的是,阅读《全唐诗》的行为以及任何基于《全唐诗》整体的批判性表达都自然会背离与传统文学史相关的通常叙述方式。确实,如果《全唐诗》的使用情境只是钩沉唐诗史的资源的话(在英语世界可以参看Stephen Owen对唐诗的分期研究,汉语世界则可参看许总《唐诗史》、杨世明《唐诗史》[27]),它便甚少能够拥有独立的地位。毕竟,面对有唐近三百年的文学积累,在一种单一的叙述框架之下又有多少诗人、多少诗歌能够得到充分讨论呢?而且就算我们认为确实有可能存在这样一种单一的叙述框架,何种诗歌应当被选入,何种又当被摒弃在外?一位诗人的全部作品应当如何呈现?文学史分析出的讨论单元,无论是一位个体诗人、一种诗歌风格抑或一种创作主题,又如何塑造和影响文学史的记述?如果我们想要摆脱有限的几位作家、文本的局限,在传世全部文学数据的基础上来理解唐诗,那么我们就需要采用一种宏观视角,一种从一开始就放弃对某些文本进行孤立的文本细读,而希求看到更广阔场域的历史视角。
三、作为文学研究方法的主题模型
研究中心、大学、政府部门甚或个人都在推行大规模文本数据化的项目,在此背景下,文学史判断也不能再完全依靠微观阅读。文本细读的问题在于,它只有在个别文本的规模之下才能成立,对于批评家来说,文本细读必然需要一种示范性的方法来择定和分析批评家选中的数据集合。[28]不过,要想使用远读的方法则要在一定程度上改变对阅读行为的理解方式;个人的数据搜集会受到耳闻目睹的影响,在本质上是受限的,这种新的理解方式使我们不再依赖个人的数据搜集能力。这就要借用机器来改变阐释过程了,机器提供了标量位移(scalar shift)和定量能力,这使阅读大量文本成为可能。对于分析某一首诗来说,计算分析(computational analysis)并非不可或缺,但面对上千首诗的时候,计算机的加入就使从宏观层面自海量文本中抽象出有意义的信息成为可能。N. Katherine Hayles曾经讨论过这一点,她注意到我们正在走进“机械阅读”(machine reading)时代,也就是说“对于人类阅读完全无法涵括的大量文本,计算机算法能够用来分析其中出现的模式。”[29]Stephen Ramsay写道:
注意到词汇的模式、句子的长短变化或者形象的明暗是一回事;而利用机器准确无误地找出大量文学文本中出现的相似特征,并且将这些特征以与其在文本中的组织方式完全不同的可视化方式呈现出来又是另一回事。或者更准确地说,后者与前者是一体两面的,而后者的方式体现出更强大的观察力。基于后者的分析结果,批评家探求的不再是事实,而是模式。而从模式出发,批评家可以更进一步地探讨更为广泛的修辞形式,由此形成批判性阅读。[30]
需要注意的是,在其著作的其他部分,Ramsay也认为由计算机辅助的阅读,也就是他所谓的“算法批评”(algorithmic criticism)并不是对传统文学阅读模式的激烈反拨,因为批评家的阐释实践也可以说是基于某种规则进行的,他们依循的规则与算法异曲同工,尽管批评家对文本的掌控和变形能力可能不会像计算机那样明确、程序化。回到Hayles的观点,计算机算法导向的阅读究竟能带来多大影响完全取决于研究对象,这种阅读方式面对的是规模更加庞大的文本聚合,而不再局限于某一个文本或是某几个文本组成的系列。
近来的研究,比如Andrew Piper的《列举法》[31]主要遵循的也是同样的指导原则:Piper使用数据方法(statistical method)从宏观角度来模拟人类读者的观点。他得出了一些令人印象深刻的结论,其中包括:一部小说中的各个形象之间的差别要大于他们与其他小说中形象的差别;以及20世纪科幻小说中的男主人公与19世纪女性小说中的女主人公一样具有内省性。尽管批评家选用的数据方法更加复杂,但是利用数据方法模拟实际读者批评观点的基本路数仍旧坚定不移。
主题模型是发掘文本的一种形式,也是一种阅读大宗文本的方法。这种方式对文学学者来说逐渐不再陌生,我们在此只作概述,意在引介之后讨论的术语。如要深入了解主题模型方法,可参考Meeks等的导论和综述。[32]简言之,主题模型方法利用一系列基于概率的算法来识别潜藏在既定文本中的语义模式。最通用的基于概率的模型,潜在狄利克雷分布(latent Dirichlet allocation,即LDA,详见Blei等2003年的文章[33])的共同作者David Blei也是这样描述这种方法的:
……主题模型方法的目标是从给定文本中自动识别出主题来。文本本身是可见的,但主题结构,如主题、每个文本中主题的分布情况以及每个文本每个词中的主题分配,则是隐藏结构(hidden structure)。主题模型方法的核心计算问题就在于利用可见的文本来推断隐藏的主题结构。这可以被认为是一种对通常过程的“颠倒”——在可见的文本中可能隐藏着何种隐藏结构?[34]
还有一些术语和概念需要进一步阐释。首先是潜在性(latency)的问题,Blei称之为文献中的“隐藏结构”。主题模型方法假设在可见文献之下还有一个潜在的语义结构,而且日常阅读中语词的意义与计算机识别出的意义之间是有区别的。主题模型方法意图寻绎这种隐藏结构,将之复原为这一组文献的生成模型(generative model),也就是与主题强相关的语词聚类所组成的矩阵,那些语词使文本得以成为现在的样态。这些涉及主题的语词聚类由文本中共现频率高的词组成,也就是算法试图为之建模的主题(topic),这里将主题理解为文本中各种重要的语词单元)。文献中的各个文本由语词组成,而主题指的就是一些特定的语词分配形态,从概率上讲,能够成为主题的语词分配形态是能够表示意义的。有鉴于此,文献中的各个文本又可以分别被理解为几个主题的汇合。因为在主题模型视域下,文献仅被视为“单词包”,每个词被单独地拉出来,并且根据它与其他共现词的共现频率安置到某一主题之下;所以具体文本中的词序并不重要。
先不说这样的模型对于文学史书写有何裨益,它要如何反映文学创作的过程也值得追问。实际上,它并不能反映文学创作的过程,但是这个模型能够接近文学创作的过程。作为读者,在我们的设想中,诗人的创作过程是这样的:首先,他确定了一个想要表达的观点,这个观点由一个或多个主题构成,比如“爱”或者“美”。接下来,诗人选择具体的形象来表达这些主题和观点,比如“爱”与“玫瑰花”。从这个阶段开始,诗人将观念投注到语词之中,比如“我的爱像一朵火红火红的玫瑰花”。一位现实读者读到这首诗的时候,会倒推回去:她看到诗人使用的实际语词,并将之转化为一系列的形象和思考,读者最终想要获得的是一种认识,“这个诗人究竟在写什么?”——换句话说就是诗人想要表达的主题是什么。上面描述的具体层次可能没那么重要:实际的写作和阅读过程可能都要更加丰富。我们的重点在于,我们所感受到的人类阅读活动的丰富性在于一首诗歌在读者心中唤醒的不同层级的体验:视觉形象、情感体验、词语唤起的共鸣、历史语境等。生产、消费文学的过程也就是表达、发现上述这些层面体验的过程。
LDA遵循的也是相似的过程:它从诗人的语词选择出发,假定驱遣诗人词汇选择(可见的变体)的是一些潜在的变体(即形象或主题)。LDA根据可见变体为潜在变体建模。尽管LDA只能提供一个近似的模式,但是因为较之人类读者,它没有那么复杂,因此扩展性更优。它对人类行为的推断较为简明:相比倾向于多向度、多层次解读的真实读者,LDA只关注两层意义(可见变体以及潜在变体)。但是,它的可操作范围更大,而且因为不受人类记忆的制约,所以也更加准确。现实操作过程中,如果学者在利用LDA时想要追求更高的准确度的话,她需要假定潜在变体会与真实读者用自己的阐释方法发现的一些要素相合,并且把LDA提取的主题理解为形象、主题或观念的模式。这就使得她需要在实际读者通过有限阅读提取出的丰富意涵与LDA模型所发现的不那么丰富的潜在模式之间完成一种折中。
通过这种折中,我们可以得到另外一种建构文学史的模式,一种能够涵括更多文本的模式。如果将文学史视为一个发现历史质素的认识过程,一个求索文学的历史是在何种规范下被建构的过程,那么面对我们先前接受的种种证据标准,这种新的视角无疑具有重构观念的潜力。本文接下来的部分看起来很可能不像文学史,实际上较之批评分析,它也确实更近似于实验报告,但这是必须的工作:我们坚信宏观文学史需要不同的方法,这种方法应当是能够在人类与机器的文本视角之间折中的方法。我们要再次强调,在诗歌研究、乃至更广阔的研究领域中采用这种得到计算手段支撑的研究方法十分重要。下文的阐述会使读者看到,通过主题模型方法审视《全唐诗》能够带来多么有启发性的成果,它让我们看到了更多的诗歌,这些诗歌的作者和题材在之前并未得到学者的充分关注,但是经过细致的审视,却会发现它们在文学和历史两方面都有相当的典型性。更重要的是,能够识别出这些诗歌,并且提取出它们之间在主题上的关键相似(和差异)正要归功于LDA主题模型方法在分析方式方面的关键贡献:它能够推断一些不常在相同文本中出现,甚至从未共现过的语词之间的语义复合关系,它的能力还体现在它能够处理更大量的文献,而把握这些文献对于最博知的学者来说都是不可能完成的任务。这种讨论同时也强调人类在计算机辅助分析过程中的“局内人”作用,因为计算机分析方法对意义的认定与现实读者从人文主义视角析读出的意义有时会产生分歧。
四、《全唐诗》和主题模型
首先需要说明的是,我们利用的主题模型分析程序是MALLET(MAchine Learning for LanguagE Toolkit,自然语言处理工具包)。[35]因为文本的缺憾会使分析结果发生偏移,所以在主题建模过程中,我们并未处理《全唐诗》中的残章断句。不过,我们保留了卷881,是卷仅收诗歌启蒙读物《蒙求》,《蒙求》可以被分析为与诗歌长度相当的部分,这类文本均可予保留。因为古代汉语中一些表示语法意义的虚词在其他语境中可能有其他非虚词的意义,因此我们没有设置停用词(stop-word)。我们设置MALLET生成150个主题,这个数目(依迭代试错过程得出)能够在提供最复杂信息的同时,使阐释中的疑难得以最小化。[36]通过以上设置,我们得到了3份报告:其一是主题—关键字报告(TKR, topic-keys report),其二是主题—短语报告(TPR, topic-phrase report),其三是文本—主题报告(DTR, document-topics report)——这三份报告都会讨论到。对主题模型方法有了解的读者对此并不会觉得陌生,但为论述清晰,我们还是要对上述报告进行一些分析。
导出的第一份报告是主题—关键字报告,此报告开列的主题排名不分先后,每一主题之下均按照相关度强弱顺序列出与此主题关联度最高的20个关键字(因为20是MALLET的默认数,每个给定主题只列相关度最高的20个关键字)。以下是TKR列表中的前11个主题:
1.马车骑行尘出长鞭门走白嘶金蹄道鞍青黄驰驱
2.酒醉杯饮一客酌醒劝满尊倾对笑壶欢酣送倒且
3.不人能知谁生自有无来岂得在与作但令可古解
4.相年家见弟同兄来逢长少还自许多喜说亲作时
5.江海迢潮帆吴越楚孤沧客去洲波归远湖浪递南
6.寂遥寥空落寞朝风独见中思林月清在寒逍想招
7.夜月明灯晓残漏星声更照暗寒宿烛火半光露钟
8.我不为此言尔者何有亦如生人与得苦无所愿令
9.水东流西山日去云空落归中路陵白复见长暮尽
10.金玉珠银紫锦重宝黄光刀环裁佩衣双盘珊龙垂
11.萧风雨秋暮条寒云吹起独飒晚上日树叶空向索
左侧序号是MALLET给定的主题编码,主题先后次序不区别意义,右侧关键字依照与主题相关度降序排列。
主题仅是关键字的聚合,因此具体理解主题代表什么就需要在主题—关键字报告中为主题拟出题名。加上题名是为了将机器的文献分析视角转换为人类使用的术语,仅为方便使用;但是对于后续阐释来说,这些题名必不可少。以下还是上述11个主题,现在加上我们的临时题名。
1.马车骑行尘出长鞭门走白嘶金蹄道鞍青黄驰驱——马,行旅
2.酒醉杯饮一客酌醒劝满尊倾对笑壶欢酣送倒且——饮酒
3.不人能知谁生自有无来岂得在与作但令可古解——虚词,常用动词
4.相年家见弟同兄来逢长少还自许多喜说亲作时——家人,家
5.江海迢潮帆吴越楚孤沧客去洲波归远湖浪递南——南方水景
6.寂遥寥空落寞朝风独见中思林月清在寒逍想招——远方和想望
7.夜月明灯晓残漏星声更照暗寒宿烛火半光露钟——夜:月光和湿意
8.我不为此言尔者何有亦如生人与得苦无所愿令——虚词,代词
9.水东流西山日去云空落归中路陵白复见长暮尽——景观:旅人
10.金玉珠银紫锦重宝黄光刀环裁佩衣双盘珊龙垂——珍贵之物
11.萧风雨秋暮条寒云吹起独飒晚上日树叶空向索——秋日傍晚景象
仔细审视我们命名为“马,行旅”的主题1:该主题下的关键字或是主题上与马和行旅有关,或是句法连续性的呈现。句法连续性是语言学家黄宣范提出的概念,主题1中的三个颜色词即是因句法连续性才在此主题下出现的关键字。[37]
比较难于命名的是像主题4这样的数据,这一组包含很多常用词,包括相、年、家、见、弟等。这些词可能与和家庭、家人相关的主题有关,但也可能出现在更广阔的主题范围之内。这样的主题还有几组,其中语词的意义很清晰,但是它们在语义上的联系则或多或少有些模糊,需要现实读者来补充其中的间隙,去想象这样的语词能够建构起怎样的诗歌。这就出现了赋予意义的问题,在这些主题当中,意义是不确定的,或者说至少在人类文化范畴之内,这些词表达的意义并未被确定下来。
下面进入MALLET导出的第二份报告,主题—短语报告中也可以看到第一份报告中的结果,但它呈现出了更多的细节,包含词语的权重以及高频出现的短语。这份报告首先罗列了各个主题之下经常出现的短语(标记的组合),接下来降序列出该主题之下前19个高频词,之后是降序排列的前21个高频短语。TPR报告比TKR还要长,这里只列主题1的部分,整合为两个独立的表格。表2依词频降序排列,列出权重以及标记总数。
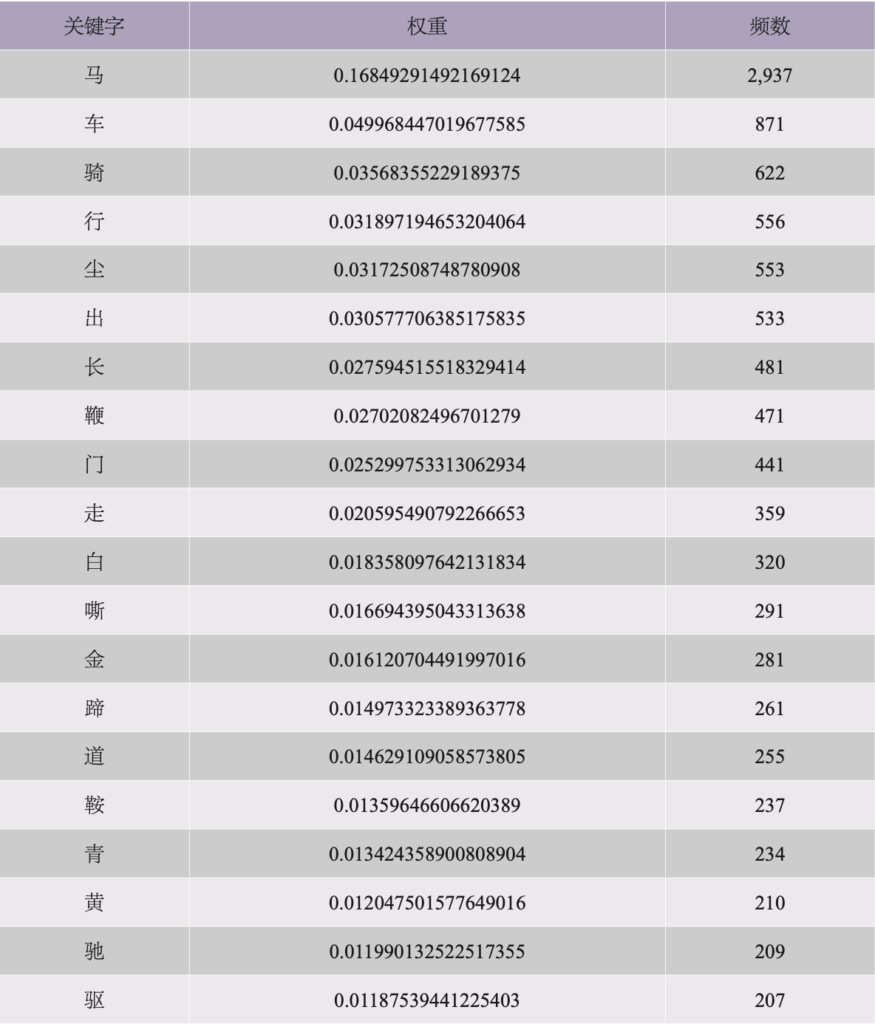
表2
表3列出的是高频短语,同样列出词频以及总数。
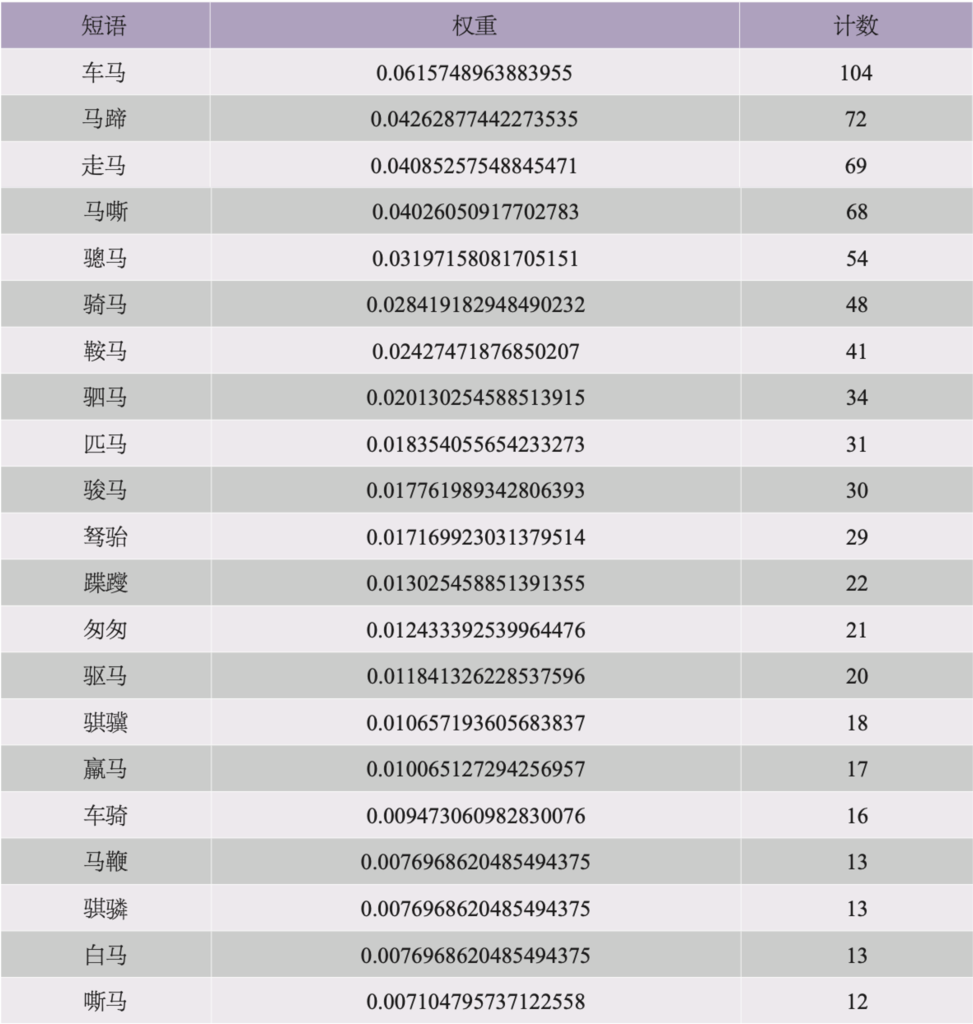
表 3
正如表2、表3所显示的,TPR报告对各个关键字与主题的相关度做出了更清晰的破析。每个词后的数值表示的是它的主题权重,即各个关键字在内含同主题的各篇文本中出现的频数。比如,主题1之下排名第一的字是“马”,TPR报告中呈现的权重是0.1685(四舍五入),频数是2,937,这意味着“马”这个字的出现频率在全部文献中被划为主题1的17,431个字中占了16.85%(以上数值亦见于TPR报告)。也就是说,在全部文献中,“马”出现的频数要超过2,937,但是其中有2,937个词例与主题1有关。在TPR报告中,在任一特定主题之下,大多数词的权重都小于0.001,这是默认先验概率的体现,也就是说,在给定文献的全部词汇之中,理论上每一个词都有概率出现在任一主题之下,哪怕概率极小。TPR报告中,这些权重极低的词虽仍列于给定主题的统计数据中,但其权重却几乎可以忽略不计。对于某些主题来说,强相关的关键字分布可能比较均匀;但是对另外一些主题来说,相关度最强的关键字与第二位的关键字之间可能就已经有了很明显的数值差距。
MALLET导出的最后一份报告是文本—主题报告,它呈现的是各个主题在所有文本中的强度。这是一份格外长的报告,其中包含150个主题在《全唐诗》中每一首诗所占的百分比。本文只节取报告的一部分,也即文献中的“诗30_1”,意为卷30的第1首诗。此诗题为《咏汉高祖》。以此诗为例并非随机选择,正是从这首诗开始,《全唐诗》开始依各诗人年辈为序进行编年,开始遵循文学史的逻辑。更重要的是,这首诗的作者是隋末唐初的诗人王珪(570—639),他在唐太宗(626—649年在位)朝任职,其主要成就亦不在诗。这是一篇如果没有收在《全唐诗》当中就会被读者遗忘的作品,正可充当“未被阅读的大多数”的范例。
进入分析报告之前,先要对此诗文本有所了解:
汉祖起丰沛,[38]乘运以跃鳞。[39]手奋三尺剑,西灭无道秦。十月五星聚,[40]七年四海宾。[41]高抗威宇宙,贵有天下人。忆昔与项王,[42]契阔时未伸。鸿门既薄蚀,荥阳亦蒙尘。[43]虮虱生介胄,将卒多苦辛。爪牙驱信越,腹心谋张陈。[44]赫赫西楚国,化为丘与榛。[45]
这是一首典型的咏史诗,题咏的是有汉的开国君主。[46]这首诗的脉络首先略述汉高祖的崛起,接下来叙述汉高祖与强敌项羽的战争,最后以西楚项羽的覆亡作结。这首诗引人联想到一个失落的时代,彼时有英雄、有胜利的荣光、传奇化的逃亡以及悲剧性的覆亡,这个故事终结于有汉立国的辉煌以及西楚以凄凉告终的命运。
不过,MALLET的文本—主题报告提供了分析这首诗歌的另外一种方式。这份报告体量颇大,我们只列出百分比超过1%的主题:

开头的1969和30_1是这首诗的编码(“1969”指此文本为给定文献中的第1969篇,“30_1”是此文本所属的卷数以及此文本在该卷的序数)。之后MALLET给出了两方面的信息:主题编码以及该主题在此文本中所占的百分比。报告中会将全部150个主题在此文本中所占的百分比按降序排列(再次强调,MALLET假定给定文献的每一个文本都内含全部150个主题,即使其中有些主题的权重几乎可以忽略不计)。我们可以看到,在这个文本中,主题30占比最高,约占全诗的10.95%。对于这首诗来说,只有前21个主题才有意义,因为余下的主题都属于那些无足轻重的数据。以下是前21个主题(百分比四舍五入),按所占百分比降序排列,另附上我们暂时为以下主题拟定的题名。
根据表4,我们可以说《咏汉高祖》是一个由类属分明的诸多主题搭建起的文本,我们可以将这些主题命名为“帝国与君权”“有限的生命,饮食”“真韵”[47]“军事,军队”“愧疚,追悔”“数字,时间词”“汉及汉以前的国家”“疆域,基础方位词”,以及稍显模糊的“庭院/风景”。这些主题中,有一些有明确的语义特征(比如两个“帝国”主题),但另外一些只承担句法功能,只有语法意义(“代词和虚词”),还有一些只代表诗歌的形式特征(“真韵”)。我们还发现这首诗中有几个主题不好命名,比如指向不明确的主题42(“庭院/风景?”),另外又有一些主题的出现令人费解,如主题66(“尤韵”),这是另外一个指向韵部的主题,但这首诗并无押“尤”韵之处。我们需要时刻注意,这些我们在阐释过程中面对的难以索解之处正是实际读者与MALLET阅读文献的不同方式所带来的,MALLET从文本中识别出的主题只基于词汇的分布,并不考虑语义方面的理据。人与机器的读解有时殊途同归,将我们引向对文本更深刻的洞察;但另外一些时刻,我们又会明显地感受到人与机器在方法论,还有本体论层面的差异。
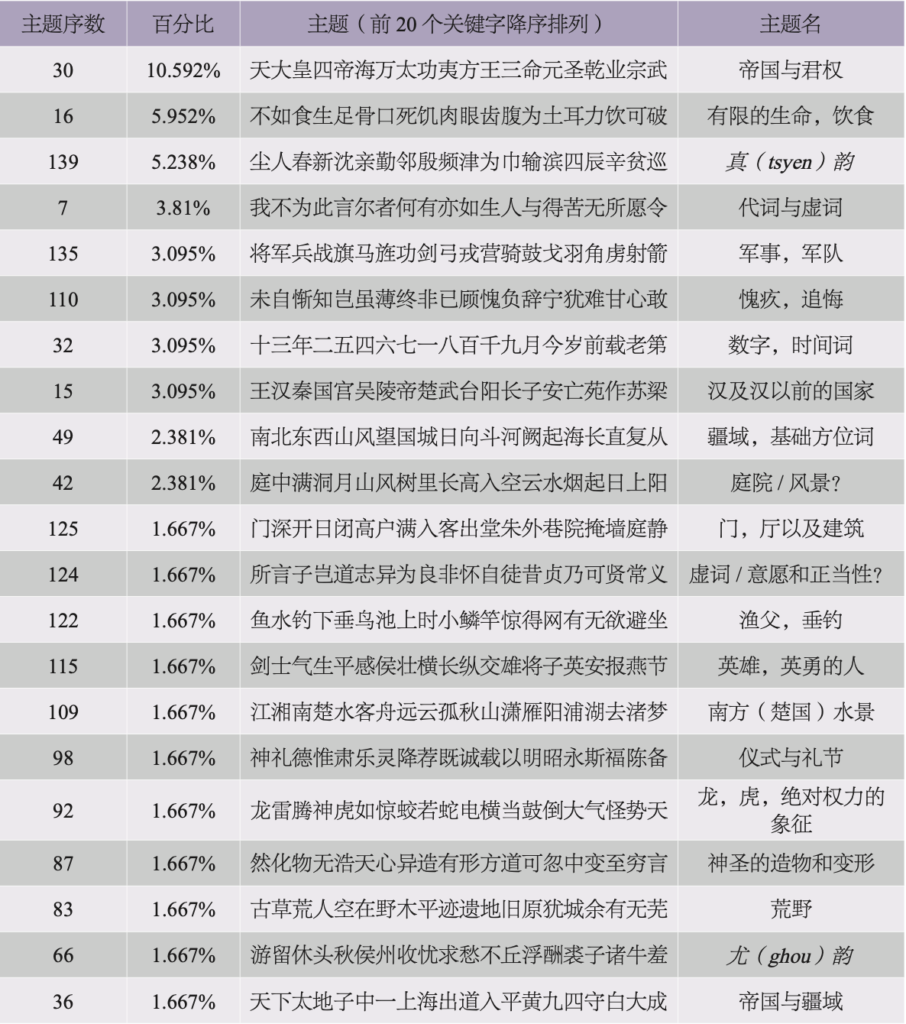
表 4
五、从主题出发思考文学史
到现在为止,主题模型方法在《全唐诗》分析当中的应用主要还是体现在重新阐述了一些问题,也即如何呈现诗歌文献以及如何存取文献信息。我们确实提出了一种分析视角。利用这一视角审视诗歌文本时,明确主题模型的含义成为了关键。我们认为主题模型方法可以帮助我们思考文学史叙述建构中的去取标准问题,这使我们能够游弋于海量未及阅读的唐诗文本;批评家个人的偏嗜、基于选本的文学训练以及其他在文学史话语中呈现出的不可确知的历史选择都在影响着文学史书写中的选择行为,而新视角则能够让文学史书写的选择过程不必受到这些干扰。在实践主题模型方法的过程中,有一些环节更多地依赖实际读者的阅读和阐释,而另外一些环节则更依赖机器的判读,如此形成的文学史叙述将不会完全失控。这种阅读方式并非乌托邦式的、对后人类时代阅读的幻想,并非要让机器的客观性完全取代人类的能动性,而是追求在机器辅助视角与传统“模拟”(analog)视角之间达到一种动态平衡。不过不可否认的是,我们采用的这种方法确实是在严肃地尝试如何引入机器视角,我们尝试着理解机器如何看待给定的文本,并且尝试着将机器的视角转写为人类的话语。为此,我们采用了Jensen-Shannon散度度量方法,[48]此方法能够量化任何(有限)数量的概率分布之间的差异。在这里,概率分布中的“概率”指的是各主题构成文本的概率,就像前文所叙MALLET文本—主题报告呈现的那样。[49]尽管JS度量本意在于衡量“散度”,我们也能够用它来探究文本的相似性,可以类比向量相似度测量,同时也能够实现对大量文献的无监督信息检索。[50]
我们前面讨论到《咏汉高祖》(诗30_1)是因为它是《全唐诗》主体部分的第一首诗(依作者生平编年的卷30—731),而它在文学史上的无名又刚好使之得以充当唐诗“未被阅读的大多数”的代表;如果用这首有意识选择的诗作为无监督检索的起点,未免显得有些武断。不过,我们也可以认为这首《咏汉高祖》是我们在基于主题的《全唐诗》索引工具中钩沉出的,现在我们要来找一找与这首诗在主题上有相似性的诗歌。以《咏汉高祖》为标的文本,依据《全唐诗》主题分布进行JS散度度量,我们能够找到5首与它最相似的文本。

表 5
表5呈现的信息已经足够清楚,但还是要简单说明一下,因为《咏汉高祖》是相似性度量的基准,所以度量得到的值是1.0,也就是说这首诗与它自身完全一致;一个文本与《咏汉高祖》越相似,表示相似指数的分数也就越大。
散度度量得出的一个颇具震撼力的结果是,虽然《咏汉高祖》一直被认定为咏史诗,但它与源出仪轨、祭祀场合的诗歌有相当密切的亲缘。散度取值最高的一首诗是诗13_68,《享太庙乐章·象德舞》,作者是中晚唐的官僚诗人段文昌(773—835):
肃肃清庙,登显至德。泽周八荒,兵定四极。生物咸遂,群盗灭息。明圣钦承,子孙千亿。[51]
这首颂诗是“郊庙歌辞”,属于仪轨歌谣。据《旧唐书》,《象德舞》奠献于唐宪宗(805—820年在位)的陵寝之前(要想深入了解这种形式,可以参考Kevin Jenson的文章[52])。[53]此诗没有采用唐代最为通行的五言(或七言)形式,而是用了古雅的四言;这种选择在其他仪式中或正式的宫廷场景中也很常见。[54]诗句本身相当直接,并没有很深的审美意蕴,此诗的主要功能也不过是将仪式进行的瞬间转化为语言表现而已。
从这一点出发,有鉴于诗歌类型和应用场合方面的差异,段文昌的这首诗与王珪的《咏汉高祖》似乎没有什么共通之处。但是,《享太庙乐章·象德舞》的DTR(文本—主题报告)却揭示出两首诗相似的主题组合模式(表6)。

表 6
《咏汉高祖》与《享太庙乐章·象德舞》中,权重最高的主题都是主题30(“帝国与君权”),这一点也是致使两首诗相似指数很高的重要因素。但是,两个文本的高频主题也都有32(“数字,时间词”)、98(“仪式与礼节”)、87(“神圣的造物和变形”)、109(“南方〔楚国〕水景”)、15(“汉及汉以前的国家”)、83(“荒野”)及36(“帝国与疆域”),这一点也很重要。这就呈现出明显的主题相似性。但是,鉴于这两首诗一首是五言的咏史诗,一首是四言仪轨用诗,句式、类型都不同,因此在通常的分类模式下更易被区隔开来,传统的文学史也不会将这两首诗联系起来。
在此基础上更进一步,对比文本中权重各异的主题能够帮助我们更好地理解相似性和离散程度在文化、语义层面有怎样的意味。《咏汉高祖》和《享太庙乐章》占比最高的主题都是30(“帝国与君权”),不过它们第2位的主题就已经发生了分歧,《咏汉高祖》第二高频的主题是16(“有限的生命,饮食”),《享太庙乐章》则是87(“神圣的造物和变形”)。这表明咏史诗与同样关注历史题材的仪轨用诗的差别在于如何加入第二组主题词汇。我们命名为“有限的生命,饮食”的这个主题唤起的是主观体验,它将对历史记忆的追悼与作为个体的诗人连接起来,这样的主题对于一首有更高要求,而且想要表达“神圣的造物和变形”的仪轨用诗来说自然是不妥的。
最后还有一个与主题相关的问题,这也是MALLET识别出来的,但对于现实读者来说却不甚明显。比如分别在《咏汉高祖》和《享太庙乐章》中序次很高的主题122(“渔父,垂钓”)和149(“隐居”)。这两个主题各自不见于另一个文本(当然还有一些其他主题也是这样),但有趣的是它们在各自所属的文本中也没有足够分明的体现。那么问题就来了,为什么MALLET认为这些“幽灵主题”在文本中十分重要,但是在文本中,这两个主题的关键字却体现得并不明显呢?我们假设,机器之所以会识别出这些幽灵主题,是因为它们与文本中能够明确识别出的主题相近,而且机器识别出的主题表明这些文本可能属于共同的语义网络。[55]也就是说,就算《咏汉高祖》没有提到渔父、垂钓(关于谦退者智慧的常见话语)的话,那么这首诗中也还是包含着一些或多或少与渔父主题有关联的语词组织,主题122“南方(楚国)水景”和115“英雄,英勇的人”都是这样,它们暗示着“渔父,垂钓”的主题应当可以被安置在这两个基于概率的主题分布所织就的语义网络之中。同理,在《享太庙乐章》中也没有出现“隐居”的主题。这首诗的高频主题,诸如主题87(“神圣的造物和变形”)、98(“仪式与礼节”)、131(“宫廷”),都在强调宫廷仪轨,但也正是宫廷仪轨的存在才为隐居创造了空间。隐士的形象通常被塑造得与廷臣截然相反,这两个群体代表着社会生活的两种不同面相向。
总结一下:如果我们更多地考虑组成诗歌的语词,而非类型和传统的体式,就能清楚地看到,不同的诗歌范型会有各自常用的一套术语,它在诗歌文本之间创造了一种隐性的联结。如果我们依循传统的线索去阅读,这种联结并不容易被识别。探寻诗歌之间隐藏的,或是不够显著的文本联结本身并不是文学史,但是这种探寻却为想象文学史奠定了一层新的实证基础。在依照作家生平发展的时间线索叙述诗歌风格、类型(genre)的发展过程之外,我们也可以采用一种全然不可知论式的主题学方式,将文学创作看作“单词包”,接下来在不同的单词包之间寻找词汇上的共通之处,并且依据主题来决定分析、判断时应当使用哪些文本。数据的完整性和选择性问题为历史描出了地图、定下了疆界,在形成历史叙述时,数据问题始终是笼罩不去的阴云。我们现在给出的这种方法可能也无法回答这个问题,但是这种方法能走入文学史的无意识世界中去,这个无意识世界也就是在现代数据库与文献数字化进程中被唤醒、并且逐渐面目清晰的“未被阅读的大多数”的世界。
这里我们要再次强调,现实读者并不能掌控海量的文本,机器阅读也不能将模型转化为有意义的论断。只有将机器与现实读者的视角整合起来,才有可能阅读《全唐诗》这般规模的总集;而只有将这部总集作为一个整体来阅读,我们才能针对其内容建立起一个普适的模型;只有结合这样一个普适的模型,文学史书写才能找到一个对数据进行芟荑的标准,从而构建起一种文学史叙述。
Reading the Quan Tang shi: Literary History, Topic Modeling, Divergence Measures
Peter Broadwell, Jack W. Chen, David Shepard
Abstract: The present paper addresses the problem of literary history as a problem of data comprehensiveness and selection, seeking not to resolve the impossibility of literary historical narrative, but to reframe it through a computational perspective. Our focus is on the Quan Tang shi, the massive comprehensive anthology of Tang poetry that was produced at the height of the Qing dynasty (1644-1912). The sheer quantity of Tang poetry preserved in the Quan Tang shi (over 50,000 poems and poem fragments) exceeds the humanscale perspectives of close reading. To make sense of the corpus as a whole, we will show how two related forms of distant reading—topic modeling and divergence measures—allow us to reframe and rethink these literary historical questions and provide a new perspective on what it means to read Tang poetry.
Keywords: Quan Tang shi; Literary History; Topic Modeling; Divergence Measures
(编辑:严程)
我们要感谢Timothy R. Tangherlini深入透辟的建议,以及Evan Nicoll-Johnson、 Yunshuang Zhang和Ruichuan Wu在本项目数据准备环节的帮助,还要感谢前加利福尼亚大学洛杉矶分校数字人文中心(现HunTech)提供的会议场所和资源支持。
注释:
[1]Rosenthal(Jesse Rosenthal, “Introduction: Narrative against Data,” Genre, vol. 50, no. 1, 2017, pp.1-18)并未涉及叙述形式对数据模型的影响问题,但其对于叙述与数据关系的探讨仍可参看。 Flanders和Jannidis(Julia Flanders, Fotis Jannidis, “Data Modeling,” in Susan Scriebman, Ray Siemens, and John Unsworth eds., A New Companion to Digital Humanities, Chichester, UK: John Wiley & Sons, Ltd, 2016, pp. 229-237)讨论了数据建模的问题,但他们并未将叙述本身作为一种数据模型。
[2]Franco Moretti, “Conjectures on World Literature,” New Left Review, vol. 1, Jan 2000, pp. 54-68; Ted Underwood, “A Genealogy of Distant Reading,” DHQ: Digital Humanities Quarterly, vol. 11, no. 2, 2017, http://www.digitalhumanities.org/dhq/vol/11/2/000317/000317.html.
[3]Andrew Piper, “Novel Devotions: Conversional Reading, Computational Modeling, and the Modern Novel,” New Literary History, vol. 46, 2015, p. 69.
[4]Ryan Nichols et al., “Modeling the Contested Relationship between Analects, Mencius, and Xunzi: Preliminary Evidence from a Machine-Learning Approach,” The Journal of Asian Studies, vol. 77, no. 1, 2018, pp. 19-57, https://doi.org/10.1017/S0021911817000973.
[5]Colin Allen et al., “Topic Modeling the Hàn di ǎn Ancient Classics,” Journal of Cultural Analytics, 2017,http://doi.org/10.22148/16.016.
[6]Paul Vierthaler, “Fiction and History: Polarity and Stylistic Gradience in Late Imperial Chinese Literature,” Journal of Cultural Analytics, 2016, DOI: 10.22148/16.003; Hoyt Long, Richard Jean So, “Literary Pattern Recognition: Modernism between Close Reading and Machine Learning,” Critical Inquiry, vol. 42, 2016, pp.235-267.
[7]Chao-Lin Liu, Thomas J. Mazanec and Jeffrey R. Tharsen, “Exploring Chinese Poetry with Digital Assistance: Examples from Linguistic, Literary, and Historical Viewpoints,” Journal of Chinese Literature and Culture, vol. 5, no. 2, 2018, pp. 276-321.
[8]David Perkins, Is Literary History Possible?, Baltimore: The Johns Hopkins University Press, 1992, p. 13.
[9]David Perkins, Is Literary History Possible?, p. 13.
[10]Johanna Drucker, “Humanities Approaches to Graphical Display,” Digital Humanities Quarterly, vol. 5, no. 1, 2011, http://www.digitalhumanities.org/dhq/vol/5/1/000091/000091.html; Daniel Rosenberg, “Data before the Fact,” In Lisa Gitelman ed. “Raw Data” Is an Oxymoron, Cambridge: MIT Press, 2013, pp. 15-40.
[11]René Wellek, Austin Warren, Theory of Literature, 3rd ed., New York: Harcourt, Brace&World, 1956.
[12]需要注意的是,韦勒克、沃伦的《文学理论》第一版出版于1948年,同年,克劳德·香农发表了《通讯的数学原理》一文,这篇文章通常被看作信息时代的先声。韦勒克和沃伦自然没有提到香农关注的工程学问题,但他们已经意识到大量可能存在的文学事实会对文学史书写产生巨大影响。在信息科学史与文学史学科的交叉研究方面已有一些研究,但此领域仍旧大有可为( Bernard Dionysius Geoghegan, “From Information Theory to French Theory: Jakobson, Lévi-Strauss, and the Cybernetic Apparatus,” Critical Inquiry, vol. 38, 2011, pp. 96-126; Lydia Liu, The Freudian Robot: Digital Media and the Future of the Unconscious, Chicago: University of Chicago Press, 2010, pp. 153-200)。
[13]Margaret Cohen, The Sentimental Education of the Novel, Princeton: Princeton University Press, 1999, p. 23.
[14]Franco Moretti, “The Slaughterhouse of Literature,” MLQ: Modern Language Quarterly, vol. 61, no. 1, 2000,p. 209.
[15]Katherine Bode, “The Equivalence of Close and Distant Reading, or, Toward a New Object for Data-Rich Literary History,” Modern Language Quarterly, vol. 78, no. 1, 2017, p. 90.
[16]Ann Blair, Too Much to Know: Managing Scholarly Information before the Modern Age, New Haven: Yale University Press, 2011.
[17]《全唐诗》当然并未收录所有的唐代诗歌,可参考陈尚君:《全唐诗补编》,北京:中华书局, 1992年。敦煌藏经洞20世纪才被发现,《全唐诗》自然也无从收录敦煌诗歌(任中敏编:《敦煌歌辞总编》,南京:凤凰出版社, 2014年)。 Jonathan D. Spence, Ts’ao Yin and the K’ang-hsi Emperor. Bondservant and Master, Second edition, New Haven: Yale University Press, 1966, pp. 156-165.(史景迁《曹寅与康熙——一个皇帝宠臣的生涯揭秘》,有陈引驰等译上海远东出版社2005年本以及温洽溢译广西师范大学出版社2014年本——译者注)
[18]Matthew L. Jockers, Macroanalysis: Digital Methods & Literary History, Urbana: University of Illinois Press, 2013, p. 172; Katherine Bode, “The Equivalence of Close and Distant Reading,” Modern Language Notes, vol. 78, no. 1, 2017, pp. 77-106.
[19]佟培基:《近三百年〈全唐诗〉的整理与研究》,《文献》 1998年第3期。
[20]胡震亨:《唐音统签》,上海:上海古籍出版社, 2003年。
[21]钱谦益、季振宜辑,屈万里、刘兆祐主编:《全唐诗稿本》,台北:联经出版事业公司, 1979年。
[22]Joseph R. Allen, In the Voice of Others: Chinese Music Bureau Poetry, Ann Arbor: Center for Chinese Studies, The University of Michigan, 1992; Stephen Owen, The Making of Early Chinese Classical Poetry, Cambridge: Harvard University Asia Center, 2006, pp. 301-307.
[23]Pauline Yu, “Poems in Their Place: Collections and Canons in Early Chinese Literature,” Harvard Journal of Asiatic Studies, vol. 50, no. 1, 1990, p. 170; also see “The Chinese Poetic Canon and Its Boundaries,” In John Hay ed. Boundaries in China, London: Reaktion Books, 1994, pp. 105-123.
[24]Jean-Pierre Drège, “Des ouvrages classés par catégories: les encyclopédies chinoises,” In Florence Establet-Bretelle and Karine Chemla eds. Qu’était-ce qu’écrire une encyclopédie en Chine? / What Did It Mean to Write an Encyclopedia in China?, Extrême-Orient, Extrême-Occident, hors série, 2007, pp. 19-38.
[25]Xiaofei Tian, “Literary Learning: Encyclopedias and Epitomes,” Wiebke Denecke, Wai-Yee Li, and Xiaofei Tian eds., Oxford Handbook of Classical Chinese Literature (1000 BCE-900 CE), New York: Oxford University Press, 2017, pp. 132-146.
[26]钱仲联等编:《中国文学大辞典》,上海:上海辞书出版社, 2000年,第364页。
[27]Stephen Owen, The Poetry of the Early T’ang, New Haven: Yale University, 1977; Stephen Owen, The Great Age of Chinese Poetry: The High T’ang, New Haven: Yale University, 1981; Stephen Owen, The Late Tang: Chinese Poetry of the Mid-Ninth Century (827-860), Cambridge: Harvard University Asia Center, 2006.(宇文所安的《初唐诗》《盛唐诗》《晚唐》均有贾晋华译本,由三联书店出版——译者注)许总:《唐诗史》,南京:江苏教育出版社, 1994年;杨世明:《唐诗史》,重庆:重庆出版社, 1996年。
[28]Miranda B. Hickman, John D. McIntyre eds., Rereading the New Criticism, Columbus: Ohio University Press, 2012; Joseph North, “What’s ‘New Critical’ about ‘Close Reading’? I. A. Richards and His New Critical Reception,” New Literary History, vol. 44, no. 1, 2013, pp. 141-157.
[29]N. Katherine Hayles, “How We Read: Close, Hyper, Machine,” ADE Bulletin, vol. 150, 2010, p. 72.
[30]Stephen Ramsay, Reading Machines: Toward an Algorithmic Criticism, Urbana: University of Illinois Press, 2011, p. 17.
[31]Andrew Piper, Enumerations: Data and Literary Study, Chicago: University of Chicago Press, 2018.
[32]Elijah Meeks, Scott B. Weingart, “The Digital Humanities Contribution to Topic Modeling,” Journal of Digital Humanities, Special issue, vol. 2, no. 1, 2012, http://journalofdigitalhumanities.org/2-1/dhcontribution-to-topic-modeling/; Ted Underwood, “What Kind of ‘Topics’ Does Topic Modeling Actually Produce?,” April 1, 2012, https://tedunderwood.com/2012/04/01/what-kinds-of-topics-does-topicmodeling-actually-produce/; Allen B. Riddell, “A Simple Topic Model (Mixture of Unigrams),” July 22, 2012, https://www.ariddell.org/simple-topic-model.html.
[33]David Blei, Andrew Y. Ng, and Michael I. Jordan, “Latent Dirichlet Allocation,” Journal of Machine Learning Research, vol. 3, 2003, pp. 993-1022.
[34]David Blei, “Probabilistic Topic Models,” Communications of the ACM, vol. 55, no. 4, 2012, p. 79.
[35]Andrew Kachites McCallum, MALLET: Machine Learning for Language Toolkit, 2002, http://mallet.cs.umass.edu/index.php.
[36]LDA理想主题数量的优化问题仍有待解决。关于这一问题的讨论以及相关的技术来源,参见Timothy R. Tangherlini, Peter Leonard, “Trawling in the Sea of the Great Unread: Sub-corpus Topic Modeling and Humanities Research,” Poetics, vol. 41, p. 731。
[37]Shuanfan Huang, Chinese Grammar at Work, Amsterdam: John Benjamins Publishing Company, 2013,pp. 55-80.
[38]汉高祖刘邦(前256—前195,前202—前195在位),汉朝(前202—220)的开国君主。
[39]李白《古风》其一的“群才属休明,乘运共跃鳞”也采用了相似的意象,见瞿蜕园、朱金城:《李白集校注》卷2,上海:上海古籍出版社,1980年,第91页;彭定求等编:《全唐诗》卷161,北京:中华书局,1960年,第1670页。
[40]“十月五星聚”是祥瑞之象,“五星”在天,各应五行(水、金、土、火、木)。
[41]即各地人民都成为了高祖的子民。
[42]项羽(前232—前202)是楚国贵族,曾与刘邦合力发兵灭秦(前221—前207)。秦亡(前207)之后,项羽立国西楚,自立为王,与刘邦相抗衡。项羽最终兵败垓下,自杀身死。
[43]这两句指的是项羽曾在鸿门与荥阳两次计划诛杀后来的汉高祖刘邦。鸿门宴上,项羽从弟项庄本应借舞剑之机击杀刘邦,但项羽的叔父项缠亦起身舞剑保护高祖。之后,高祖之兵被围荥阳(在今河南),高祖以女子带甲出荥阳城门,自己则带领数人成功逃脱。(Sima Qian, Records of the Grand Historian: Han Dynasty I, Trans. Burton Watson, Rev. ed., Hong Kong and New York: The Research Centre for Translation, Chinese University of Hong Kong and Columbia University Press, 1993, pp. 30-33, 38-40; 司马迁:《史记》卷7,北京:中华书局, 1959年,第313、 326页。)
[44]韩信(?—196年)和彭越(?—196年)都是刘邦麾下的将领。张良(?—186年)与陈平(?—178年)是刘邦的谋士。
[45]西楚(前206—前202)是项羽灭秦之后所建立的国家。
[46]王珪:《咏汉高祖》,见彭定求等编:《全唐诗》卷30,北京:中华书局, 1960年,第429页。
[47]中古汉语的同韵字可在韵书中查考。在韵书中,在押同一韵的单字会被编入某一韵目之下,韵目可以用来代表整个韵部。为呈现韵目字的读音,我们采用了林德威( David Prager Branner)的中古汉语拟音( David Prager Branner, “A Neutral Transcription System for Teaching Medieval Chinese,” T’ang Studies, vol. 17, 1999, pp. 1-169.),我们还利用了他的在线声韵学数据库“音通”(林德威、翁翌, Yintong: Chinese Phonological Database[音通:声韵学数据库]),链接如下: http://yintong.info/yintong/public/index.php。
[48]Jianhua Lin, “Divergence Measures Based on the Shannon Entropy,” IEEE Transactions on Information Theory, vol. 37, no. 1, 1991, pp. 145-151.
[49]JS度量得名于“琴生不等式”( Jensen’s inequality,由约翰·延森[Johan L. W. V. Jensen]提出,参见Johan L. W. V. Jensen, “Sur les fonctions convexes et les inégalités entres les valeurs moyennes,” Acta Mathematica, vol. 30, 1906, pp. 175-193; Tristan Needham, “A Visual Explanation of Jensen’s Inequality,” The American Mathematical Monthly, vol. 100, no. 8, 1993, pp. 768-771)和“香农熵”( Shannon entropy,由香农[Claude E. Shannon]提出,参见Claude E. Shannon, “A Mathematical Theory of Communication,” Bell Systems Technical Journal, vol. 27, 1948, pp. 379-423, 623-656; Claude E. Shannon, Warren Weaver, The Mathematical Theory of Communication, Urbana: The University of Illinois Press, 1949)。
[50]计算文本之间的相似性还有其他方法,包括向量相似性度量,如余弦相似性(参见Gerard Salton and Michael J. McGill, Introduction to Modern Information Retrieval, New York: McGraw-Hill Book Company, 1983, pp. 201-204)。
[51]彭定求等编:《全唐诗》卷13,第133页。
[52]Kevin A. Jensen, “Wei-Jin Sacrificial Ballets: Reform versus Conservation,” Ph.D. diss., University of Washington, 2012.
[53]刘煦:《旧唐书》卷31,北京:中华书局, 1986年,第1140页。
[54]四言诗通常会被与《诗经》联系在一起。《诗经》是中国现存最早的诗歌总集,也是儒家经典之一。虽然两汉以迄六朝的诗人仍有四言诗的创作,但到了唐代,更多诗人还是选择写作五、七言诗,四言诗仅间用于仪式场合,或用于体现复古追求,一些特定的正式场合也会用到四言诗( Zebulon David Raft, “Four-syllable Verse in Medieval China,” Ph.D. diss., Harvard University, 2007)。
[55]这也为MALLET原始分配的主题数值高于n值提供了正当的理由。主题数值设置得高, MALLET才会去具体文本中寻找不易识别的主题。具体文本中的溢余主题值得关注之处在于,在整体文献中明晰可见的主题落实到具体文本中有可能成为语义层面的”幽灵”。将n值降低很可能会将这些幽灵主题彻底驱逐干净。